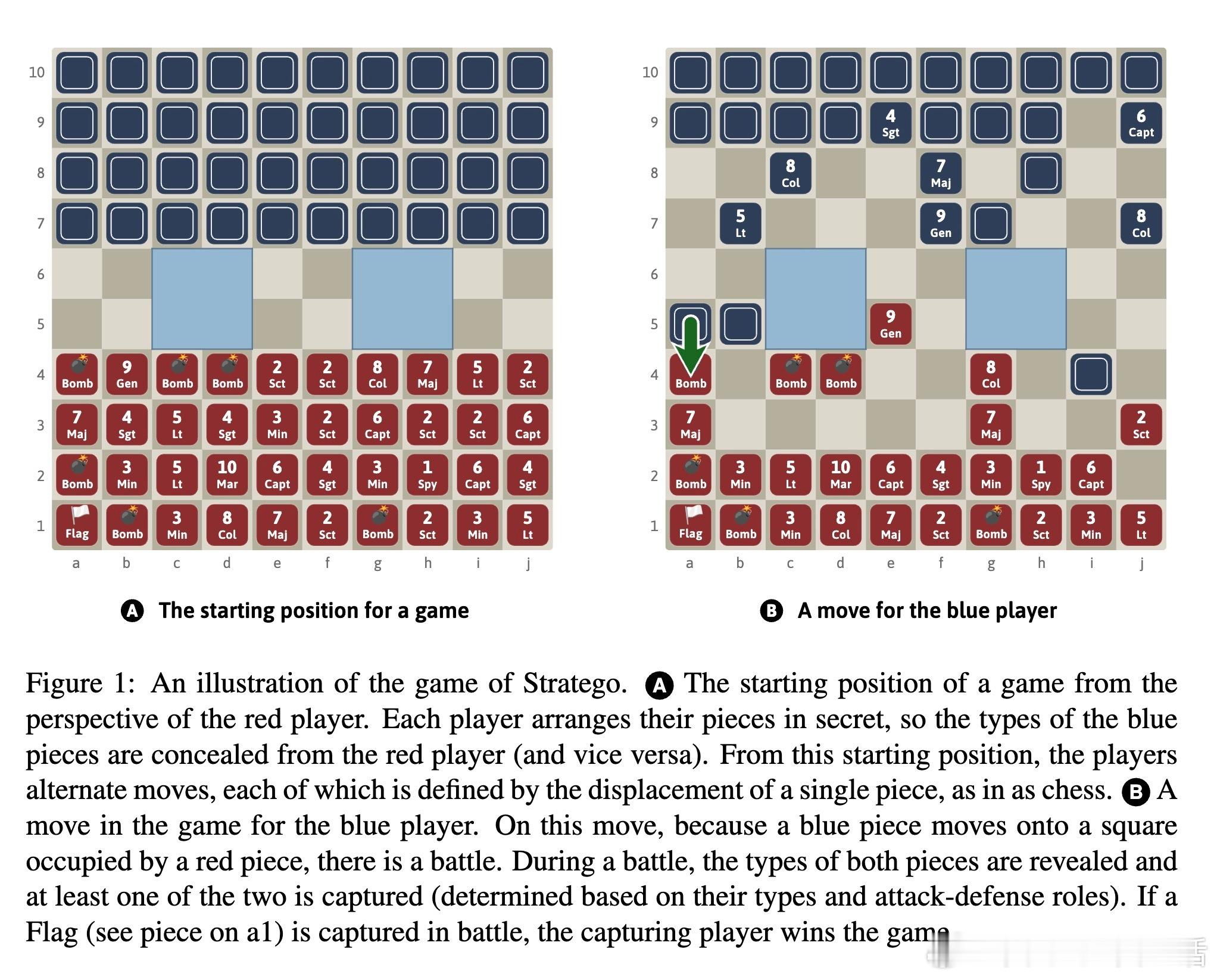
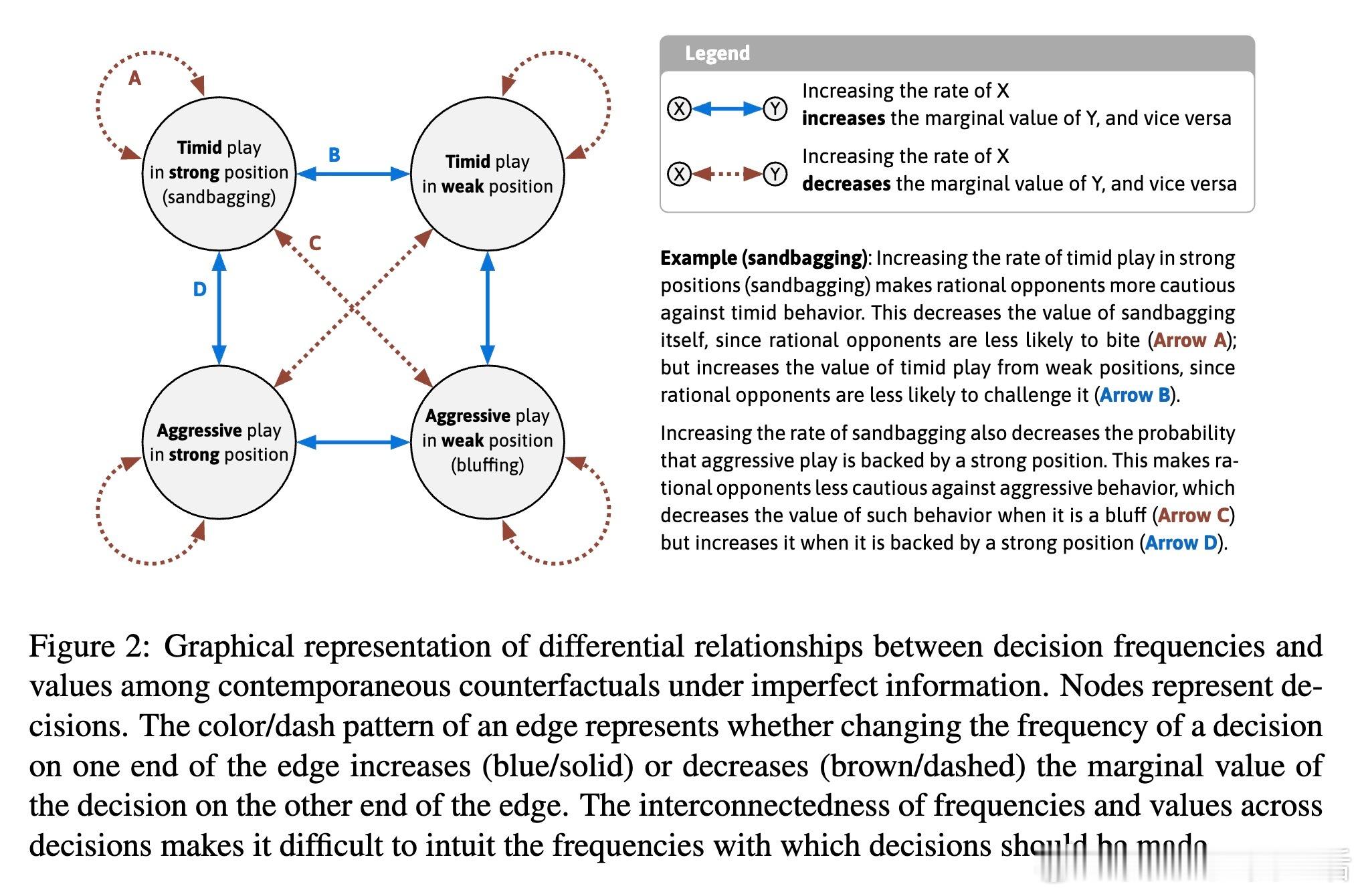
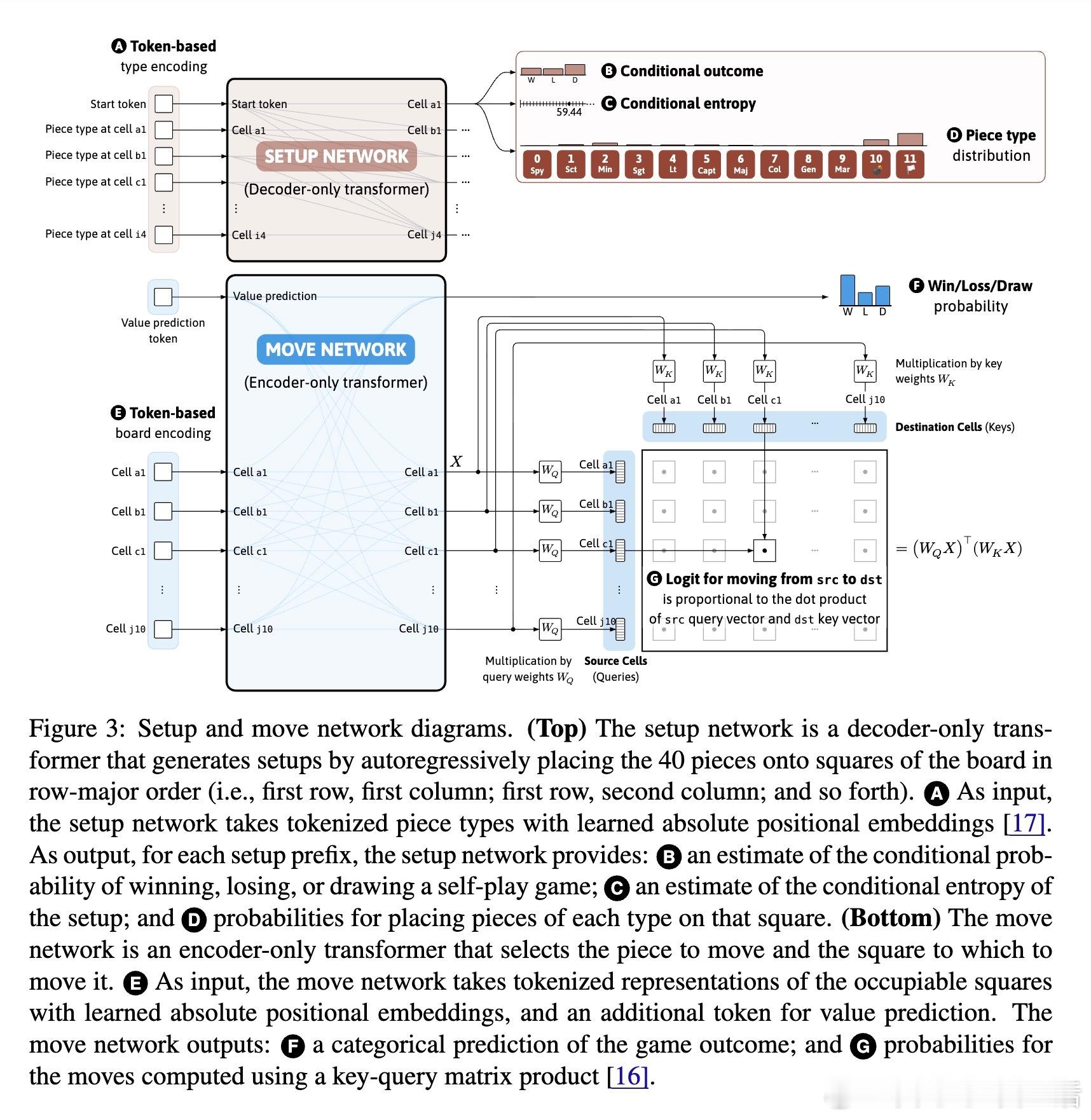
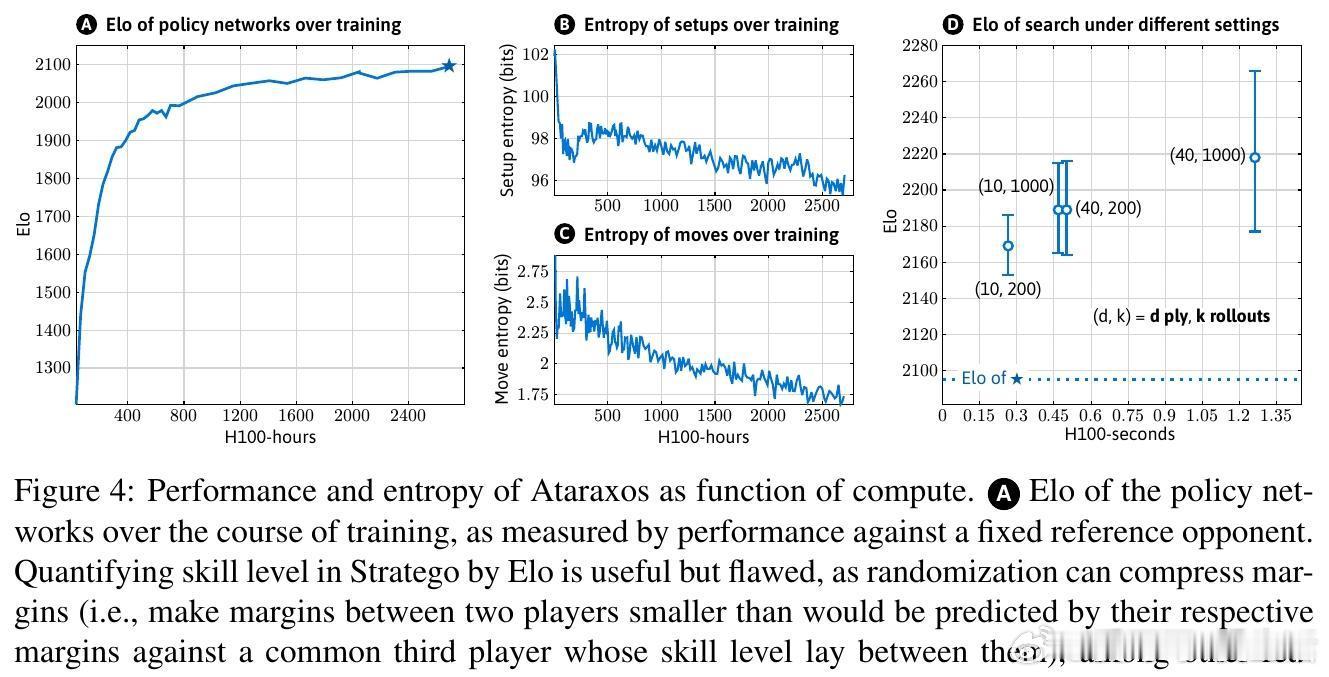
