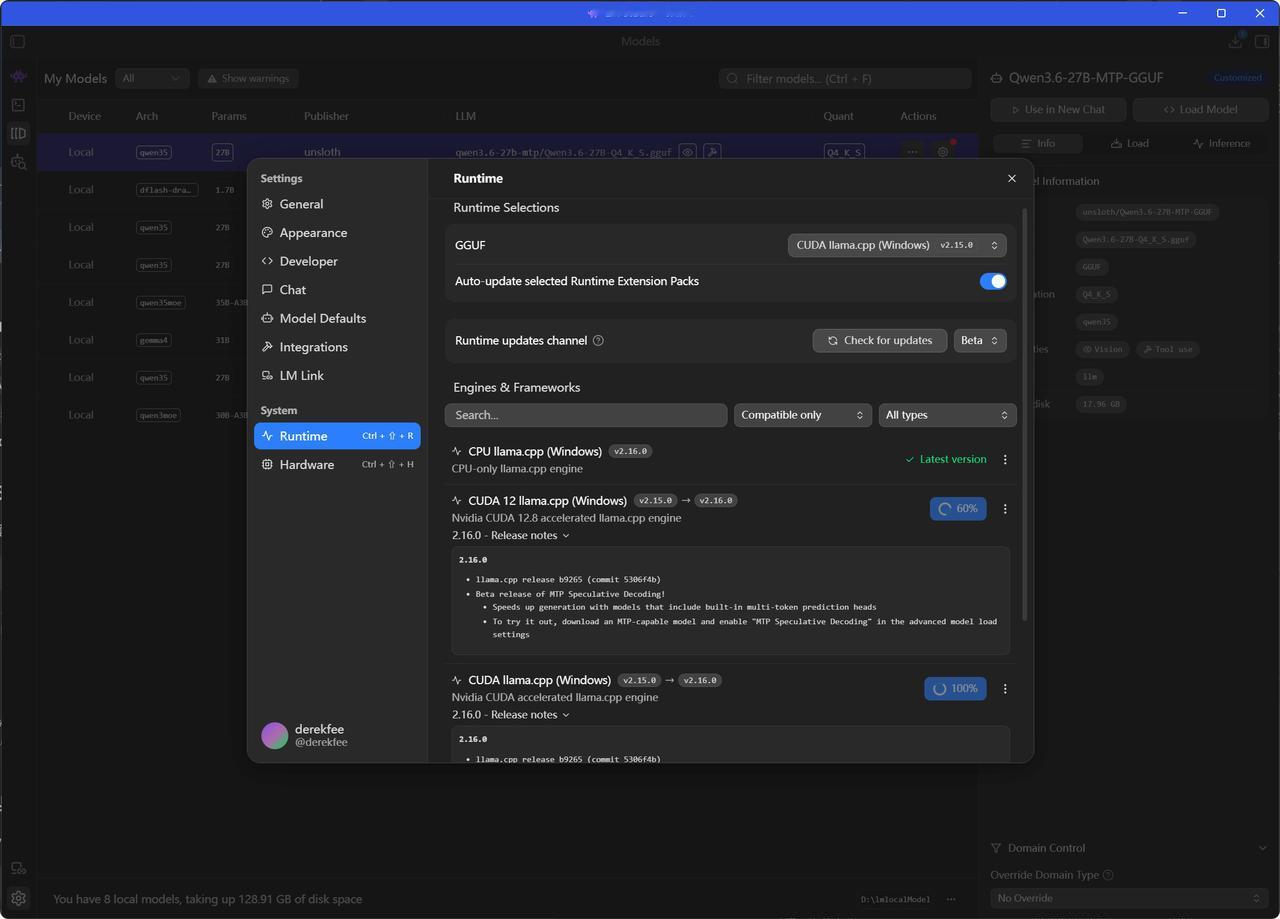
lm studio的Beta版已经支持MTP加速:
1.相比于llama.cpp已经将mtp合并进主分支,lm studio也在beta版客户端中开放新版本MTP的加速了,可以直接在正式版里切换beta版进行测试。
2.在设置里切换beta版后,在右侧调整开启MTP功能,下载支持MTP的模型,我使用qwen3.6-27B-MTP版,普通对话能跑到45token/s(未开启MTP大概35t/s左右),确实有提高,但是相比llama.cpp能跑到55t/s。
3.长上下文压缩还是需要时间来在有限的硬件配置里进行优化,还需要一段时间。