🔆 核心发现(基于 2000+ 次实验)
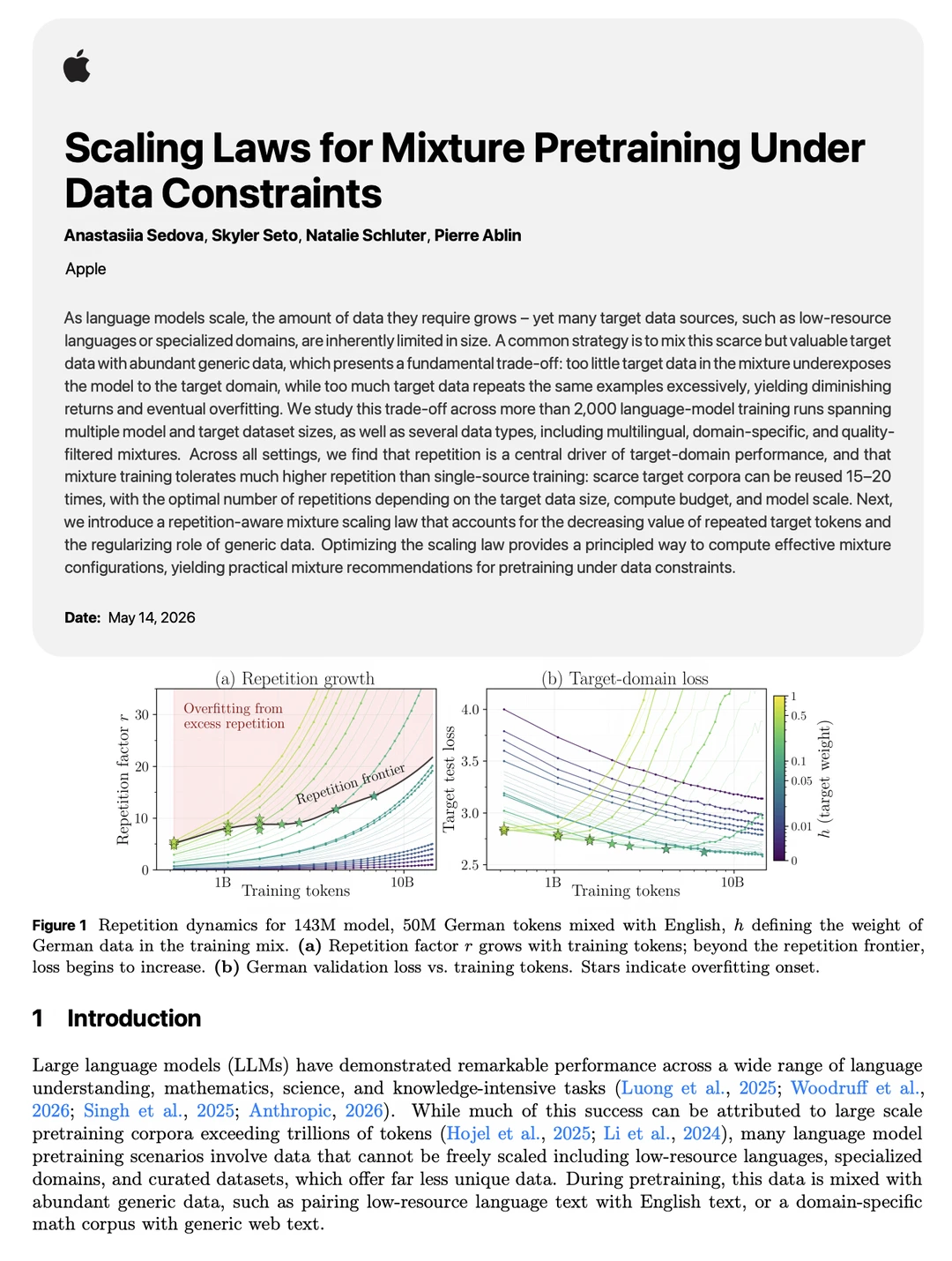
- 重复次数(r)才是过拟合的关键驱动,而非单纯混合比例 h。
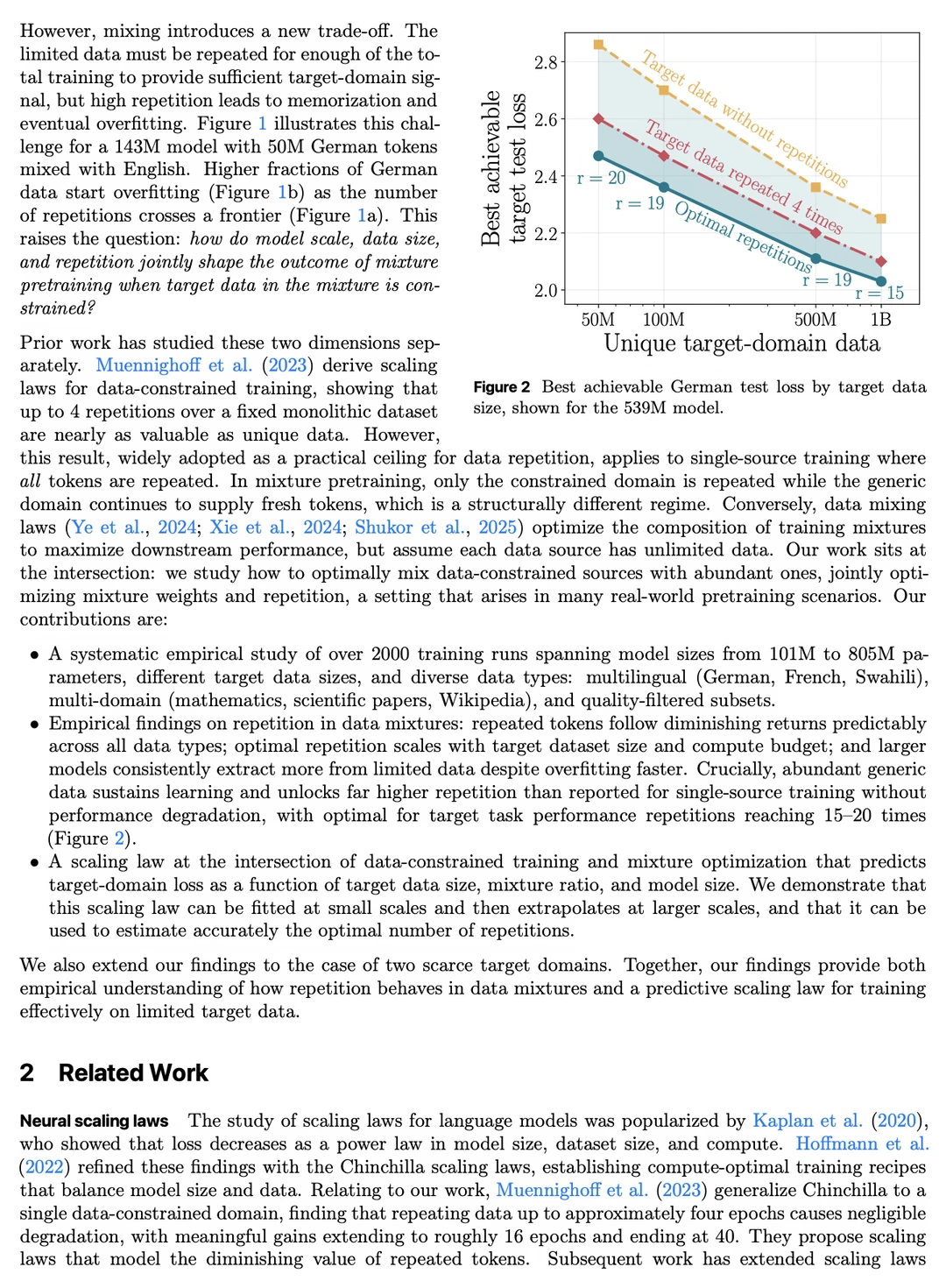
- 混合训练能承受的最优重复次数远高于单数据源,单源通常 4 