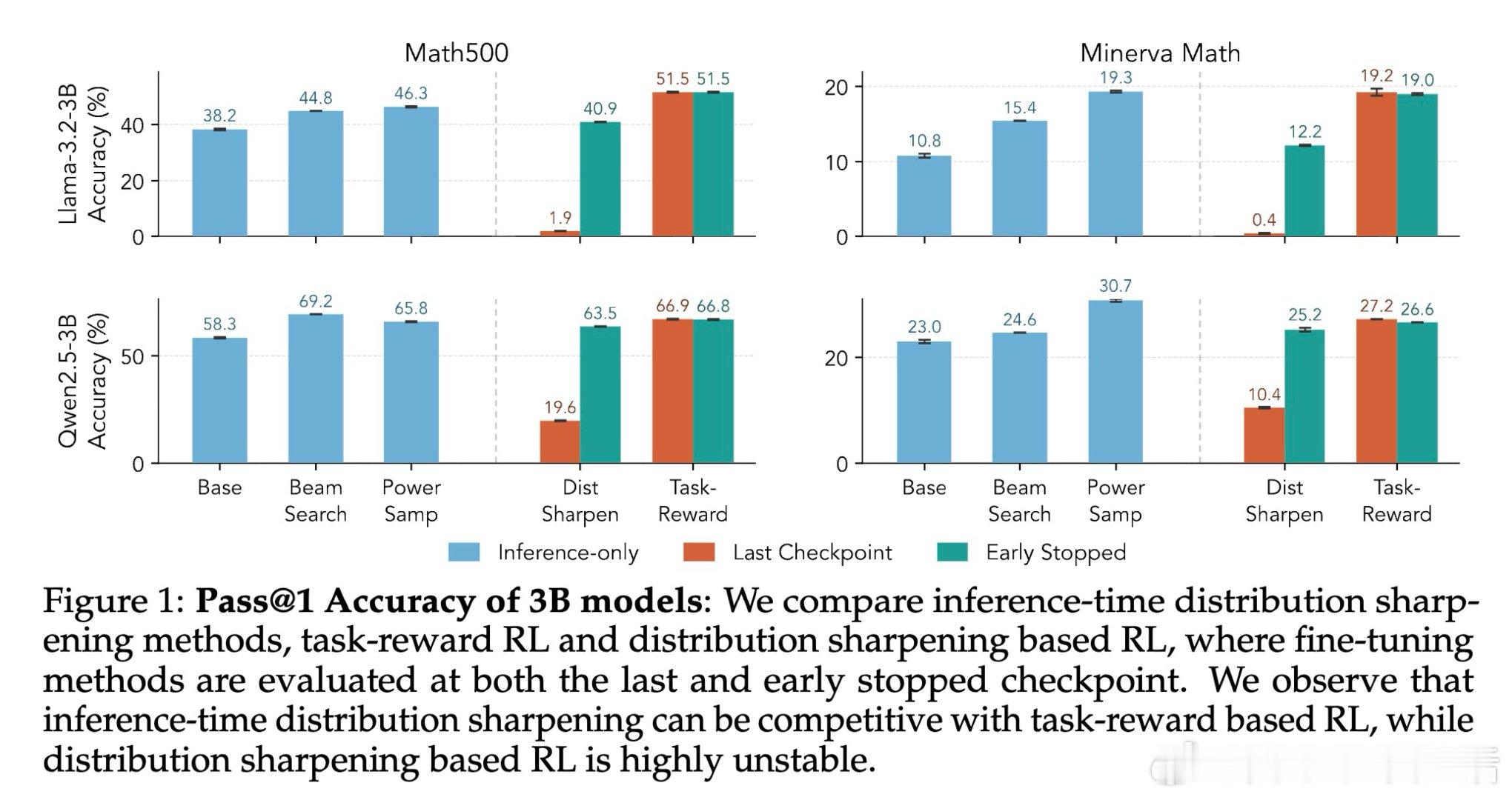
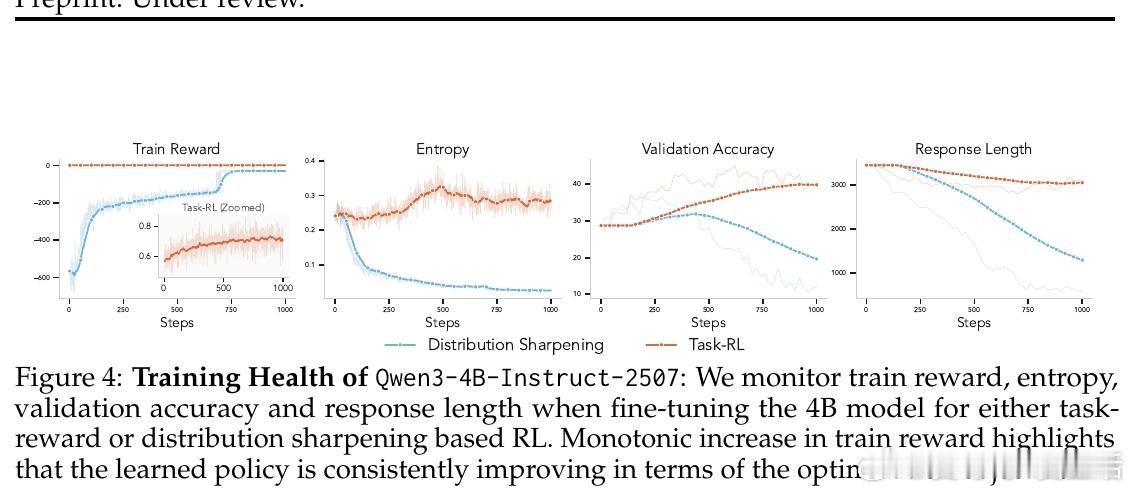
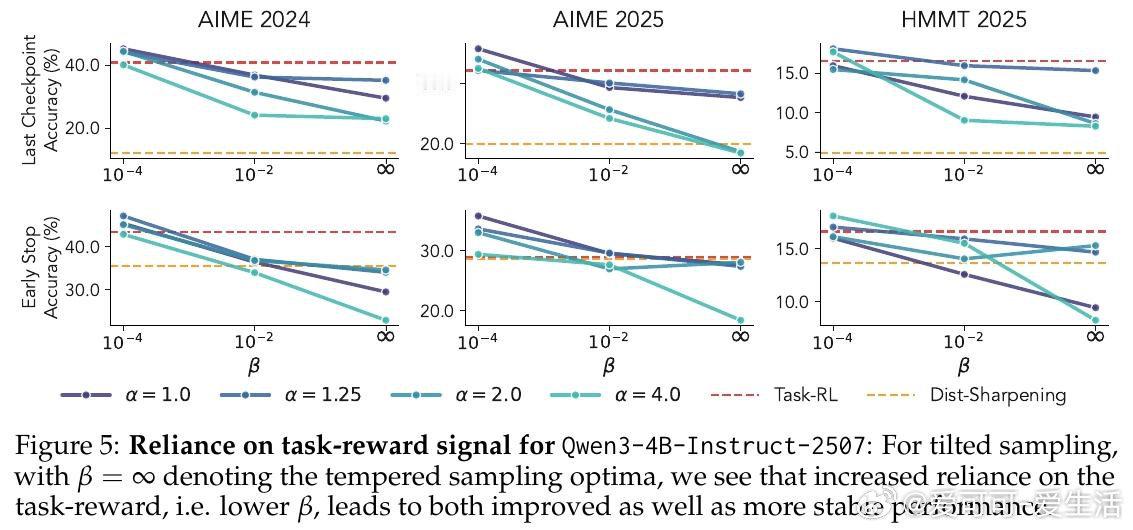
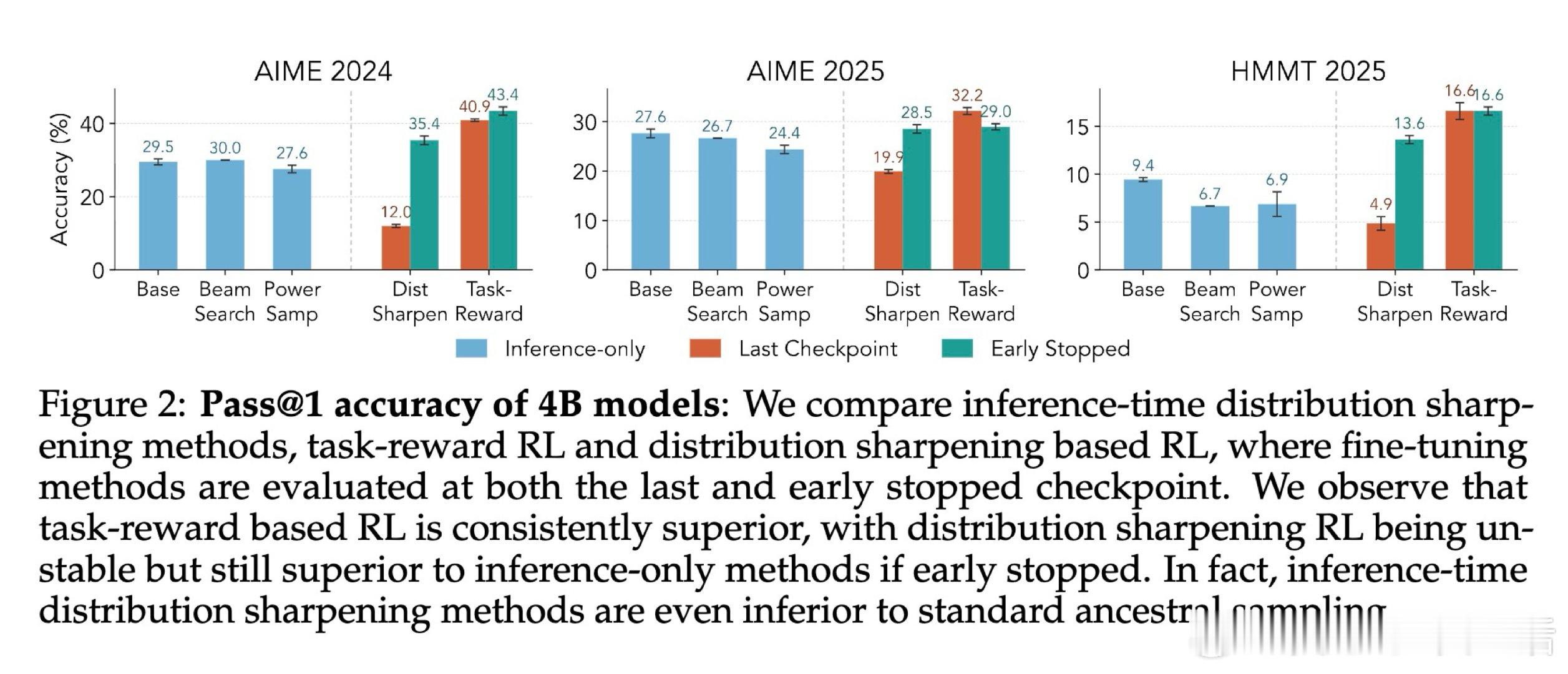
[LG]《Beyond Distribution Sharpening: The Importance of Task Rewards》S Mittal, L Gagnon, G Lajoie [Mila] (2026)
在大语言模型后训练领域,强化学习究竟在"创造"新能力还是仅仅"挤压"既有能力,是一个悬而未决的核心争议。过去支持分布锐化假说的工作受困于缺乏受控对比——推理时方法与训练时方法混用,无法剥离信号来源的真实作用。
本文的核心洞见是:把分布锐化与任务奖励视为同一RL框架下可独立操控的两个旋钮。由此,通过固定训练范式、仅切换奖励信号与KL目标,研究者得以将两种机制直接解耦——实验揭示分布锐化的崩溃根源恰在于变长序列的EOS吸收机制,而非优化过程本身的缺陷。
这项工作真正留下的遗产是:为后训练收益的归因分析提供了一套可复现的对照框架,明确证明任务奖励信号是稳健能力提升不可替代的来源。它为后来者打开的新门是:奖励设计本身(而非规模或推理时计算量)可能才是能力天花板的真正约束。但尚未跨过的门槛是:实验限于数学推理这一可验证任务,且序列长度与多任务混合场景下的结论是否同样成立,仍有待检验。
arxiv.org/abs/2604.16259
机器学习 人工智能 论文 AI创造营