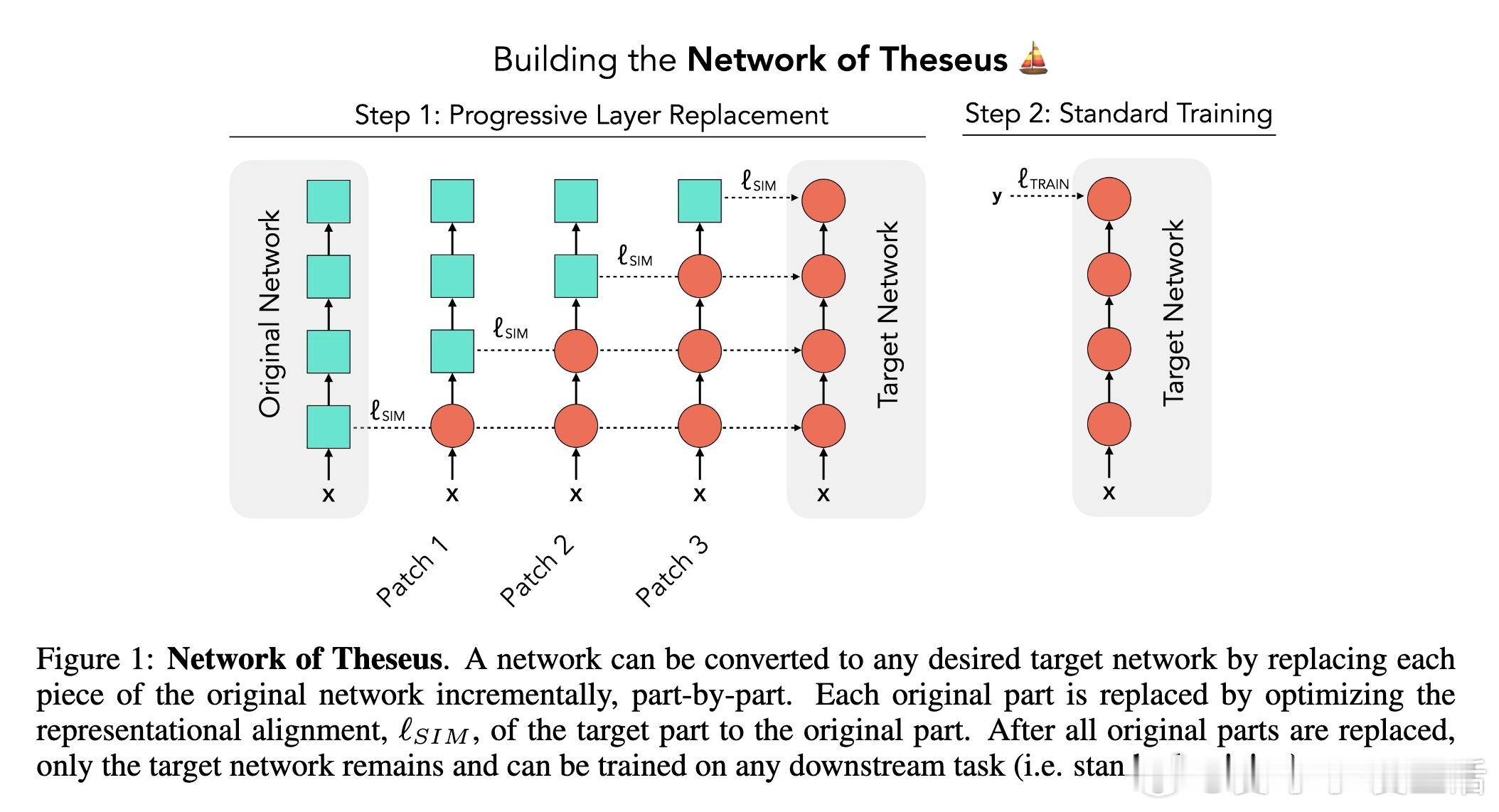
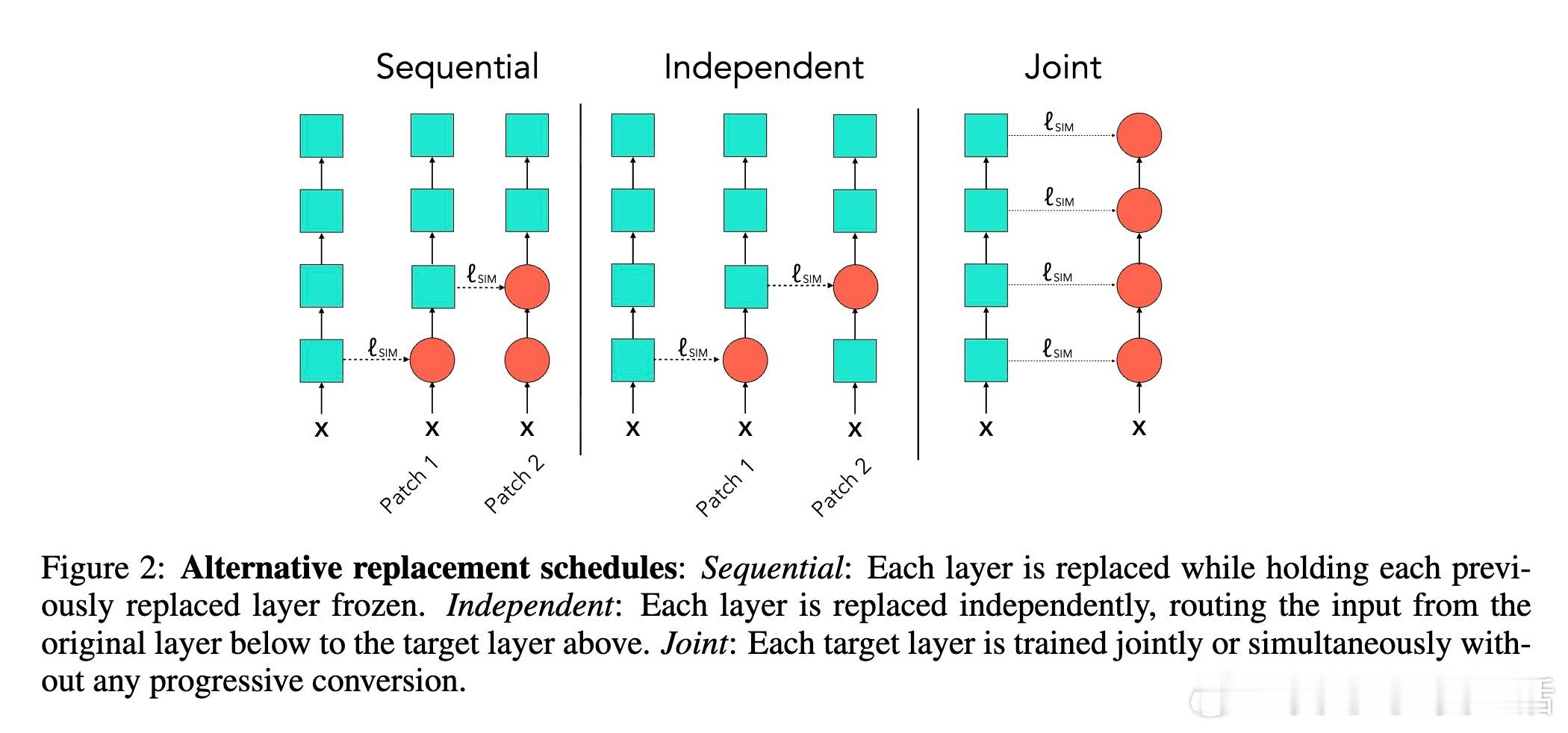
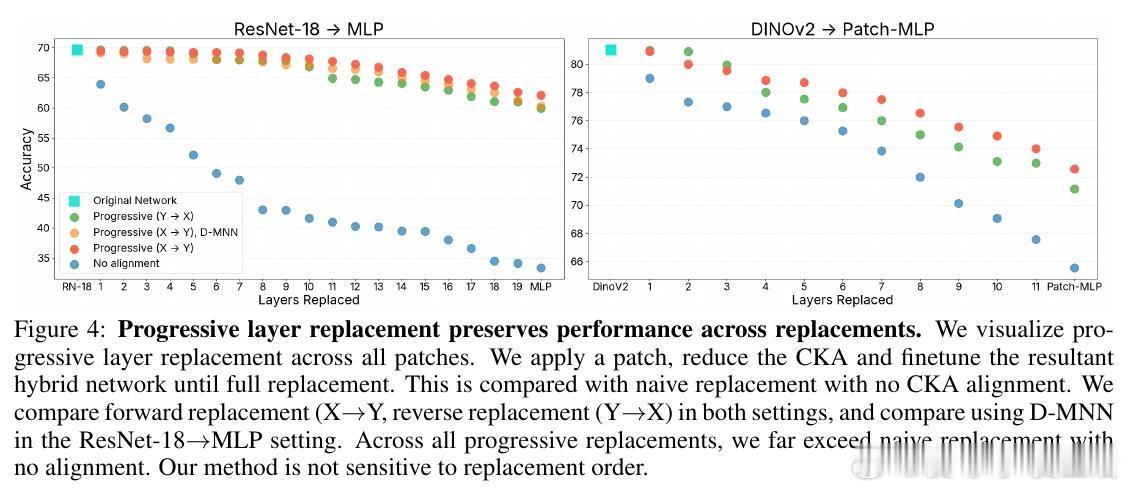
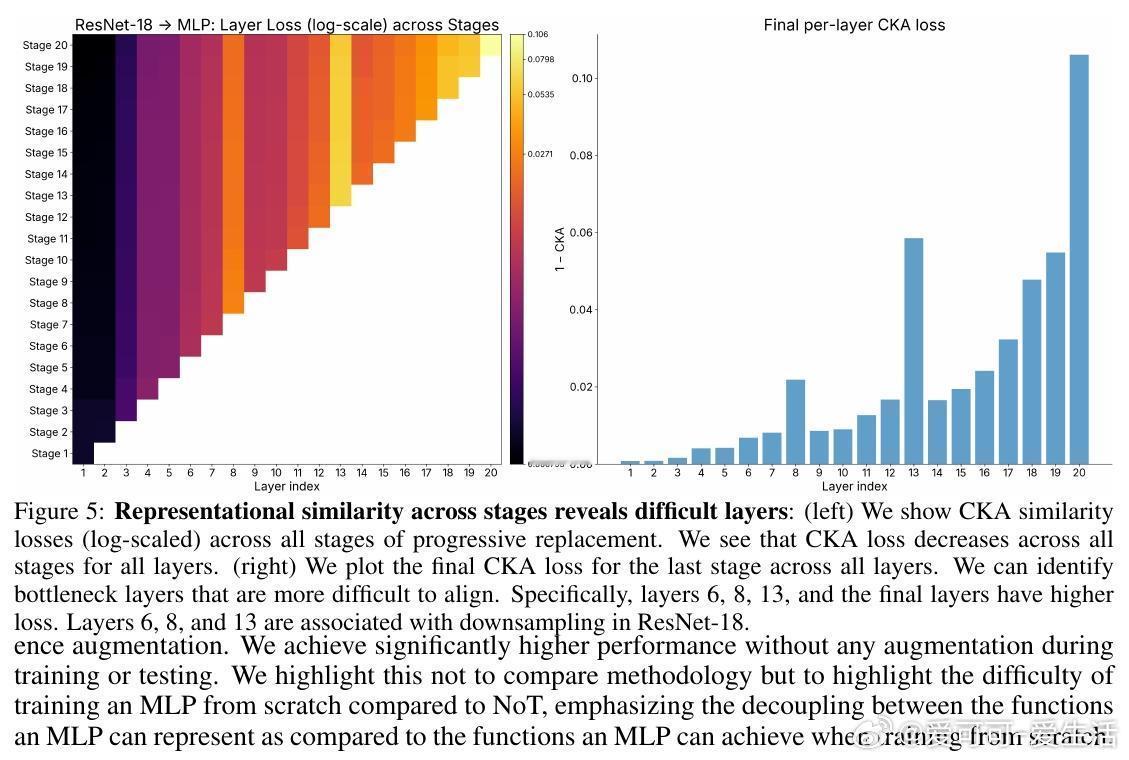
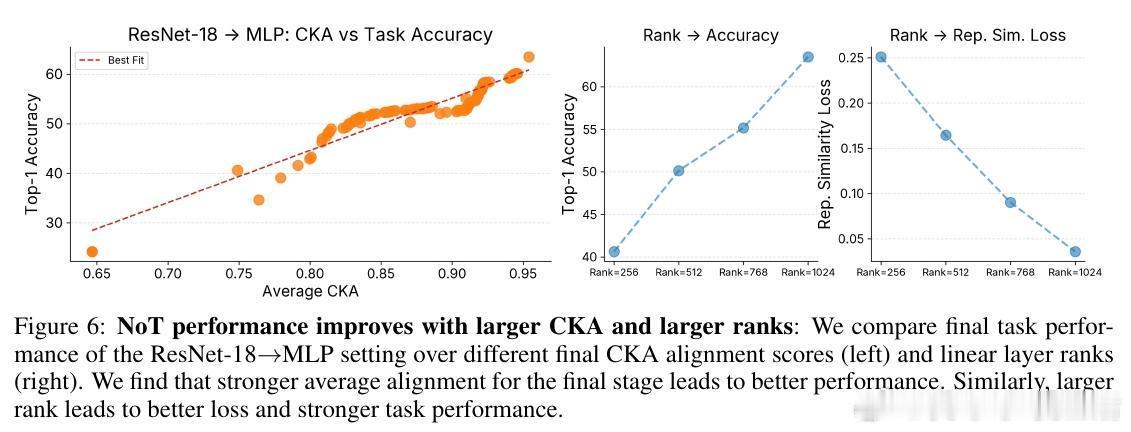
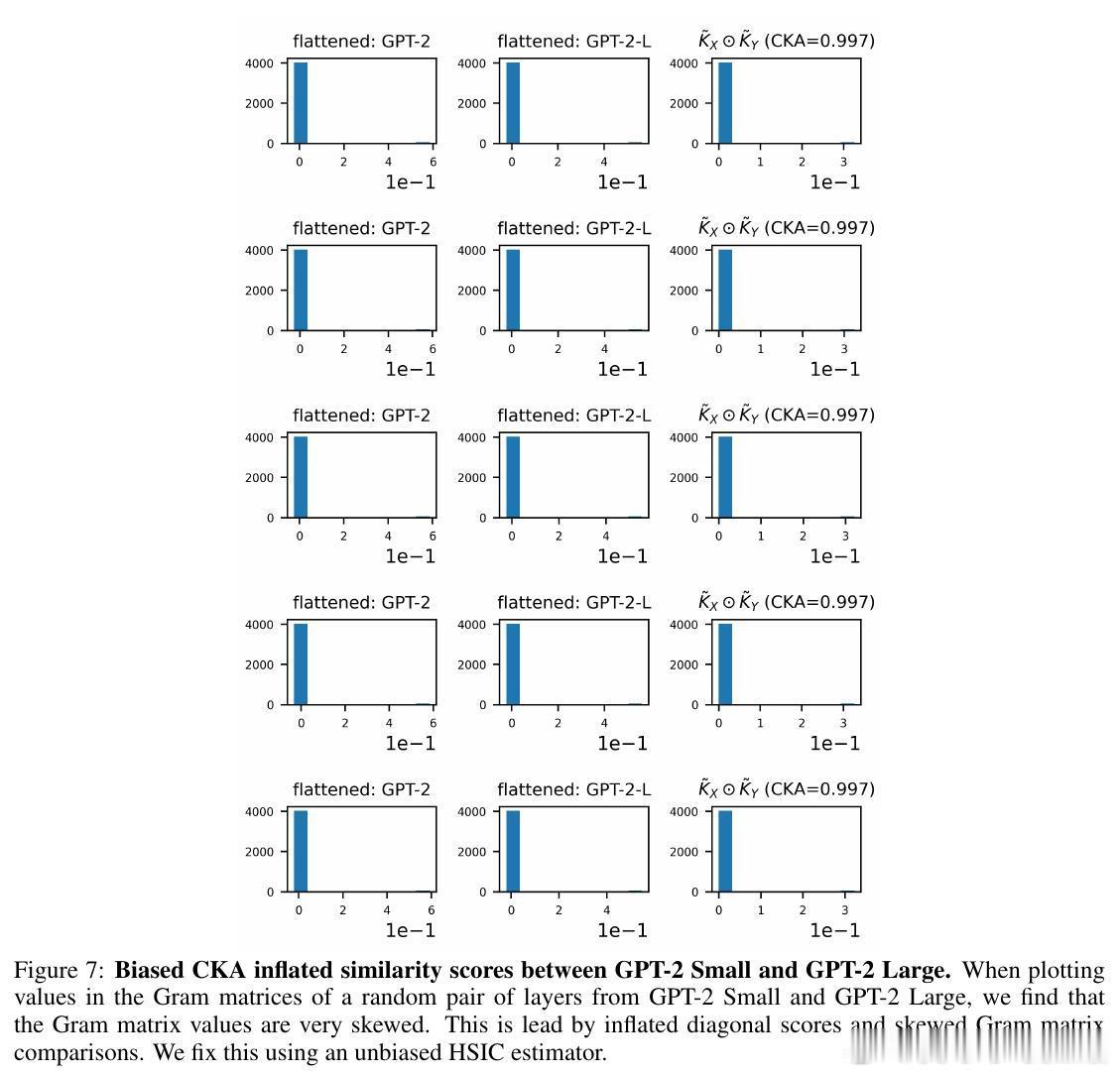
