目前,全球AI训练集群的主流互联技术无疑是Nvidia/Mellanox——即英伟达的算力与迈络思的IB(InfiniBand)打包而成的完整AI解决方案。
英伟达在AI和游戏显卡领域的霸主地位毋庸置疑。而IB,即InfiniBand(无限带宽技术),是一种比以太网更快、更低延迟、原生无损的专用高速网络,主要用于超算和AI集群。在大规模AI训练场景中,IB占据绝对主导地位——数千张GPU的集群中,90%会采用IB方案。

IB的性能堪称碾压级。其延迟仅约1μs(微秒),而以太网通常在2–5μs之间。1微秒即百万分之一秒,听起来差别不大,但在高性能计算领域却是天壤之别。
打个比方:GPU之间传输数据进行AI模型训练,IB的延迟就像你喊同桌递个笔,对方0.1秒就给你了;而以太网的延迟如同你喊隔了两排的同学递笔,对方得0.2-0.5秒才递过来。当GPU每秒需要传输数百上千次数据时,差距立即显现。
在万卡训练场景中,网络慢就意味着GPU空转,导致算力浪费,成本随之飙升。IB是唯一能将算力利用率拉到85%以上的技术——这不是选择题,而是必答题。
传统以太网传输数据时,必须让CPU先将数据从GPU取出、打包后再发送,接收方的CPU再拆包后交给GPU——这就像寄快递需要先找快递员上门取件、再送到对方手中。问题在于,快递员数量有限,快递量却可能无限,以有限应付无限,殆矣。快递员必然力不从心,而且CPU消耗极大。
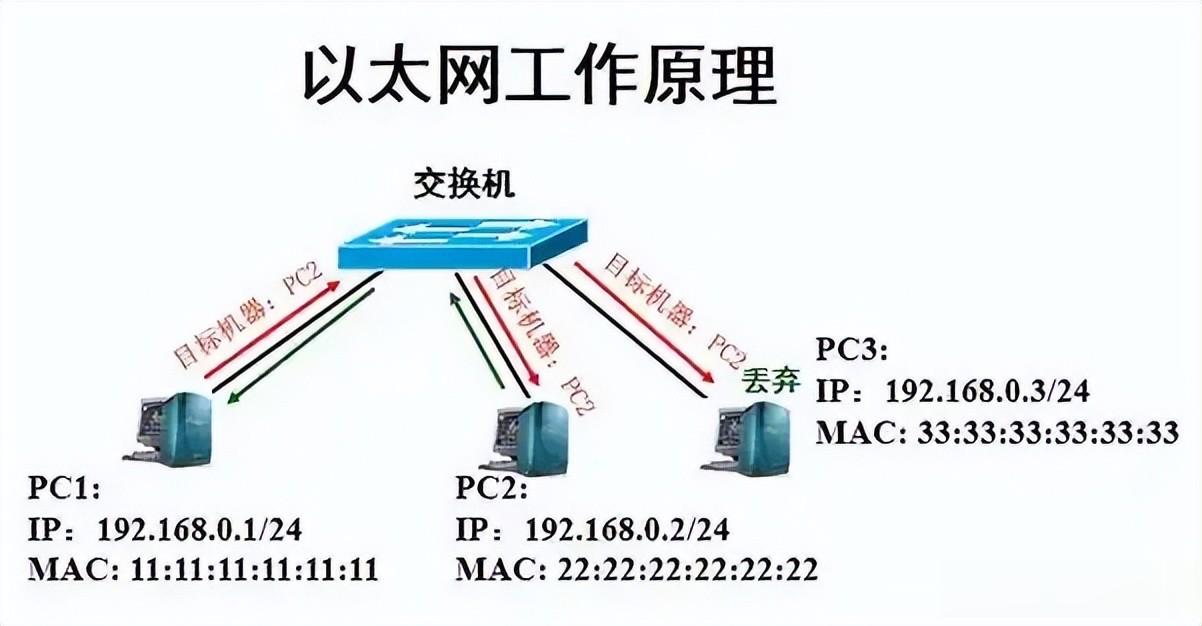
IB与传统以太网的核心区别在于采用了原生RDMA技术。RDMA(远程直接内存访问)支持零拷贝、内核旁路,传输逻辑是GPU直接与GPU传输数据,无需CPU介入——就像两人隔着窗户直接递东西,省去了中间跑腿的环节,既快速又不消耗CPU算力。这让IB技术完美解决了大规模集群的雪崩式崩溃问题。
仍以快递为例:普通以太网的数据传输需要交给CPU这位"快递员",数据一多时,快递员可能忙不过来导致错乱,这就是所谓的"丢包",丢了就必须重发,丢包多了就会严重耽误时间。
IB则像是一条专用赛道,拥有专门的交通管制体系,能保证所有数据包顺利送达,既不会丢包也不会拥堵,数据传输100%可靠。在AI训练这种容不得半点差错的场景中,这种可靠性有多宝贵,不言而喻。
极低延迟、直接读写远端内存、天生不丢包,再加上高带宽持续迭代——这些优势使IB成为当前算力基础设施的完美解决方案。
作为一条商业化时间并不算长的赛道,IB的带宽将持续升级,目前每两年翻一倍,以匹配GPU算力的增长。展望未来3–5年,通过技术迭代、规模扩张和生态完善,IB有望实现全面普及。
从全球市场空间来看,2025年约257亿美元,2026年预计达351亿美元,CAGR高达36.6%。到2030–2031年将攀升至1270–1644亿美元,CAGR维持在36–38%之间,增长空间极为可观。
**中国市场的表现同样亮眼。**2025年约为40–50亿美元,2030年将达到200亿美元,CAGR在32–38%之间,增速与全球持平。但中国IB行业基数小、国产替代空间大、政策扶持力度强,个股业绩弹性远高于全球水平。这恰恰意味着更大的机会。
短期来看,我国IB在1–2年内将迎来刚需爆发,国产替代的拐点将至。
**为什么说刚需?**因为万卡集群是AI训练的标配,达不到这个水平,AI训练效果将大打折扣。IB是集群通信的底座,万卡训练缺IB就等于GPU空转,算力基本报废——这是典型的"卡脖子"技术,所以美国优先掐断。英伟达IB于2022年底起对华实施硬禁运,永久断供,不再接受新订单、不续约、不提供技术支持,完全没有回旋余地,这一刀,砍得干脆利落。
直至今日,我国仍无法购买到新的原厂IB设备。国内仅有存量旧卡和二手卡可以继续运行,但无法扩容、无法升级、更没有官方维保。这迫使中国走上华山一条路:加速国产替代。
而且我们的国产替代绝非低端替代,而是平替,甚至在某些领域实现了对美国技术的超越。
2026年3月12日,中科曙光发布ScaleFabric 400G全栈自研原生IB,标志着国产原生IB正式对标英伟达NDR。更令人振奋的是,曙光的单子网规模高达11.4万卡,远超英伟达的4.9万卡,已实现完美反超。这一数字,足以让世界重新审视中国的高性能网络技术。

