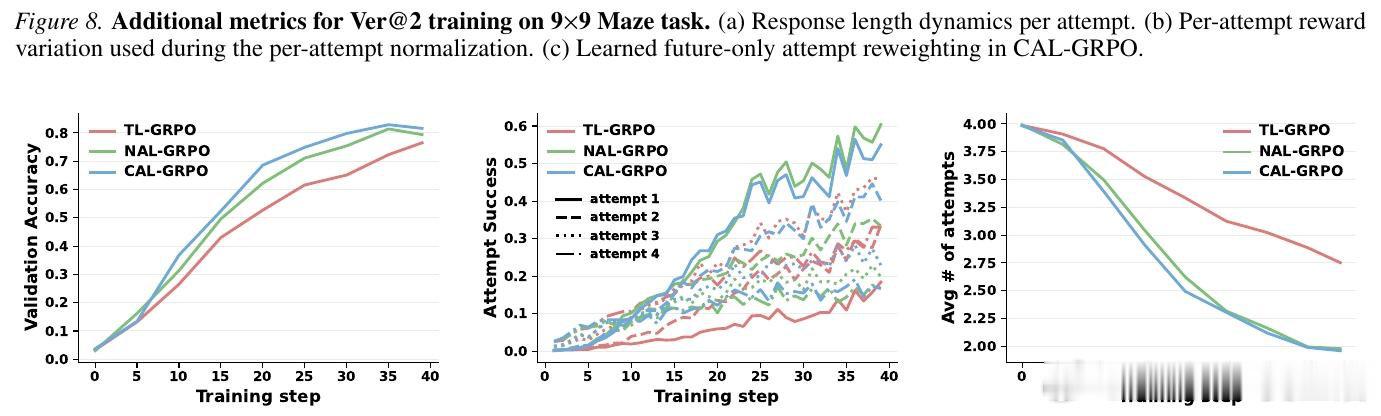
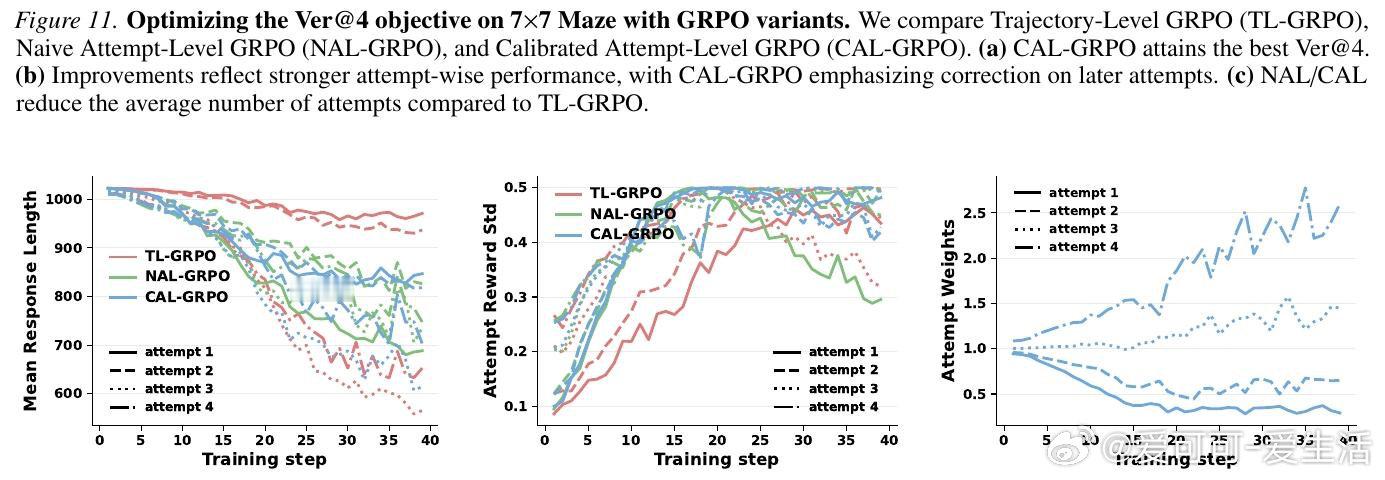
[LG]《Learning to Correct: Calibrated Reinforcement Learning for Multi-Attempt Chain-of-Thought》M E Ildiz, H A Gozeten, E O Taga, S Oymak [University of Michigan] (2026)
在强化学习与大模型推理的交叉地带,如何为多次尝试分配学习信号是一个悬而未决的难题。过去的方法要么把整条轨迹视为单一单元(损失了密集反馈),要么朴素地按每次尝试的对错赋权(无意中对早期尝试过度投资),本质原因是缺乏一个将各次尝试贡献与最终成功概率精确对齐的权重方案。
本文的核心洞见是:把每次尝试的学习信号重新看作对最终"至少成功一次"概率的边际贡献。由此,用后续所有尝试的失败概率之积来校准当前尝试的权重这一关键操作,使偏差问题得以解开——第一次尝试的更新聚焦于那些后续补救无望的硬案例,而非无差别地压榨已被第二次尝试兜底的样本。
这项工作真正留下的遗产是:为多次尝试场景下的策略梯度估计提供了一套有理论保证的权重校准框架,将无偏性与方差压缩同时纳入同一算法。它为后来者打开的新门是探索如何将这套校准逻辑推广到噪声或学习型验证器、以及自适应尝试次数的动态分配;但尚未跨过的门槛是:当前理论依赖"尝试之间独立"的简化假设,而真实长链推理中历史信息对后续生成的影响远比这复杂。
arxiv.org/abs/2604.17912
机器学习 人工智能 论文 AI创造营