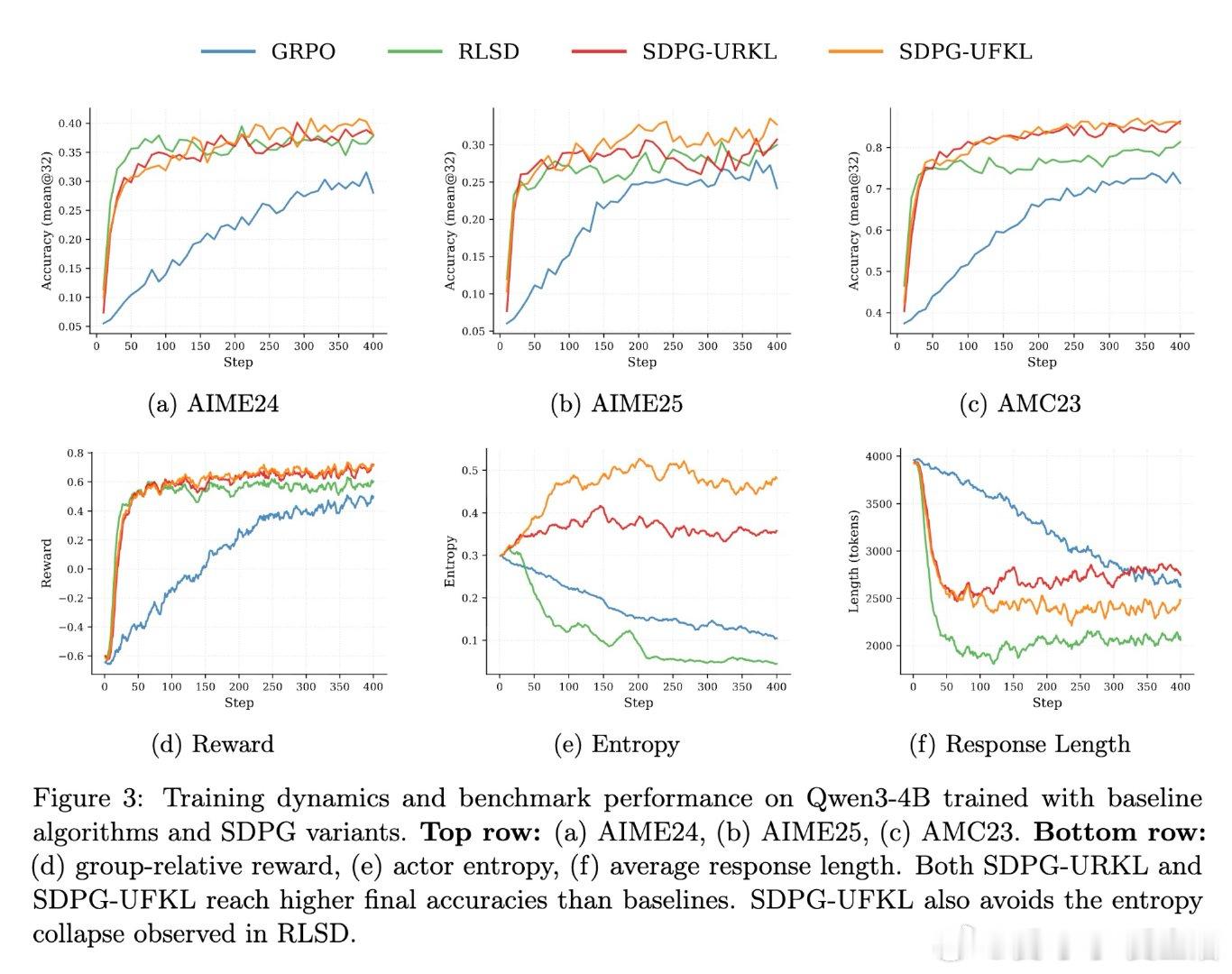
