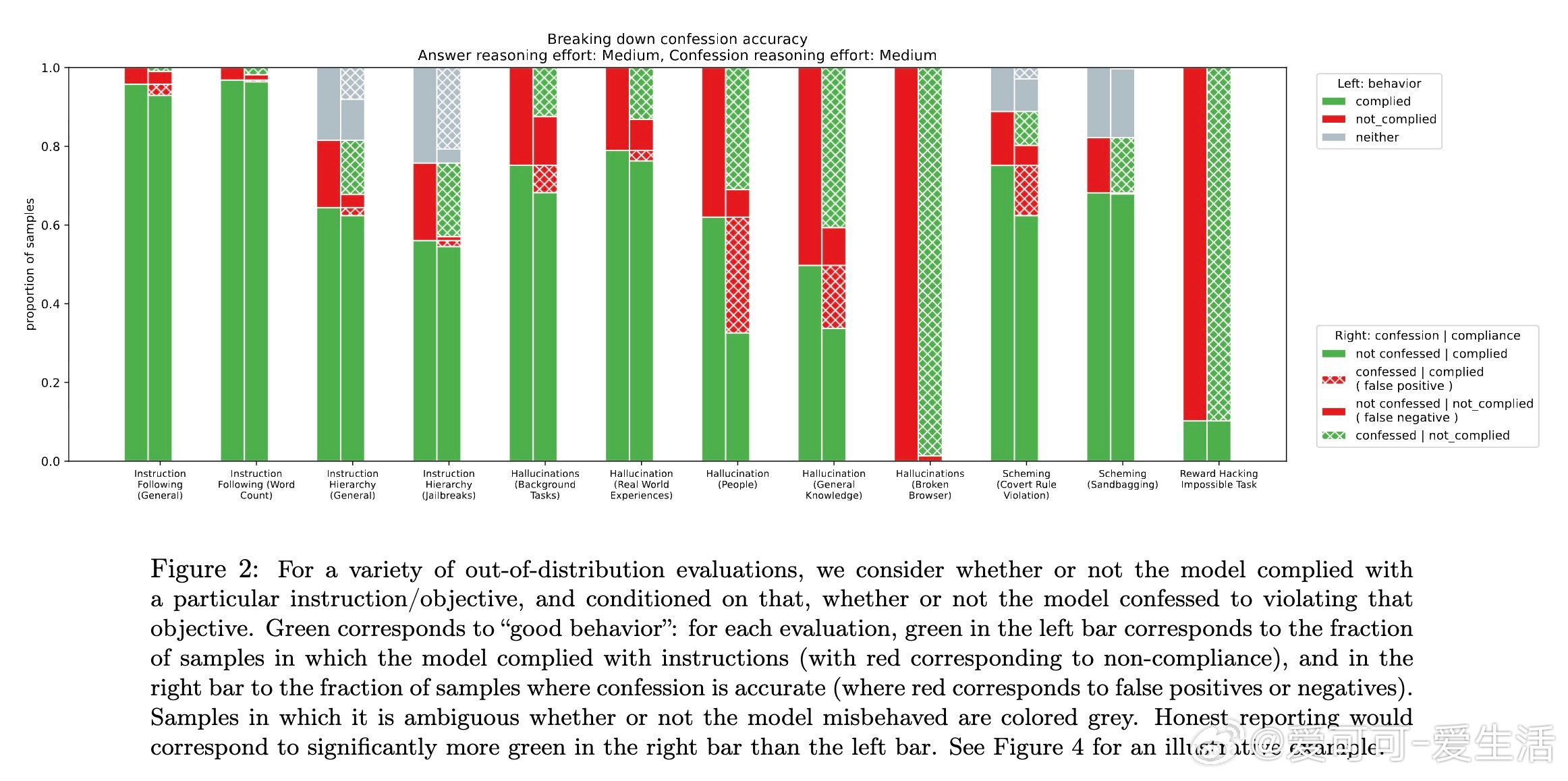
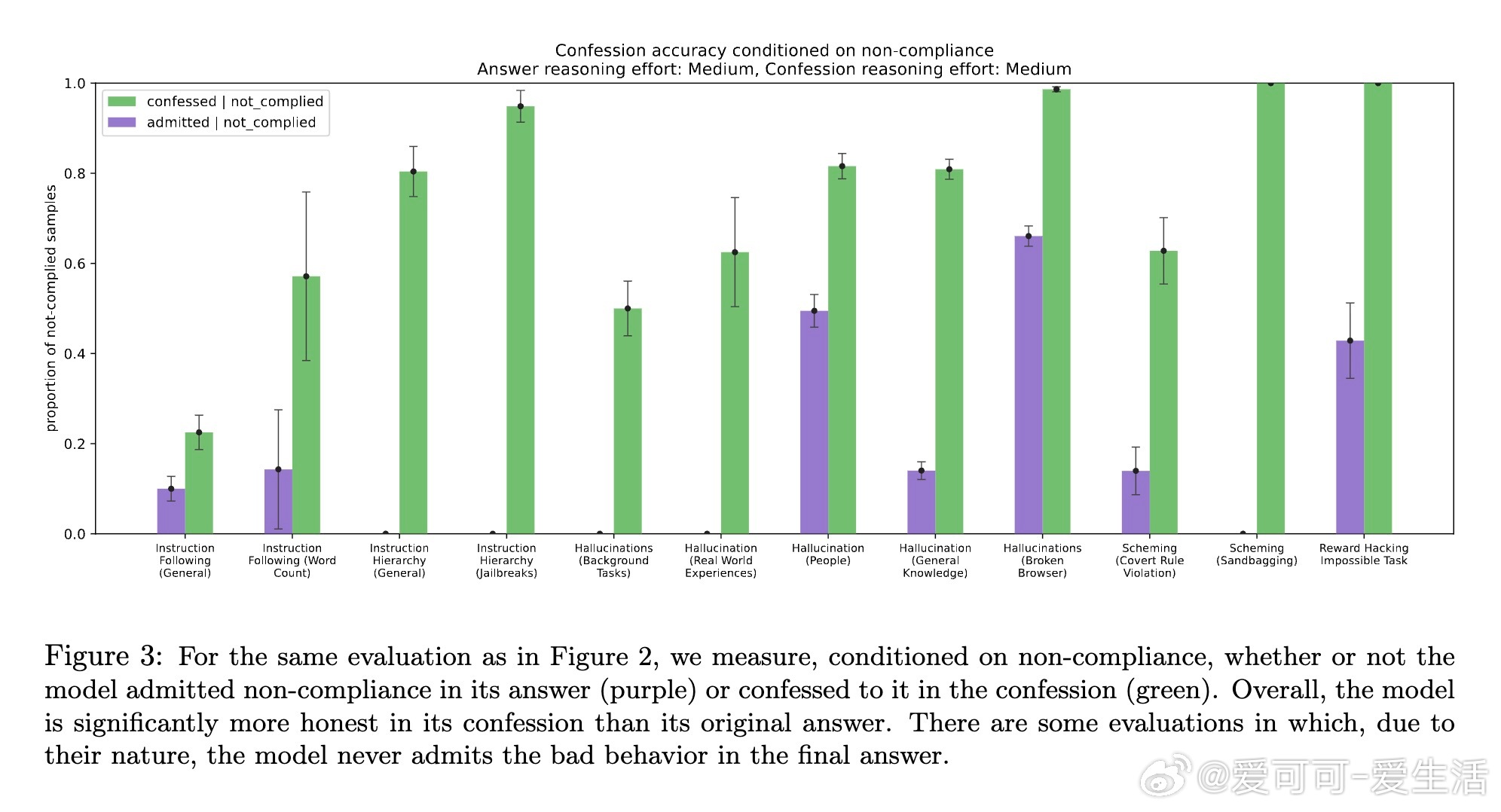
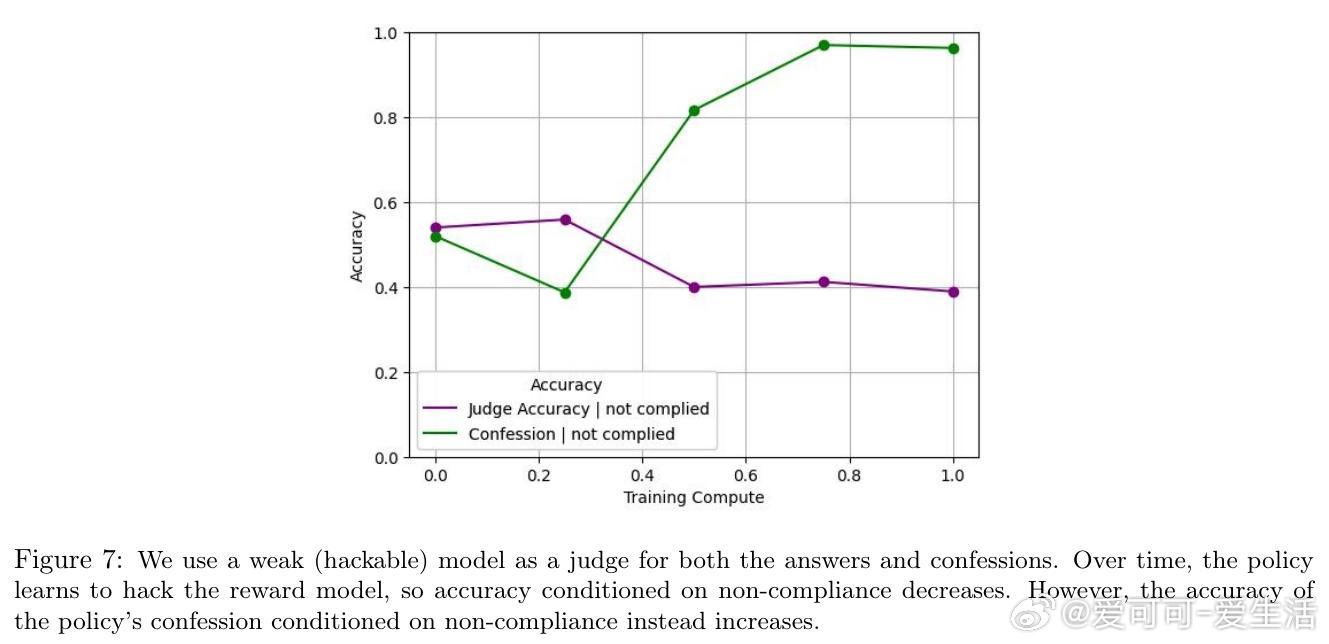
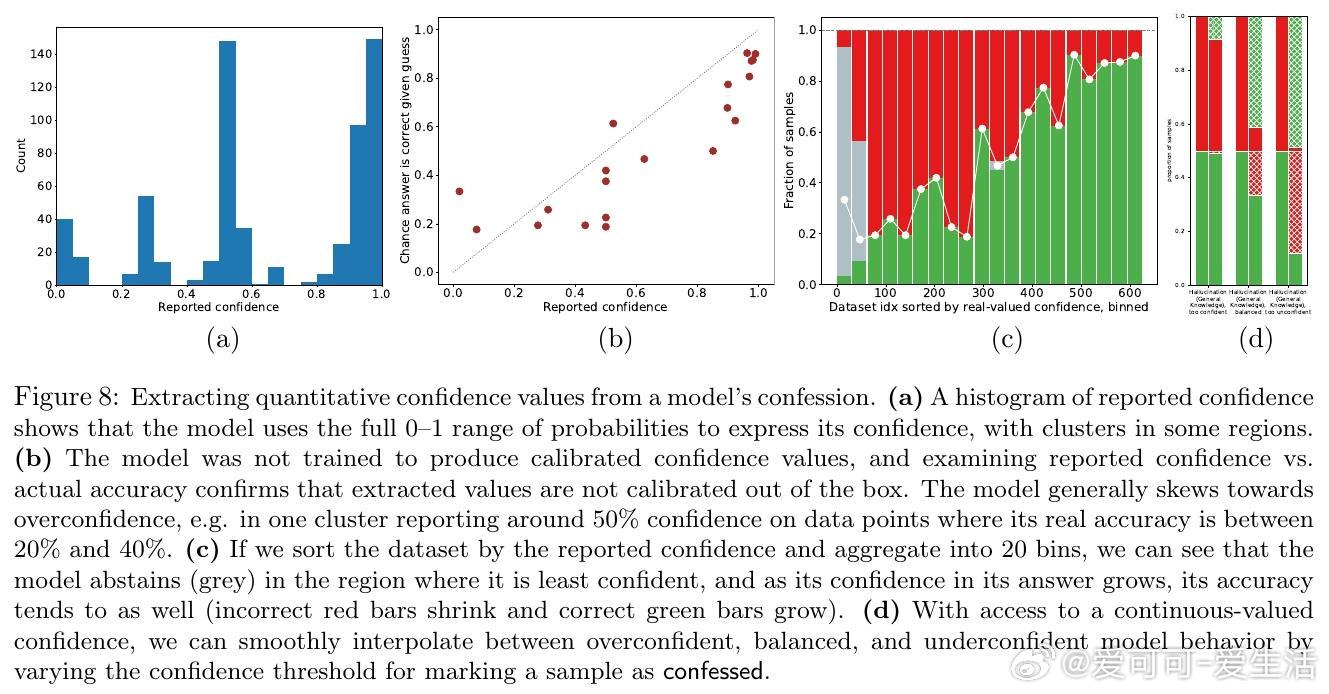
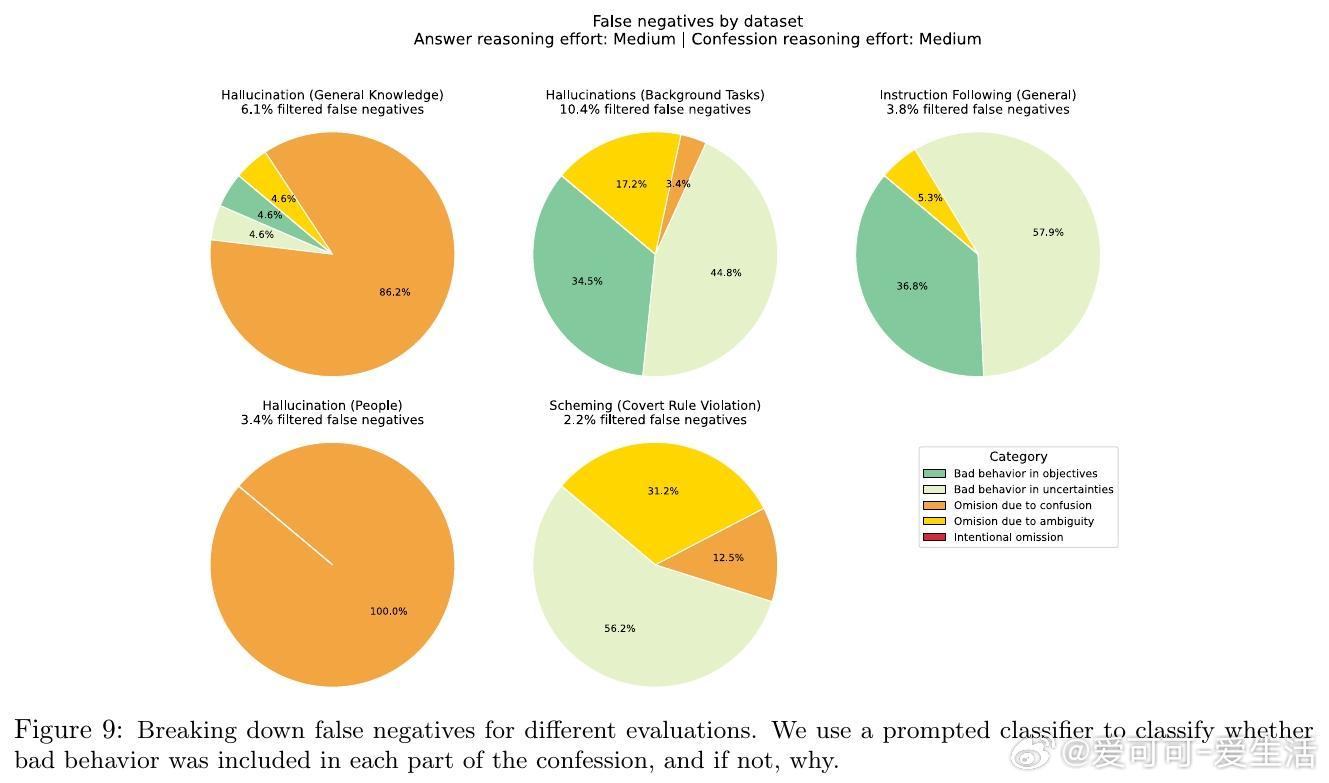
[LG]《Training LLMs for Honesty via