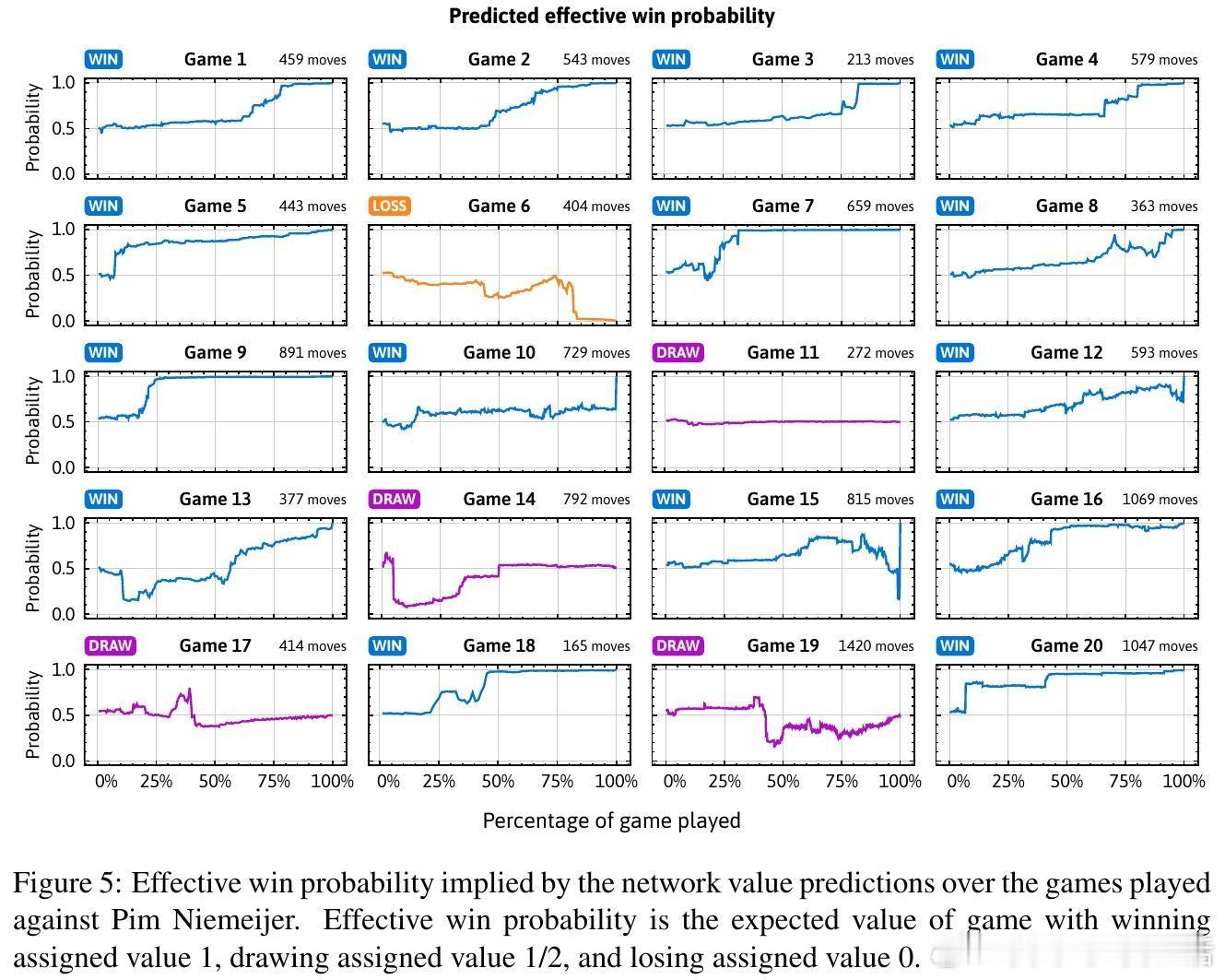
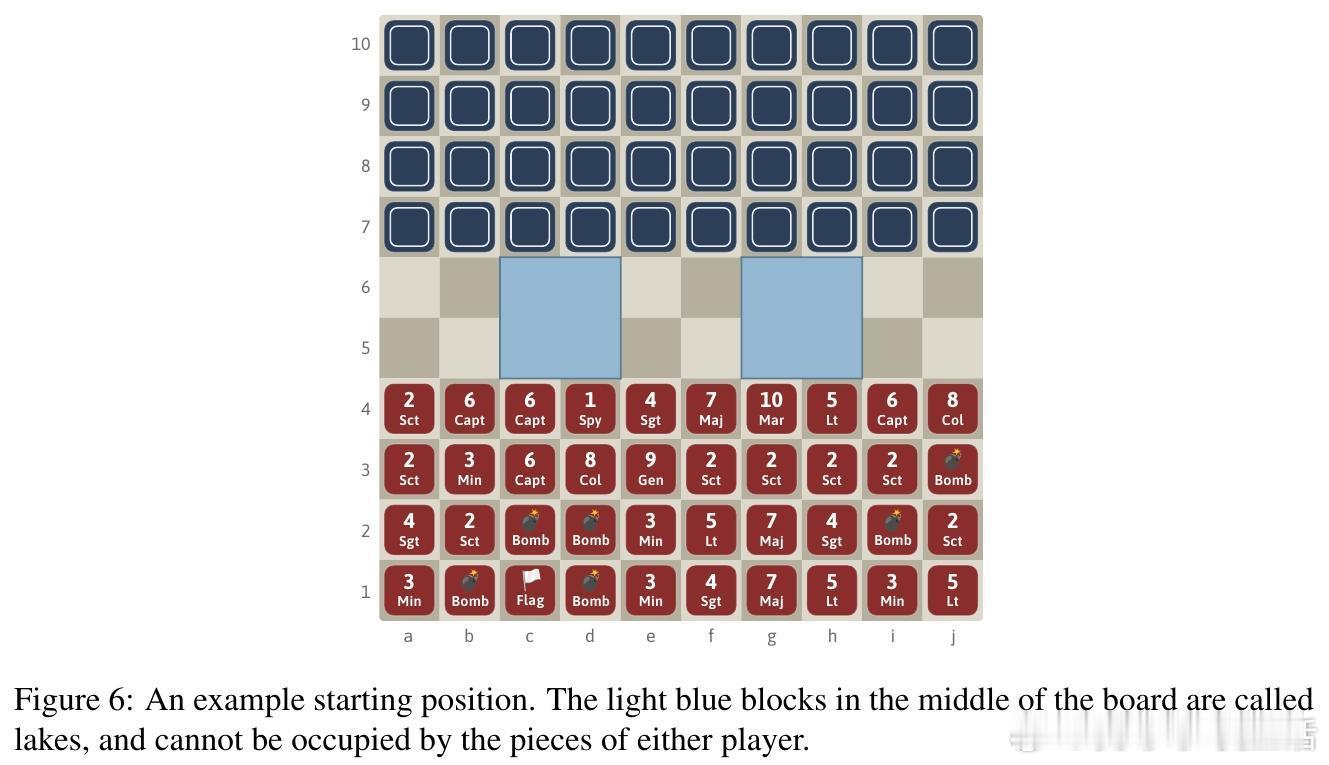
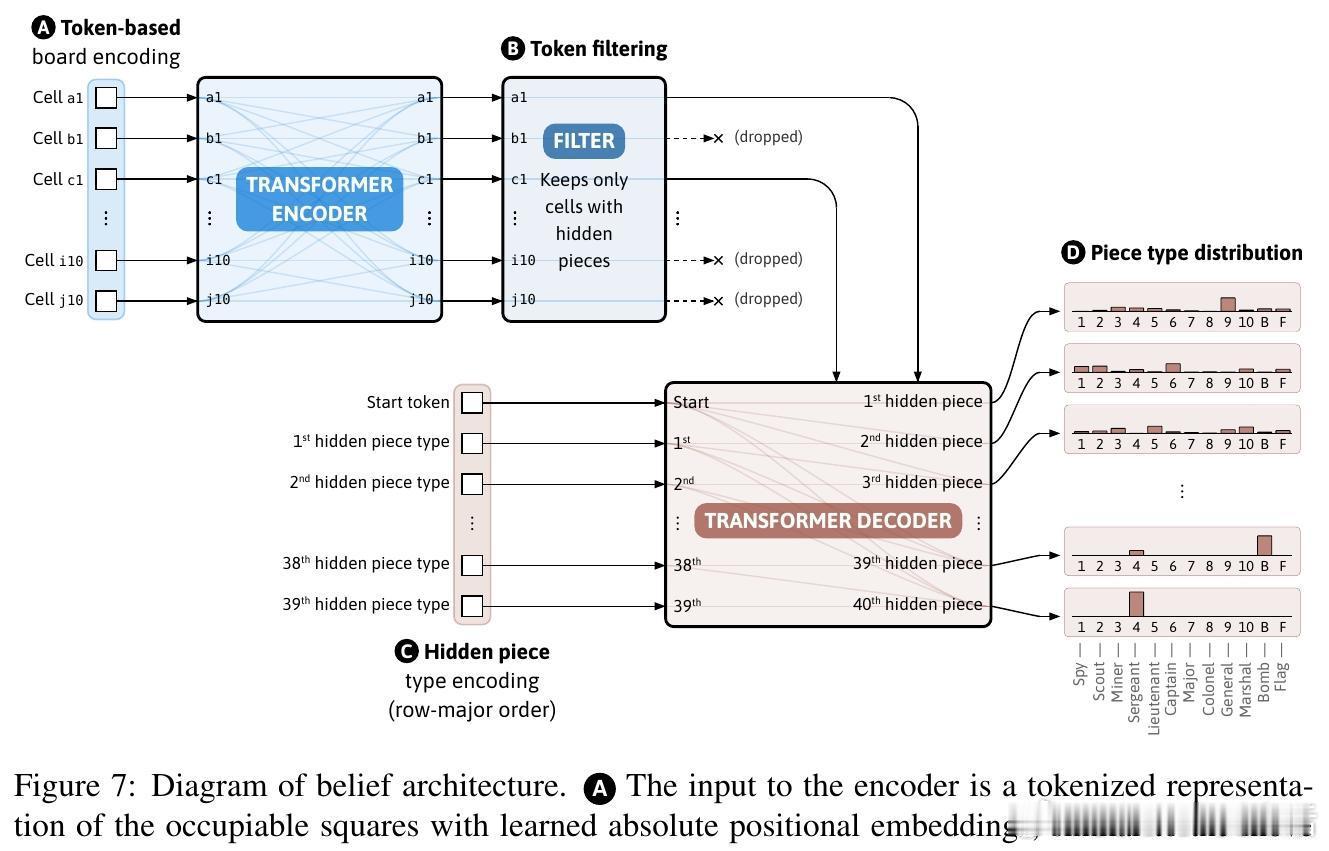
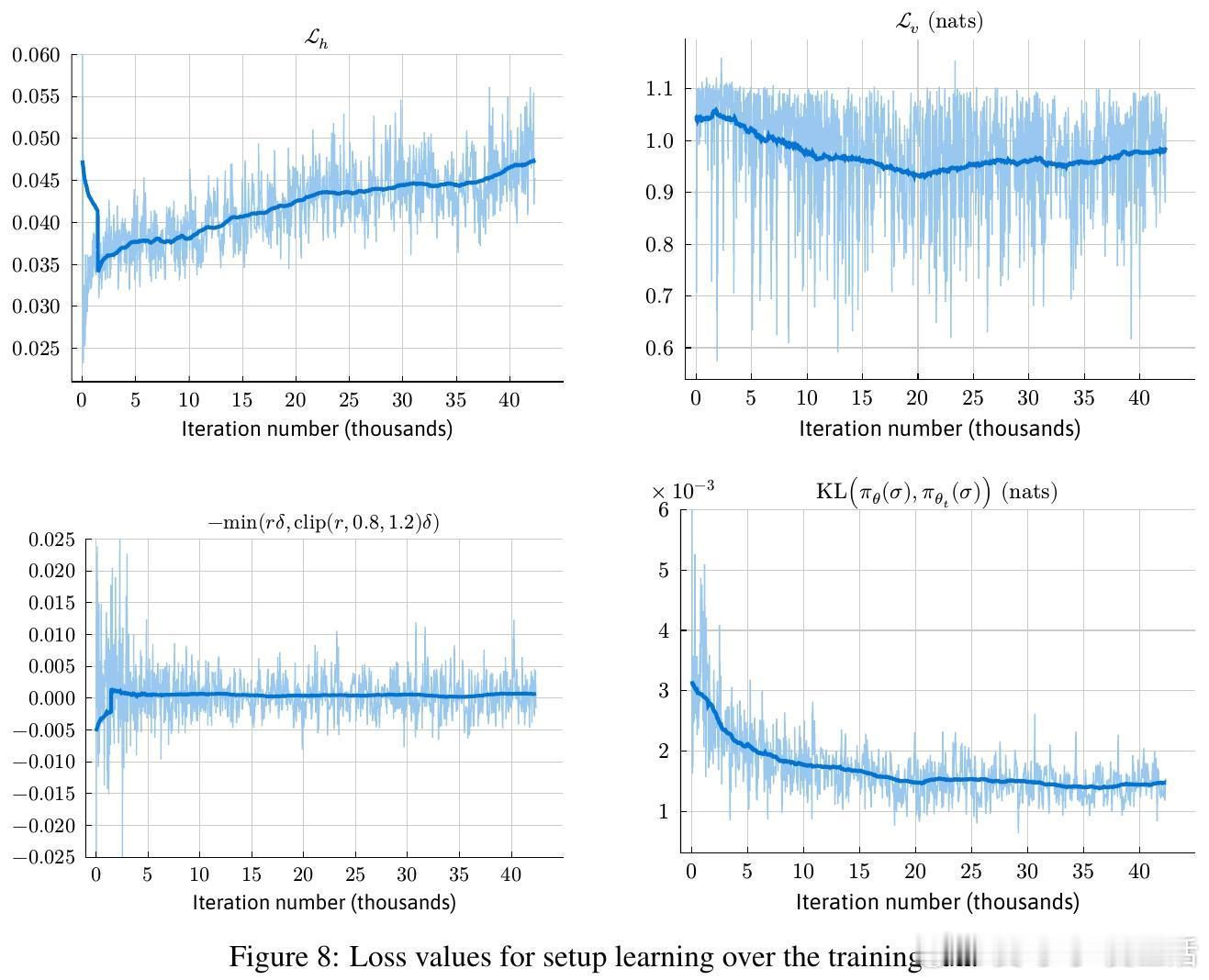
