TokenSpeed 是 LightSeek Foundation 开源的一个新 LLM 推理引擎。地址:github.com/lightseekorg/tokenspeed目标是在性能上接近 TensorRT-LLM、在易用性上接近 vLLM。“TokenSpeed 从基本原理出发,为智能代理推理环境而设计。它为智能代理工作负载提供光速推理,具备基于编译器的并行建模机制、高性能调度器、安全的 KV 资源复用限制、支持异构加速器的可插拔分层内核系统,以及低开销的 CPU 端请求入口 SMG 集成。
建模层采用局部 SPMD(单程序多数据)设计,实现性能与可用性的平衡。TokenSpeed 允许开发者在模块边界指定 I/O 放置注解。轻量级静态编译器随后在模型构建期间自动生成所需的集合操作,无需手动实现通信逻辑。
TokenSpeed 调度器将控制平面与执行平面解耦。控制平面以 C++ 实现,作为有限状态机,与类型系统协作,在编译时而非运行时强制安全资源管理,包括 KV 缓存状态传输与使用。请求生命周期、KV 缓存资源及重叠时序通过显式 FSM 转换和所有权语义表示,从而通过可验证的控制系统而非约定来保证正确性。执行平面采用 Python 实现,以保持开发效率,加快功能迭代并降低研究人员和工程师的认知负荷。
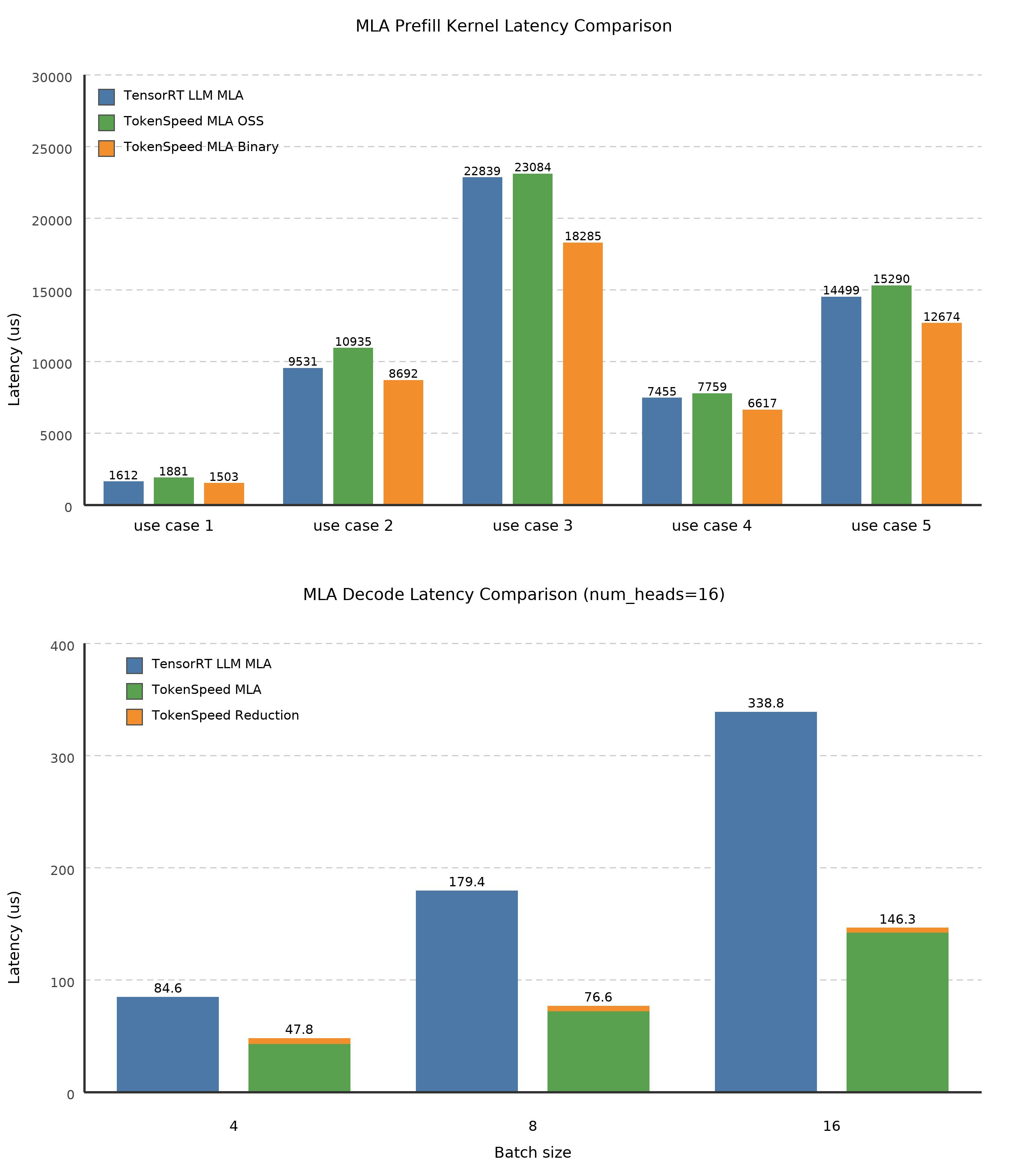
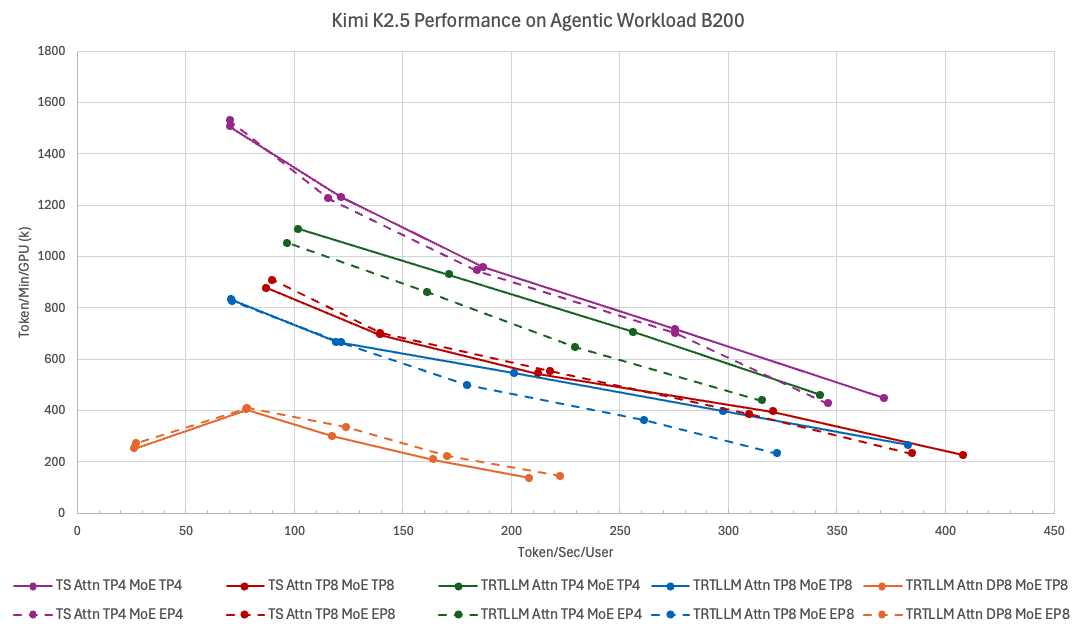
TokenSpeed 内核层将内核与核心引擎分离,并将其视为一等模块化子系统。它提供可移植的公共 API、集中注册与选择模型、组织化实现、支持异构加速器的可扩展插件机制、精选依赖项以及用于快速迭代的统一基础设施。我们还在 NVIDIA Blackwell 上投入了大量性能优化,例如,为智能代理工作负载构建了最快的 MLA(多头潜在注意力)内核之一。在解码内核中,我们将 q_seqlen 与 num_heads 分组,以充分利用 Tensor Core,因为在某些用例中 num_heads 较小。二进制预填充内核包括经过微调的 softmax 实现。TokenSpeed MLA 已被 vLLM 采用。”
AI创造营