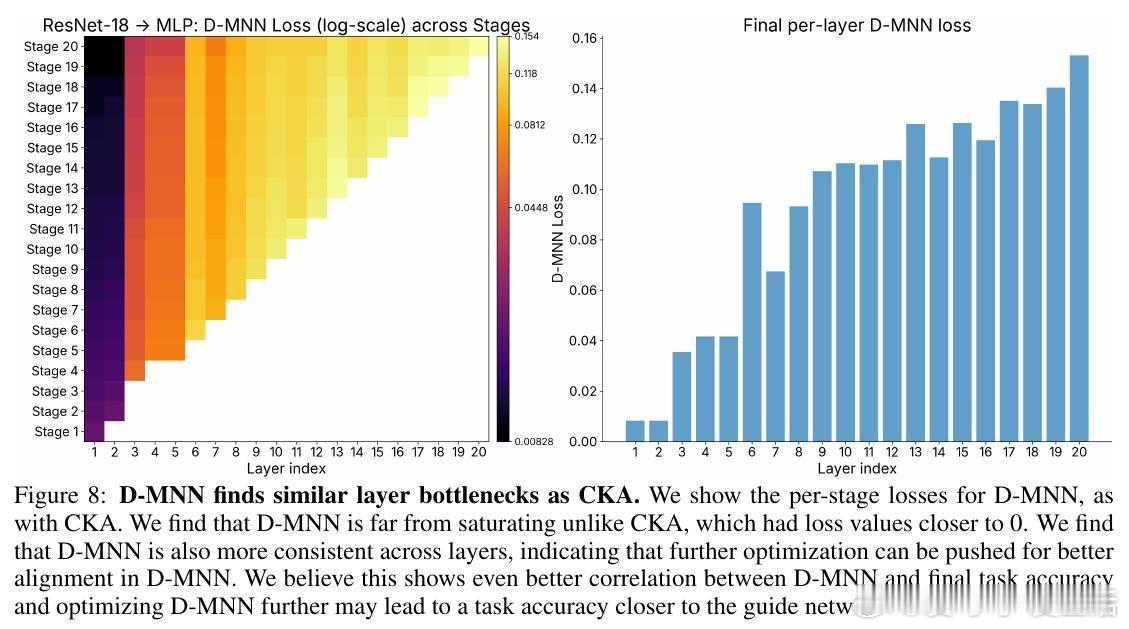
[LG]《Network of Theseus (like the ship)》V Subramaniam, C Conwell, B Katz, A Barbu... [MIT CSAIL & Johns Hopkins University] (2025) 在深度学习领域,传统观念认为训练时使用的神经网络架构必须与推理时保持一致——即“训练用什么,部署就用什么”。这一假设限制了架构设计的灵活性和效率优化的空间。