[LG]《Emergent Alignment via Competition》N Collina, S Goel, A Roth, E Ryu... [University of Pennsylvania] (2025)
AI对齐难题并非无解,竞争机制下的多模态AI协作展现出意想不到的优势。
• 核心假设:用户的效用函数近似位于多个AI代理效用函数的凸包内,且随着多样化模型的增多,这一假设更易满足。
• 模型创新:将多模态AI互动建模为多领导者Stackelberg博弈,扩展了贝叶斯说服理论至多轮、多信息来源的对话场景。
• 关键结论:
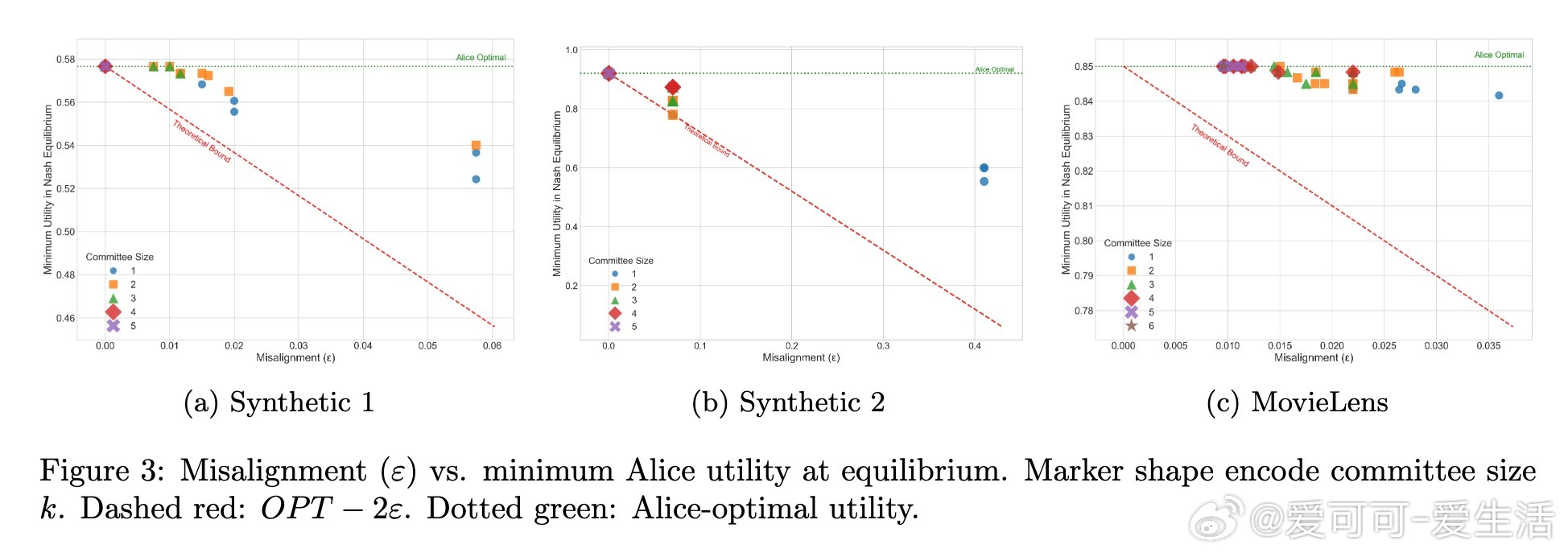
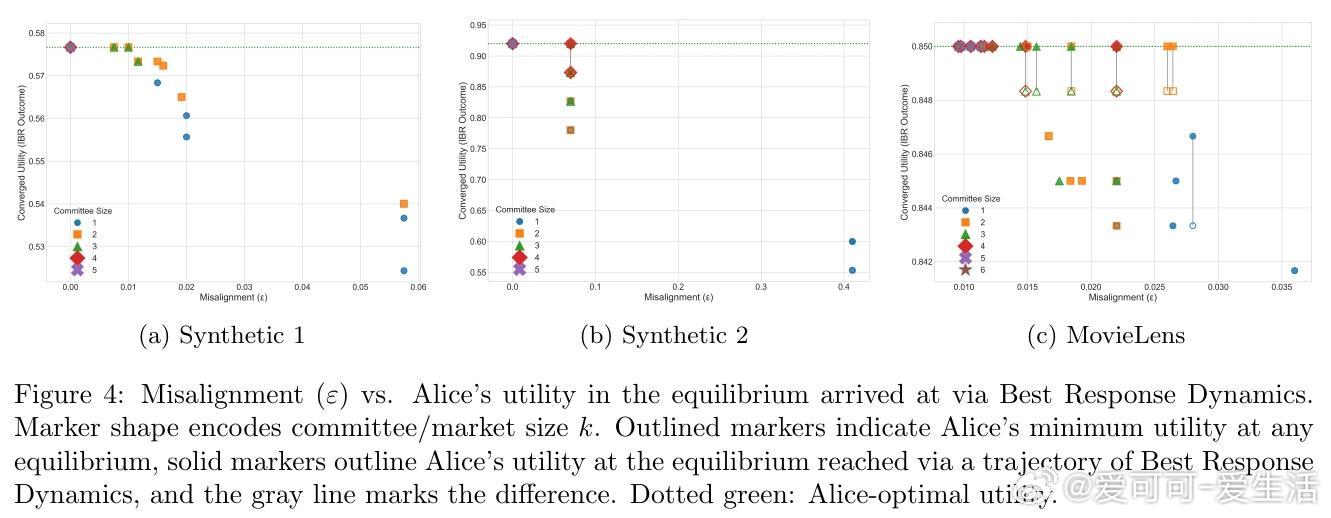
- 在理想条件下(信息完全且模型可使用户学得贝叶斯最优行为),竞争导致所有纳什均衡都接近最优用户效用;
- 放宽假设,用户采用“量化响应”(quantal response)模型时,即使近似学习行动效用,依然保证近似最优;
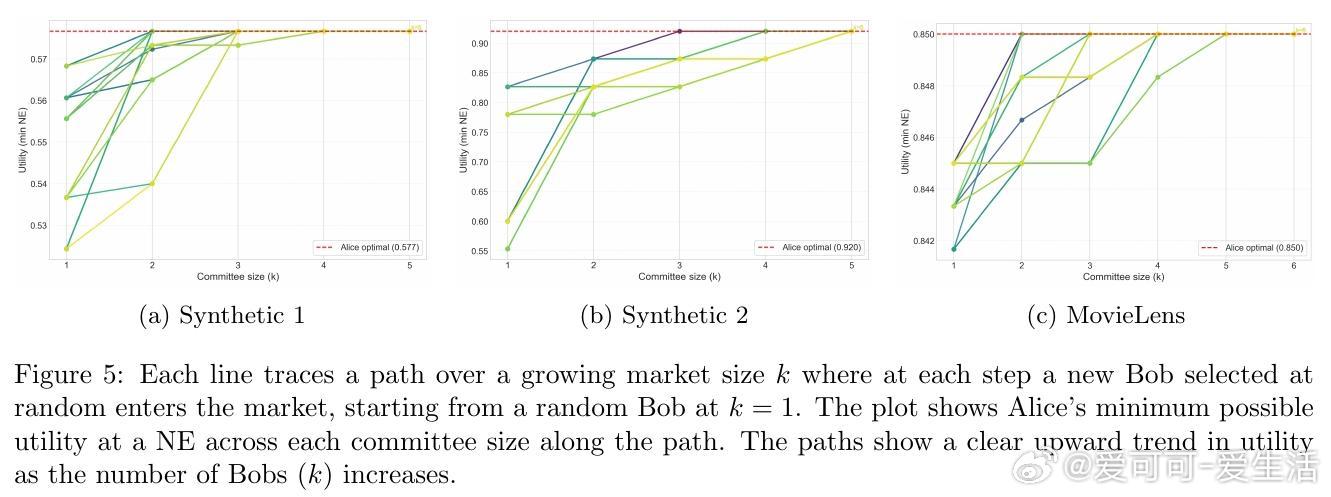