[LG]《Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search》S Sokota, E Vinitsky, H Hu, J. Z Kolter... [CMU & NYU Tandon School of Engineering & Stanford University] (2025) 少有经典游戏能像Stratego这样,成为人工智能战略决策领域的标杆。Stratego的巨大隐藏信息量让传统AI训练耗资千万美元却难以超越顶尖人类玩家。而最新研究成果Ataraxos打破了这一瓶颈:通过自我对弈强化学习与测试时搜索,花费仅数千美元,便实现了超越人类顶尖高手的超神表现。Ataraxos采用了两个关键创新——分别对应游戏的布阵阶段和移动阶段的自我对弈过程,利用Transformer架构进行策略和价值预测。训练中通过动态调节正则化强度和策略更新幅度,稳定且高效地推进学习,避免了信息不完美带来的学习震荡。在2025年7月的20局对抗赛中,Ataraxos以15胜4和1负的悬殊战绩击败被誉为“史上最强玩家”的Pim Niemeijer。且在2025年8月世界锦标赛现场40局演示中,胜率高达95%。该AI不仅下法更难预测,更善于长远布局和利用信息优势,展现出“近乎幸运”的战斗直觉和大胆策略。技术上,Ataraxos突破了隐藏信息过多下传统强化学习和搜索难以应用的限制。它训练与推理全程GPU加速,避免大量CPU-GPU数据传输,整合蒙特卡洛回报与优势过滤,利用信念网络估计对手隐藏棋子分布,实现了高效的测试时搜索,提升决策质量。与此前DeepMind的DeepNash相比,Ataraxos训练成本低百万倍(数千美元vs数百万美元),且在顶级人类对局中取得压倒性优势。此结果表明,利用合理算法设计和现代硬件,复杂的不完备信息战略决策问题已不再遥不可及,AI在金融、军事、谈判等领域的应用潜力巨大。这项工作不仅刷新了Stratego的AI水平,也为广泛的不完备信息环境下智能决策树立了新的里程碑。未来,可通过引入时序注意力、递归模型及更深度的子博弈搜索,进一步推动其性能极限。详细论文请见 arxiv.org/abs/2511.07312v1—— 战略游戏的隐藏信息不再是AI的绊脚石,而是通往超越人类智慧的桥梁。