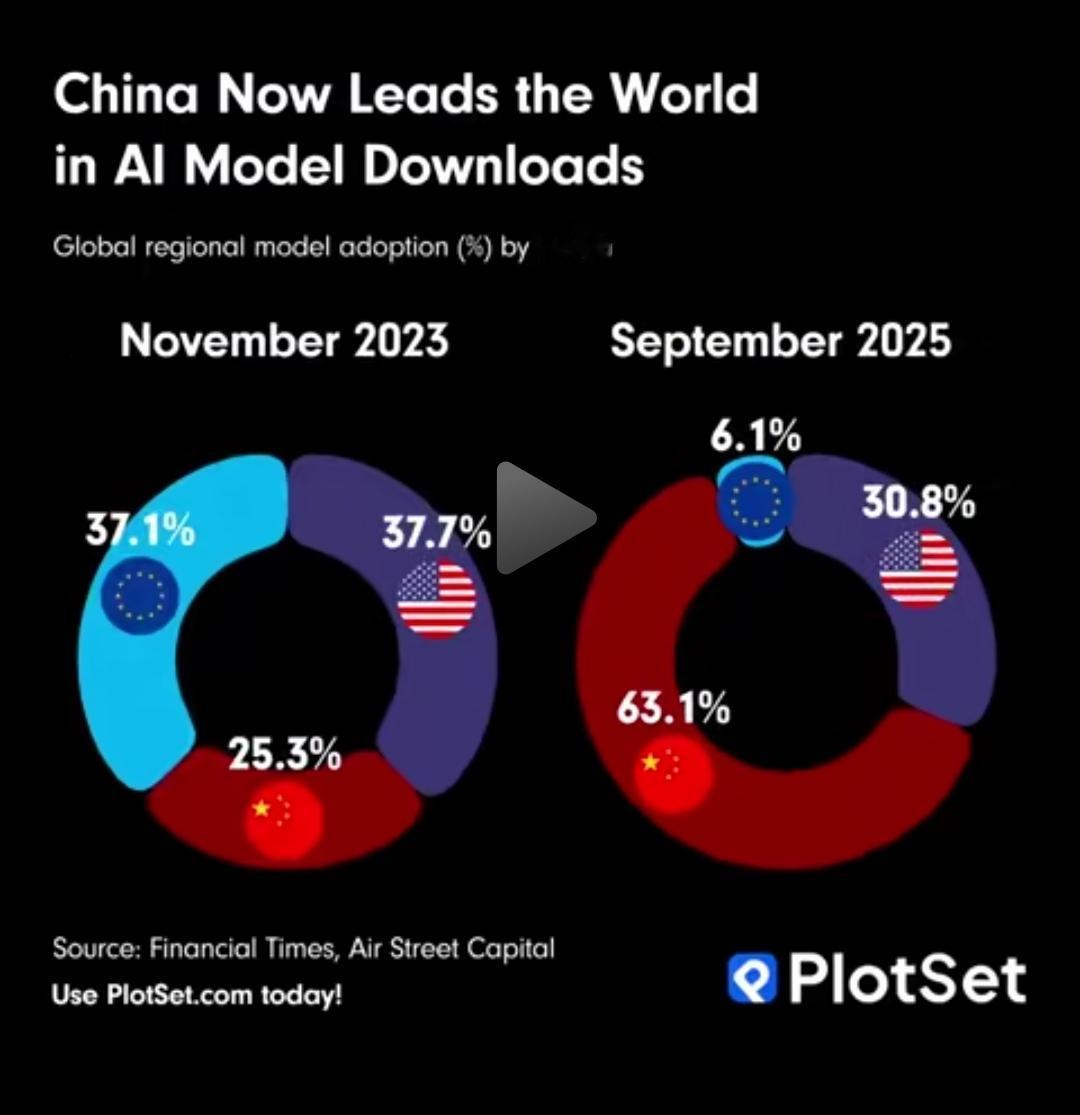
“中美差距究竟有多大?”DeepSeek创始人梁文峰再次语出惊人!他说:“我们经常说中国AI和美国有一两年差距,但真实的差距是原创和模仿之差。如果这个不改变,中国永远只能是追随者,所以有些探索也是逃不掉的。” 人工智能赛场,中美两强过招,谁能笑到最后?DeepSeek掌门人梁文峰一语道破天机:中国AI看似落后一两年,骨子里却是原创与模仿的拉锯。如果不直面这道坎儿,追随者角色何时能甩掉? 中美在AI这盘棋上,到底差哪儿了?不是简单的时间差,而是深层的路子问题。DeepSeek创始人梁文峰在2025年1月的一次访谈里,直戳痛点。这话一出,圈里圈外都炸了锅。大家平时总安慰自己,说中国AI就差那么一两年,追得上。可梁文峰不这么看,他说,真正的问题是原创和模仿的区别。要是不变,中国就只能老跟在后头,有些路子必须硬着头皮往前探。 梁文峰这番话,不是凭空而来。DeepSeek这家公司,从2023年5月起步,就在芯片卡脖子的环境下,硬是杀出一条血路。2024年1月,他们先推DeepSeek-MoE模型,基础版和聊天版齐上阵。接着4月3日,DeepSeek-Math系列亮相,专攻数学推理。6月18日,DeepSeek-Coder-V2开源,瞄准编程任务。9月5日,V2.5版迭代,性能再上台阶。11月20日,R1-Lite预览版出炉,带点推理能力。12月,V3大模型登场,671亿参数,上下文窗口128K tokens,多任务一把抓。2025年1月15日,DeepSeek APP上线,1月20日正版R1跟进,5月又升级R1-0528。9月29日,V3.2-Exp实验版新鲜出炉。这些步子稳扎稳打,让DeepSeek从跟跑到并跑,成本还低到让老美眼红。 话说回来,美国那边,早早占了先机。