次左右就到顶,而混合场景下15–20 次甚至更高仍有收益!通用新鲜数据起到了强大的正则化作用。
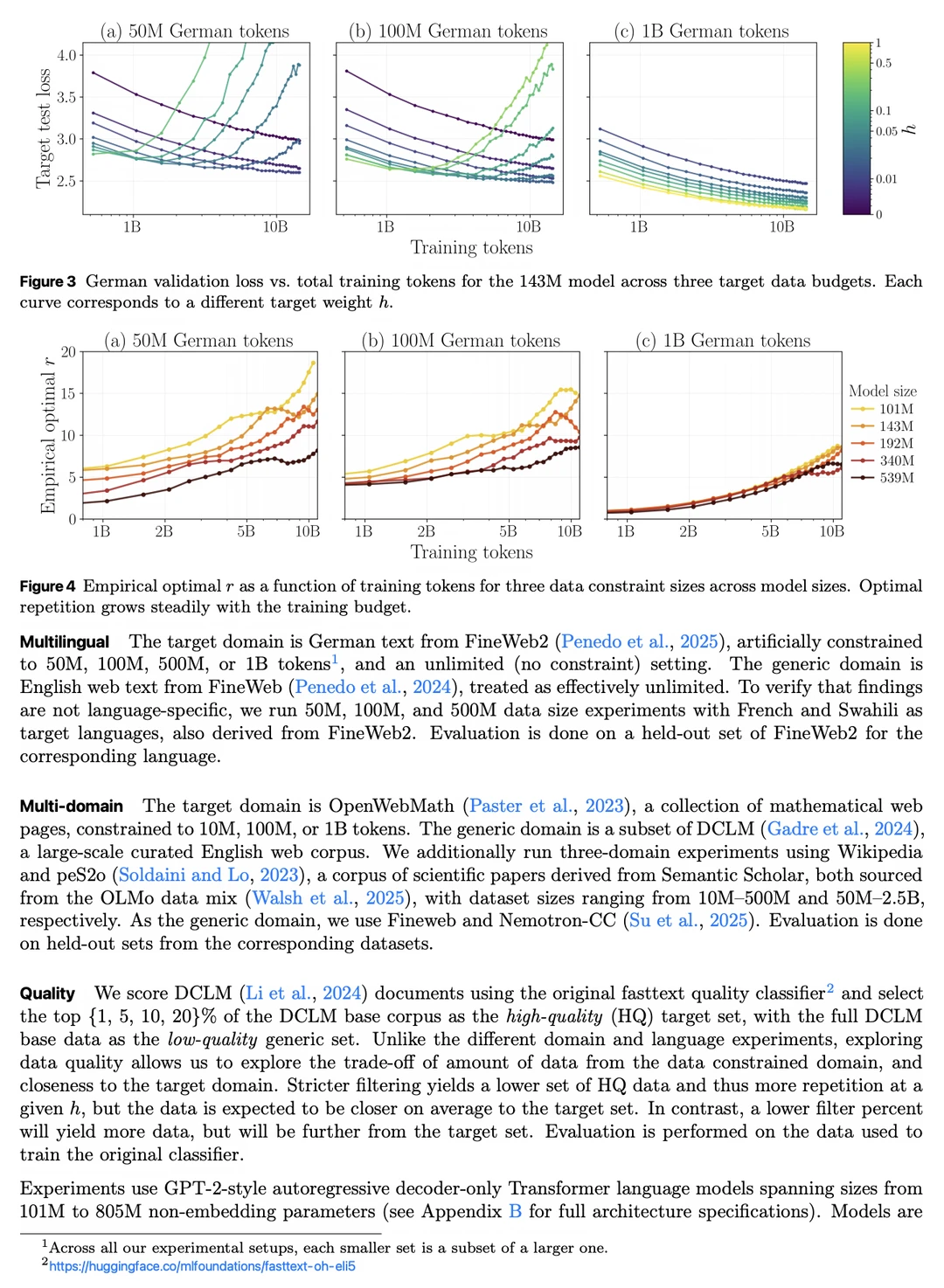
- 最优重复次数会随计算预算(训练更久)而增加。
- 大模型能从有限数据中榨取更多价值,但也过拟合得更快。
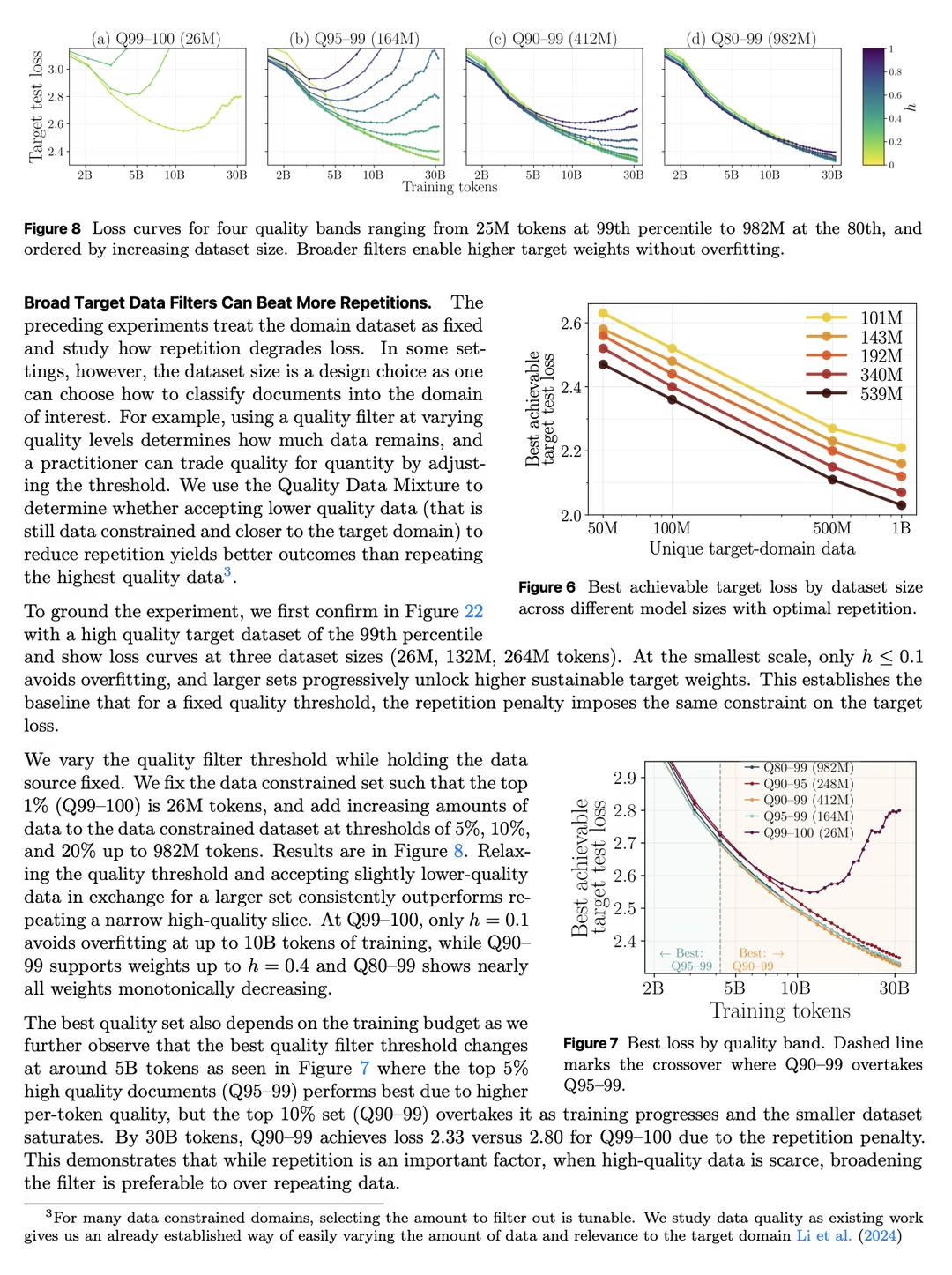
- 质量 vs 数量,很多时候,「放宽质量过滤 + 多一点数据 + 适度重复」 胜过 「极高质量小数据集 + 高重复」。
Apple 机器学习研究团队提出了一个重复感知的混合缩放定律,通过「有效数据 D_eff 」概念,能准确预测目标领域 loss。
小规模实验拟合后,即可外推指导大规模训练,直接算出最优混合比例 h(或重复次数 r),大幅降低昂贵的网格搜索成本。
这篇工作通过大规模实证 + 优雅的缩放定律,澄清了「数据受限混合预训练」的核心动力学(重复是关键,通用数据是强大正则器),并给出了可操作的优化工具。
对实际构建多语言、专业或高质量模型有直接指导价值。
感谢阅读,如果你觉得对你有用的话 ~ 欢迎点赞收藏并分享给你的朋友们~