- 通过“最佳AI选择”机制,无需额外分布假设,用户与单一选择的模型交互也可获得近优效用。
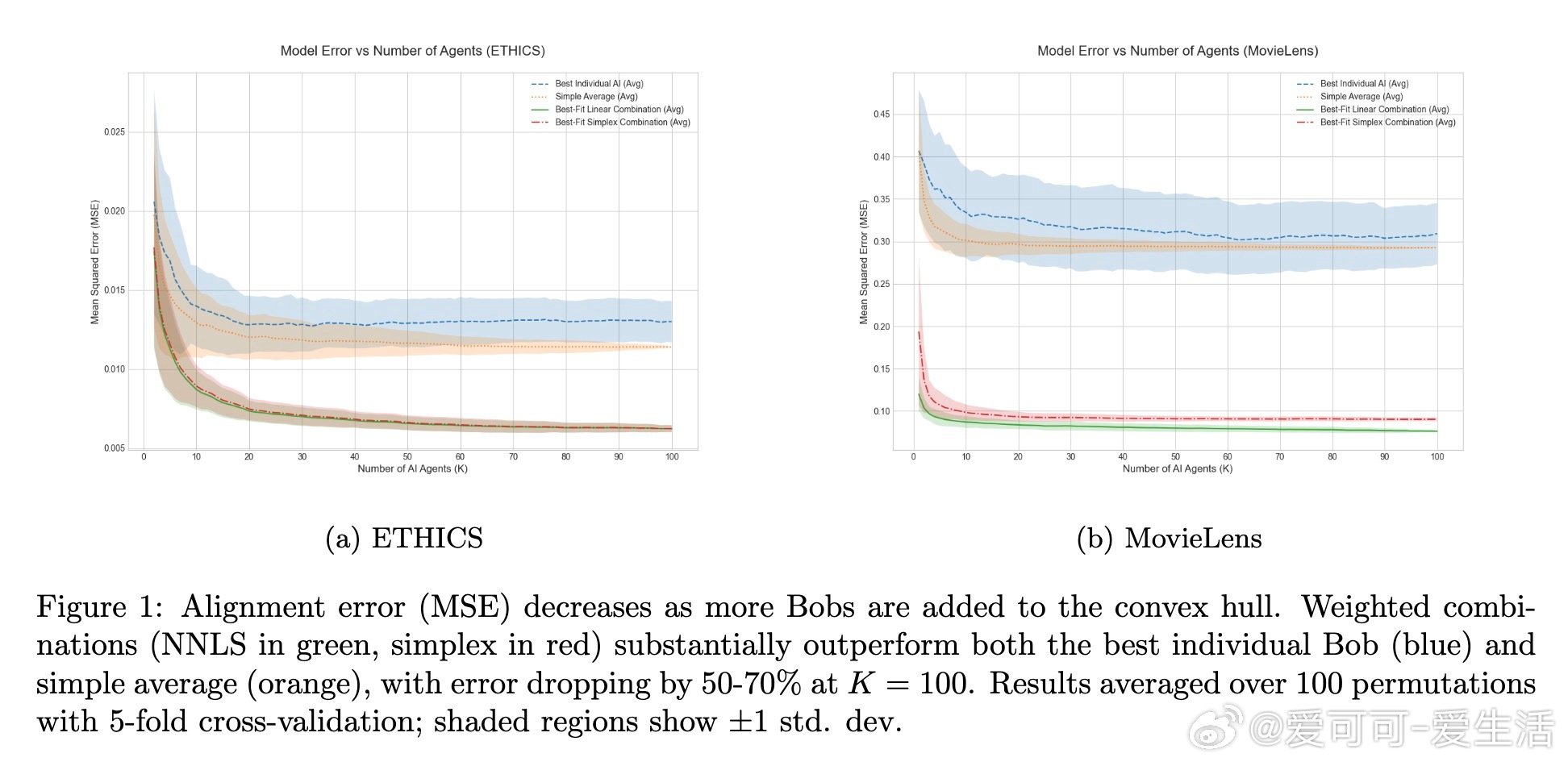
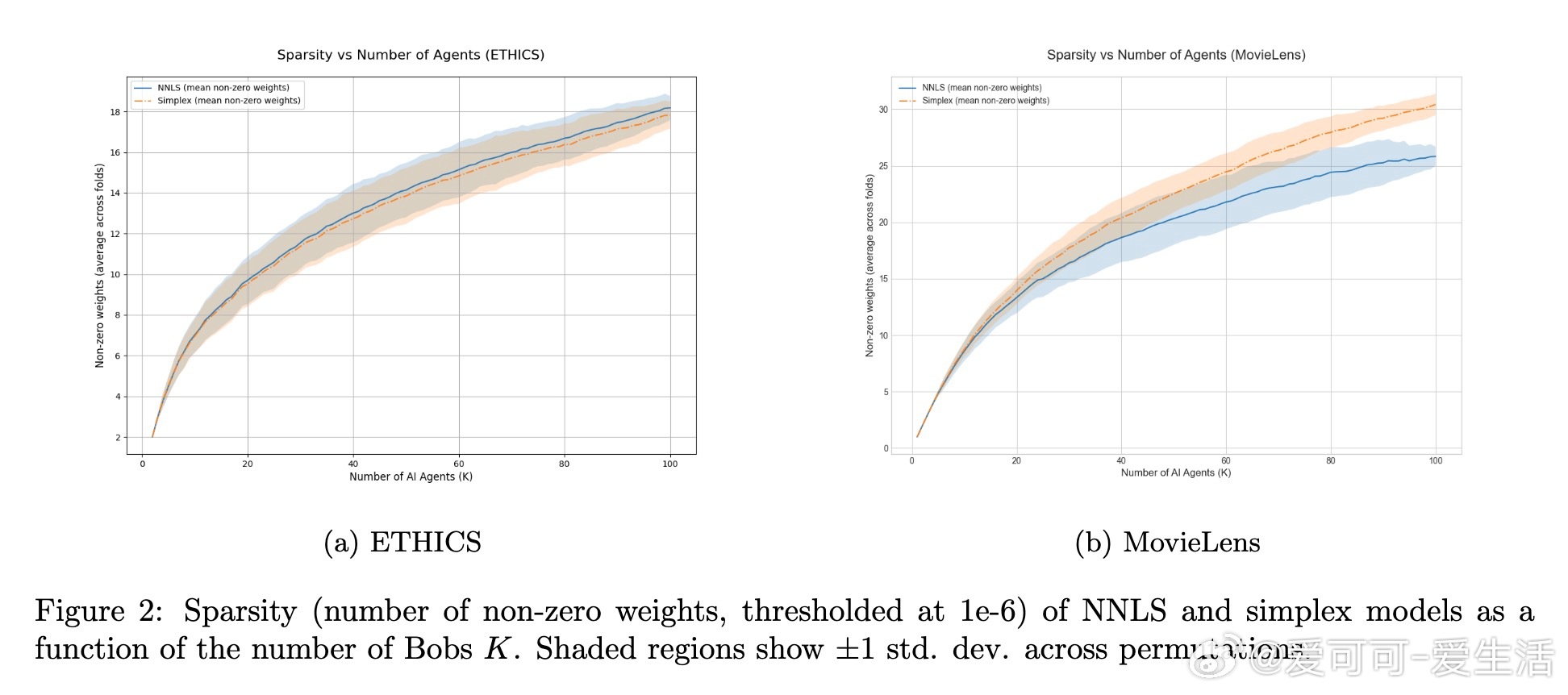
• 实证验证:基于ETHICS伦理判断和MovieLens电影评分数据,利用多样化语言模型变体构建AI效用函数,发现凸包内组合显著优于任一单个模型,且简单平均法效果不佳。
• 竞价动态模拟表明,增加AI模型数量提升用户效用,且误差指标可预测对齐效果。
• 本质启发:
1. 多样性和竞争是克服单一模型对齐困难的有效路径,凸包覆盖提供了“组合对齐”的新视角。
2. 用户的有限理性(如量化响应)并非障碍,合理机制设计可引导多模型协同产生近似最优结果。
3. 市场机制中AI模型的战略互动远超传统合作或对抗设定,呈现更丰富的对齐动力学。
• 未来方向:设计更鲁棒的对话协议以适应动态、非承诺式AI,扩展至多用户多目标环境,探索监管与激励机制促进多模型对齐。
详细解析🔗 arxiv.org/abs/2509.15090
人工智能AI对齐博弈论贝叶斯说服多模态交互量化响应机制设计