除曙光外,华为已实现IB产品自用,紫光和中兴也已跟进——可以说,IB技术已卡不住我们了。美国那一刀看似凶狠,却倒逼出更强劲的突破。
美国禁运英伟达IB后,国内大模型企业曾一度苦于5万卡以上集群没有解决方案。如今ScaleFabric直接提供11.4万卡的单子网,十万卡级国产AI集群终于成为可能。这不是简单的追赶,而是实实在在的超越。
H200于2024年被禁售。虽然2026年美国名义上放行H200对华出口,但中国又让进了。黄仁勋和美国商务部公开承认:H200对华一块没卖。这既解气,也释放出明确信号——告诉国内AI大厂:放弃幻想,全面拥抱国产。这种"说禁就禁,说放就放"的随意性,反倒让中国企业彻底断了念想,一心扑在自主创新上。
这足以说明,无论是IB还是GPU,我国国产替代的道路已经走通,而且走得越来越稳。
**从概念龙头来看,第一梯队无疑是中科曙光。**它是目前国产原生IB(ScaleFabric)唯一量产商用的龙头。11.4万卡单子网远超英伟达,0.9μs时延也优于英伟达,80口×400G交换机同样领先对手,256单卡QP直接是英伟达的两倍,而成本比进口IB低了30%。这些数据摆在桌面上,答案不言自明。
当然,以美国为信仰的人除外。

财务数据方面,中科曙光2025年营收149.64亿元,同比增长13.81%;归母净利润21.76亿元,增长13.87%,利润与营收增速基本持平,显示盈利能力稳定。2026Q1营收31.99亿元,增长23.71%;归母净利润2.28亿元,增长22.19%,增速明显抬升。扣非净利润1.64亿元,增速高达53.30%,主业已呈现爆发之势——这正是国产替代红利兑现的信号。
机构预测,中科曙光2026年归母净利润在27–38亿元之间,增长25%–75%,中枢30亿元增长38%;2027年40–50亿元,增长30%–60%,中枢45亿元增长50%。增长空间已完全打开,就看企业能否抓住这一轮历史机遇。
不过中科曙光当前估值已不便宜——毕竟是一只两年翻5倍的股票,存在消化估值的需求。但近期似乎已站稳半年线,可以考虑重点关注。对于看好国产替代长期逻辑的投资者而言,或许不必太在意短期波动。
除中科曙光外,第二梯队的紫光股份、中兴通讯和海光信息同样值得关注。紫光股份的400G RoCEv2原生IB样品(80口400G交换机),自研交换芯片计划今年四季度小规模试点;中兴的自研DPU+400G RDMA网卡已流片,预计2027年商用;海光深度绑定中科曙光,是唯一深度适配ScaleFabric的公司——这些企业正在形成合力,共同构建国产IB生态。
产业链配套还包括光模块、网卡加速卡、液冷等领域,因篇幅所限不再展开。总而言之,目前我国IB领域已不惧封锁,中科曙光等行业龙头业绩即将迎来高速增长。从"卡脖子"到"反超",这条路走得不容易,但走得越来越稳。
这是一场长期战役,而非一蹴而就的短跑。
(图片来自网络,侵权联删)