[LG]《AutoOR: Scalably Post-training LLMs to Autoformalize Operations Research Problems》S R Motwani, C Du, A Petrov, C Davis… [X, The Moonshot Factory & University of Oxford] (2026)
在运筹学领域,将自然语言描述的优化问题转译为求解器可执行代码是一个悬而未决的难题。过去的方法受困于训练数据稀缺且质量低下,本质原因是"从描述生成正确代码"这一方向本身难以验证,而人工标注又无法规模化。
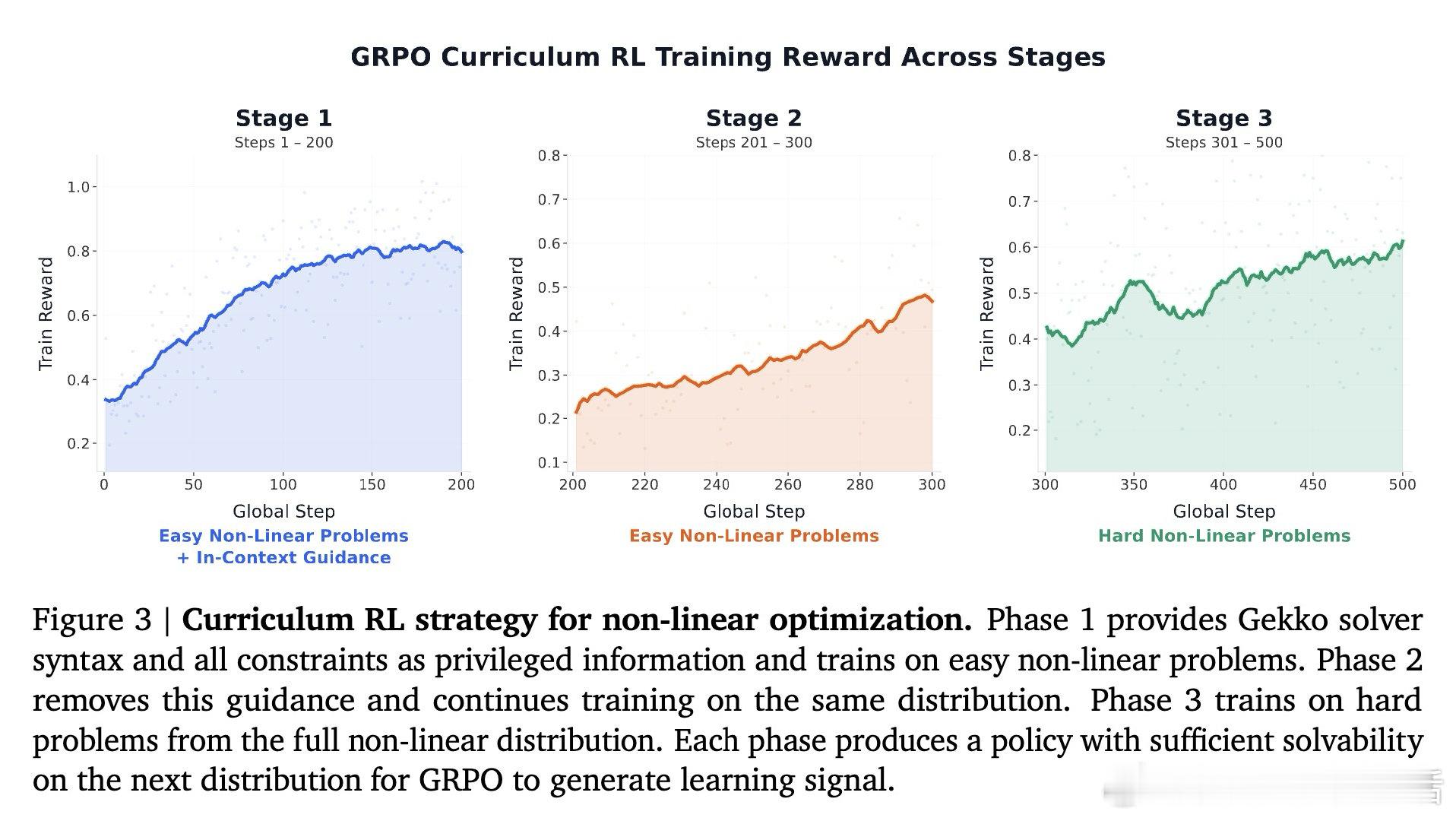
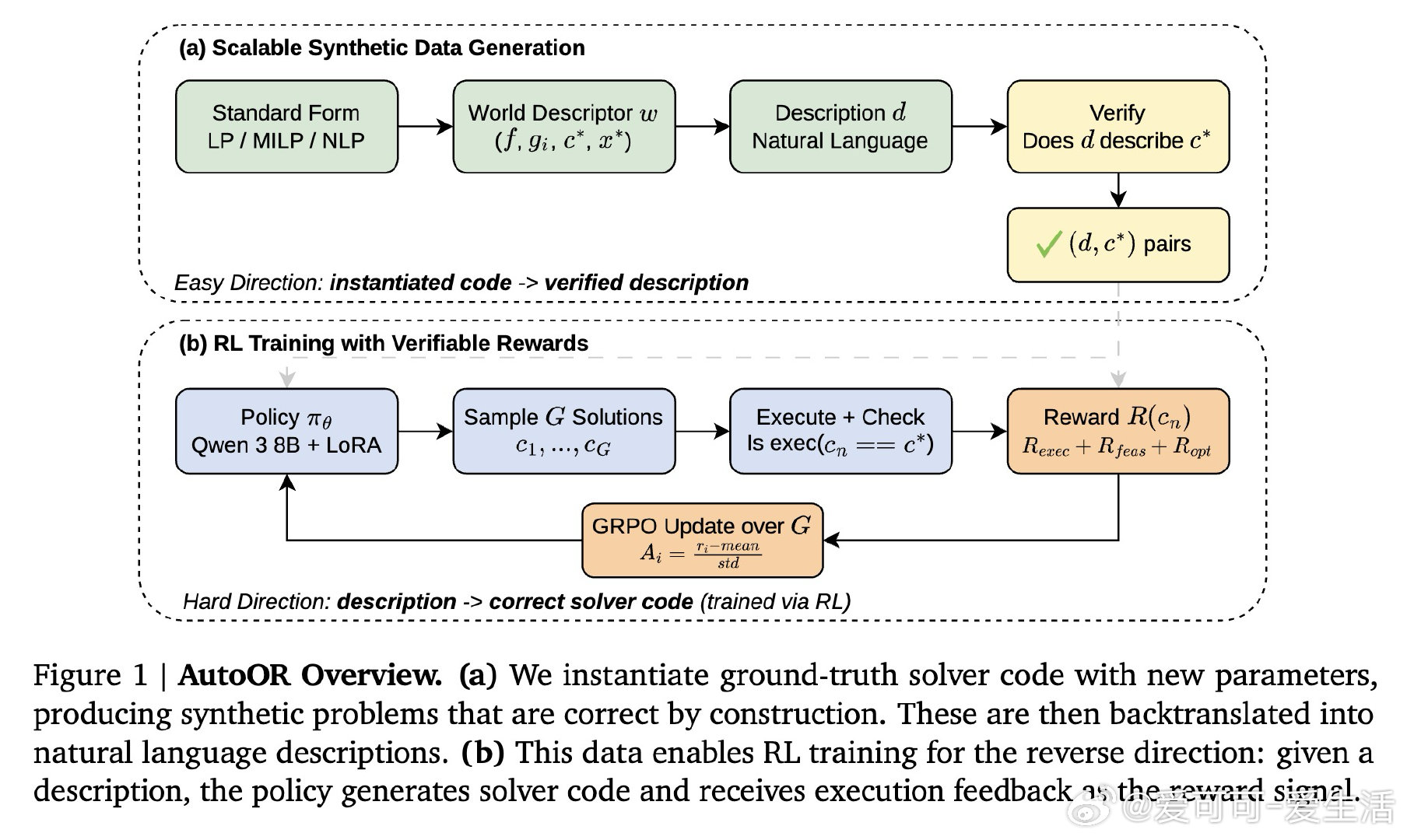
本文的核心洞见是:把"生成验证数据"这件难事重新看作"反向翻译"——先从标准数学形式实例化出正确的求解器代码,再将其转译成自然语言描述,而非相反。由此,以求解器执行结果作为奖励信号的强化学习训练,使模型真正学会了将物理约束和混合整数结构精确编码进代码。
这项工作真正留下的遗产是:证明了优化自动形式化可以被改造成一个可验证的强化学习域,让80亿参数的开源模型能与体量大得多的前沿模型竞争。它为后来者打开的新门是:将课程式强化学习推广至更广泛的非线性领域,以及构建多轮交互的自主建模智能体。但尚未跨过的门槛是:当前非线性能力仅限于单一问题族(泵网络),奖励函数对等价但效率迥异的公式化方案一视同仁,距离真实工业建模的全流程仍有相当距离。
arxiv.org/abs/2604.16804
机器学习 人工智能 论文 AI创造营