本文提出了“Network of Theseus”(NoT)方法,打破了这一桎梏,实现了跨架构的渐进式转换,同时最大限度地保留了原始模型的性能。NoT灵感源自“忒修斯之船”悖论:当一艘船的所有部件都被逐一替换后,它还是原来的那艘船吗?对应神经网络,NoT通过分阶段、分部件地将“指导网络”的各层逐渐替换成“目标网络”中的模块,并利用表示相似性指标(如线性CKA和新提出的D-MNN)对替换模块的激活进行对齐训练,确保功能的连续性和性能的保持。关键亮点包括:1. 架构解耦训练与推理 NoT允许训练和推理时采用不同架构。模型可先在易于优化的架构(如深层卷积网络)上训练,再转换为更高效或更适合部署的架构(如轻量级MLP或递归网络),极大拓展了设计空间。2. 广泛的架构转换能力 实验涵盖了卷积网络到多层感知机(ResNet-18→MLP)、视觉Transformer到Patch-wise MLP(DINOv2→Patch-MLP)、Transformer语言模型到递归神经网络(GPT-2→RNN)、以及深层到浅层网络的转化(ResNet-50→ResNet-18)等多种场景,均能保持接近原网络的性能。3. 未训练网络也能传递结构先验 令人惊讶的是,NoT在未训练的指导网络上同样能有效工作,说明未训练网络本身蕴含的结构性偏置就足够传递给目标网络,拓宽了架构迁移和初始化的可能性。4. 逐层渐进替换优于一次性替换 实验对比了多种替换调度策略,发现逐层递进式替换稳定性最好,能最大程度降低误差累积,确保转换过程中的表现连续性。5. 提出新型表示相似度指标D-MNN 基于互为最近邻的思想,D-MNN在捕获局部几何结构上优于传统CKA,为表示对齐提供了更丰富的信号。6. 实际应用与理论启示 NoT不仅能挖掘更优的准确率-效率折中方案,还启发我们重新思考神经网络架构设计的目标:训练时应着重构建“可被不同架构发现”的表示,而非限定最终推理架构,真正实现训练与推理的解耦。总结来说,NoT通过代表性对齐和分阶段替换,开启了“架构灵活转换”的新时代,挑战了传统的训练部署一体化范式,为模型压缩、加速和架构搜索提供了新思路。未来研究将聚焦于提升难对齐层的转换效果、扩展至更多复杂架构以及自动化替换调度策略。详细论文见:arxiv.org/abs/2512.04198