2022年11月,OpenAI的ChatGPT一炮走红,谷歌这些巨头砸钱如流水,从Transformer架构到强化学习,全是自家趟出来的坑。中国呢?论文数量2024年超美国,全球四成出自国内。可高影响力生成式AI论文,前十里美国占一半,中国就一席。计算机视觉领域,中国论文多出美国40%,自动驾驶、工业检测落地快。但基础研究上,美国高校企业联手,斯坦福、MIT这些地方,资金链顺溜,转化率高。中国多靠学术机构,跨界还得加把劲。 梁文峰的访谈,就在2025年1月底。采访里,他点明,中国AI不能总做跟班。出口管制让英伟达H100成稀缺货,可中国团队绕道走,用老办法的几分之一算力训模型。DeepSeek的混合专家架构、动态路由这些招儿,就是原创的火花。2023年11月,01.AI的Yi-34B模型基于Llama二次开发,发布会后社区质疑相似度高。团队承认调整开源框架,这事儿虽快见效,但也暴露短板。DeepSeek避开这坑,自家数据集训练,Nature杂志2025年9月发文,详解30万美元训出颠覆者。 这差距,说白了是根基的事儿。美国像探险家,开辟无人区。中国跑得快,但路是别人铺的。人才上,中国AI从业者年增28.7%,中科院、清华这些国家队,源源不断出精英。可缺口500万,复合型高手少。政策上,“人工智能+”行动给力,税收优惠、算力补贴一揽子来,企业腰杆硬了。华为昇腾910B 2023年投产,2025年4月910C批量出,性能赶上H100六成,自家说了算。 DeepSeek的API定价,只OpenAI三分之一,2025年1月上线,用户秒级响应,模型从高端玩意儿变平价货。市场这股劲儿,反过来推技术迭代。杭州孵化器里,年轻人接入接口,测试原型。工业现场,AI视觉系统上线,产量升15%。这些落地,接地气,说明中国在应用上玩出花样。 展望前头,中美双强并立,全球共治。中国凭政策指引、人才储备,在某些赛道领跑。原创力这双跑鞋,减震好,跑得稳。梁文峰提醒,不是唱衰,是鞭策。 MCN双量进阶计划