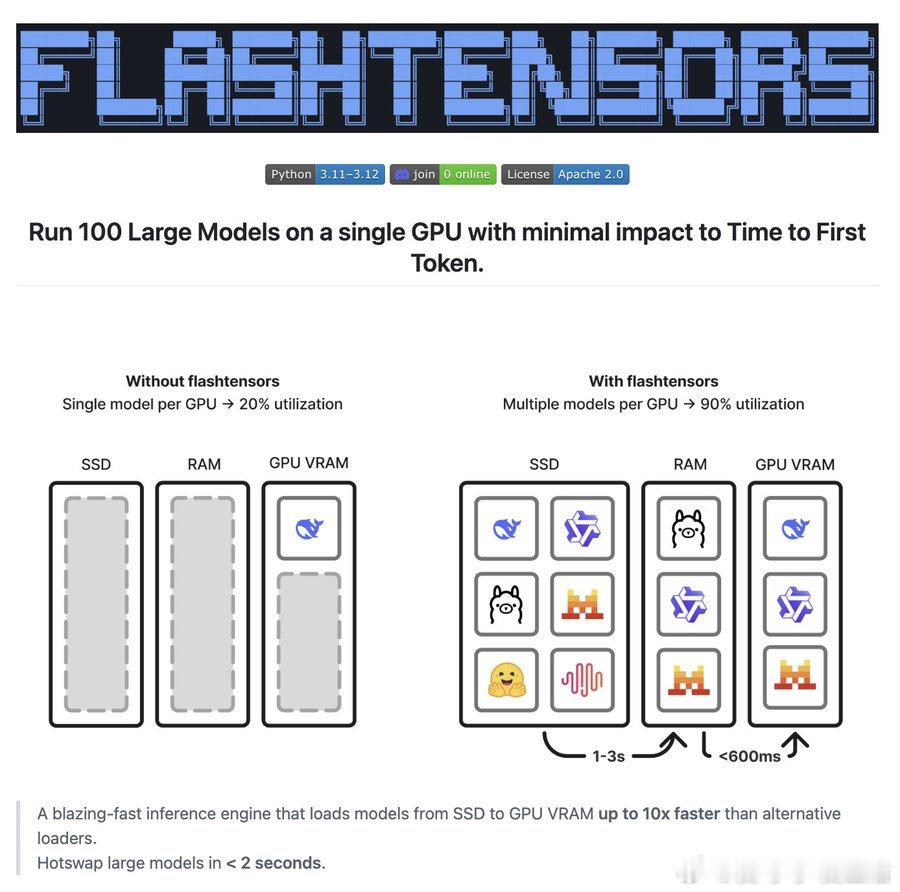
Unwind AI 推出 flashtensors,支持在单张GPU上运行100个大型模型,加载速度比传统方法快10倍,冷启动时间不足2秒,彻底突破GPU利用率瓶颈。这是开源界对模型多样性和效率需求的有力回应。
主要应用场景包括:
- 个性化AI:为不同用户加载专属微调模型
- 多任务智能代理:按需切换专用模型,提升灵活性
- 无服务器平台:按需调用,避免长时间加载大模型浪费资源
这项技术不仅极大提升了GPU的效率,还为边缘计算和个性化AI部署打开了新天地。flashtensors如同给硬件注入了“咖啡因”,让模型加载速度快到令人惊讶。
这背后是开源精神的力量,也是AI多样化发展趋势的体现。想了解更多开源AI工具和教程,访问theunwindai.com免费获取资源。
技术变革正在加速,如何高效利用有限硬件资源,成为AI应用落地的关键。flashtensors让“多模型共存”不再是梦想,而是现实。
链接:github.com/leoheuler/flashtensors