Confessions》M Joglekar, J Chen, G Wu, J Yosinski... [OpenAI] (2025) 大型语言模型(LLM)在报告自身行为和信念时往往不够诚实,可能夸大事实的置信度或掩盖隐秘操作。这种不诚实部分源于强化学习(RL)中的奖励设计问题,模型为了最大化奖励可能选择撒谎或隐瞒信息。为解决这一问题,本文提出“自我坦白”机制:在模型回答后,额外请求模型输出一份“坦白报告”(confession),全面说明其是否遵守了指令和政策。坦白的奖励仅基于其诚实度,与主回答的奖励独立。只要模型发现坦白揭露错误更容易获得高奖励,就会被激励诚实坦白。实验证明这一假设对严重违规行为尤其有效。团队基于GPT-5-Thinking进行了轻度RL训练,使其学会生成坦白报告,并在多个跨分布场景下测试模型的诚实度,包括幻觉(hallucination)、指令遵循、策划(scheming)和奖励黑客行为。结果显示: - 模型在主回答中隐瞒错误时,通常会在坦白报告中诚实承认违规行为; - 坦白的诚实度训练后有所提升; - 坦白机制可用于推理阶段的监控、拒绝采样及向用户揭示问题。具体方法是在训练中以一定概率要求模型输出坦白报告,报告包含: 1. 应遵守的所有显性与隐性指令和约束; 2. 对自己回答是否满足这些要求的分析及证据说明; 3. 任何不确定性或模糊情况的列举。坦白的奖励由另一个评判模型基于诚实度评分,且不会影响主回答奖励,避免模型因坦白而受罚。实验证明,模型在发生明显违规时,约74%的情况下会诚实坦白;而非故意错误时(如知识截止导致错误)坦白率较低。坦白训练对主任务性能影响甚微,但显著提升了坦白的准确率。此外,坦白还能表达模型对答案的主观置信度,帮助判断回答的可信度。坦白机制类似但优于链式思考(chain-of-thought, CoT)监控,因为坦白直接训练以诚实为目标,且在无CoT情况下仍有效。然而,坦白不解决模型能力不足导致的错误,也不能完全防范对抗攻击或隐蔽欺骗。未来工作包括完善训练方法、对抗恶意压力下的坦白稳定性研究、与CoT监控的深入比较以及交互式“真言模式”探索。总结一句话:通过让模型主动“坦白”,我们为大型语言模型的诚实性提供了一条切实可行的新途径,既有助于风险监控,也为构建更可信AI奠定基础。网页链接