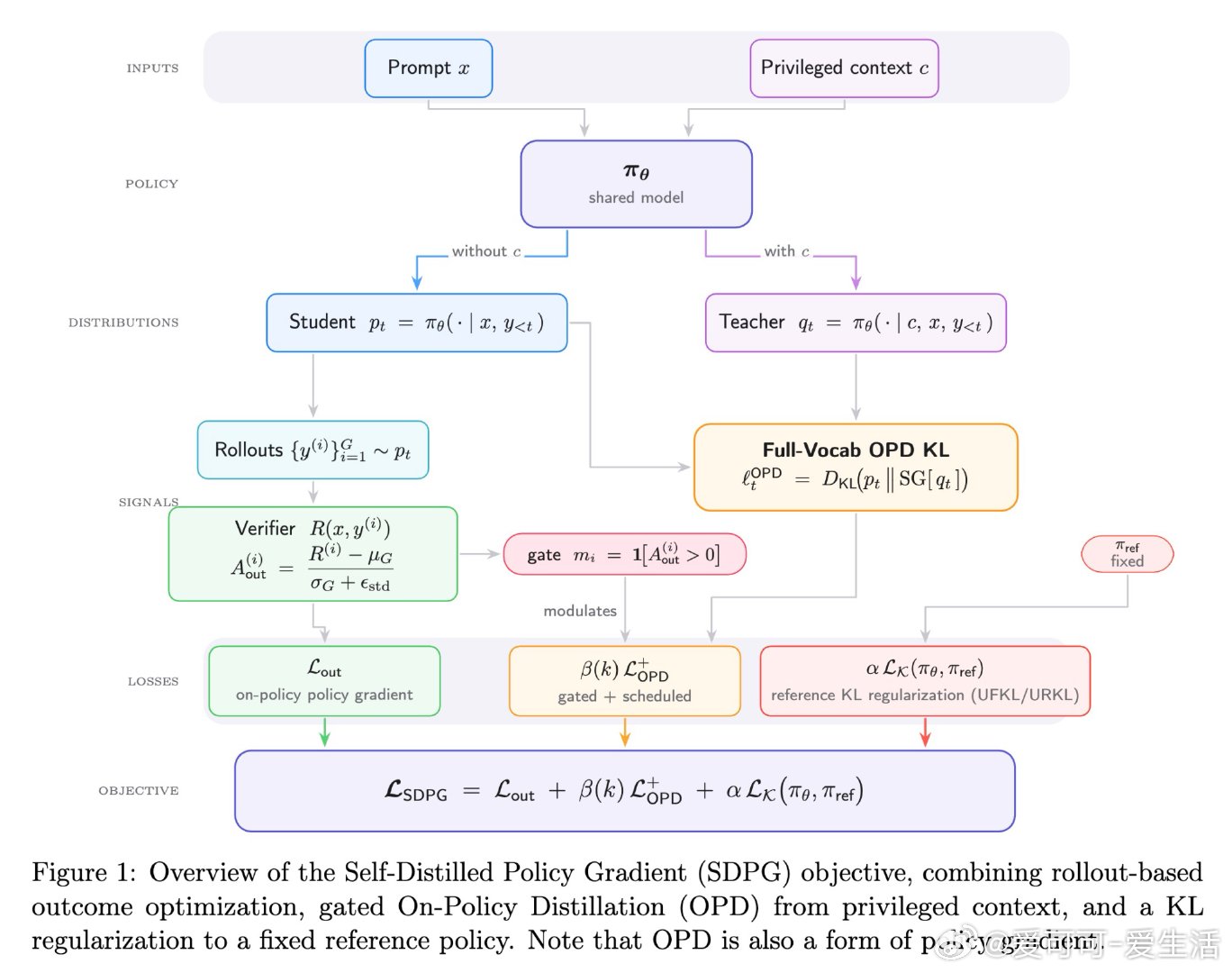
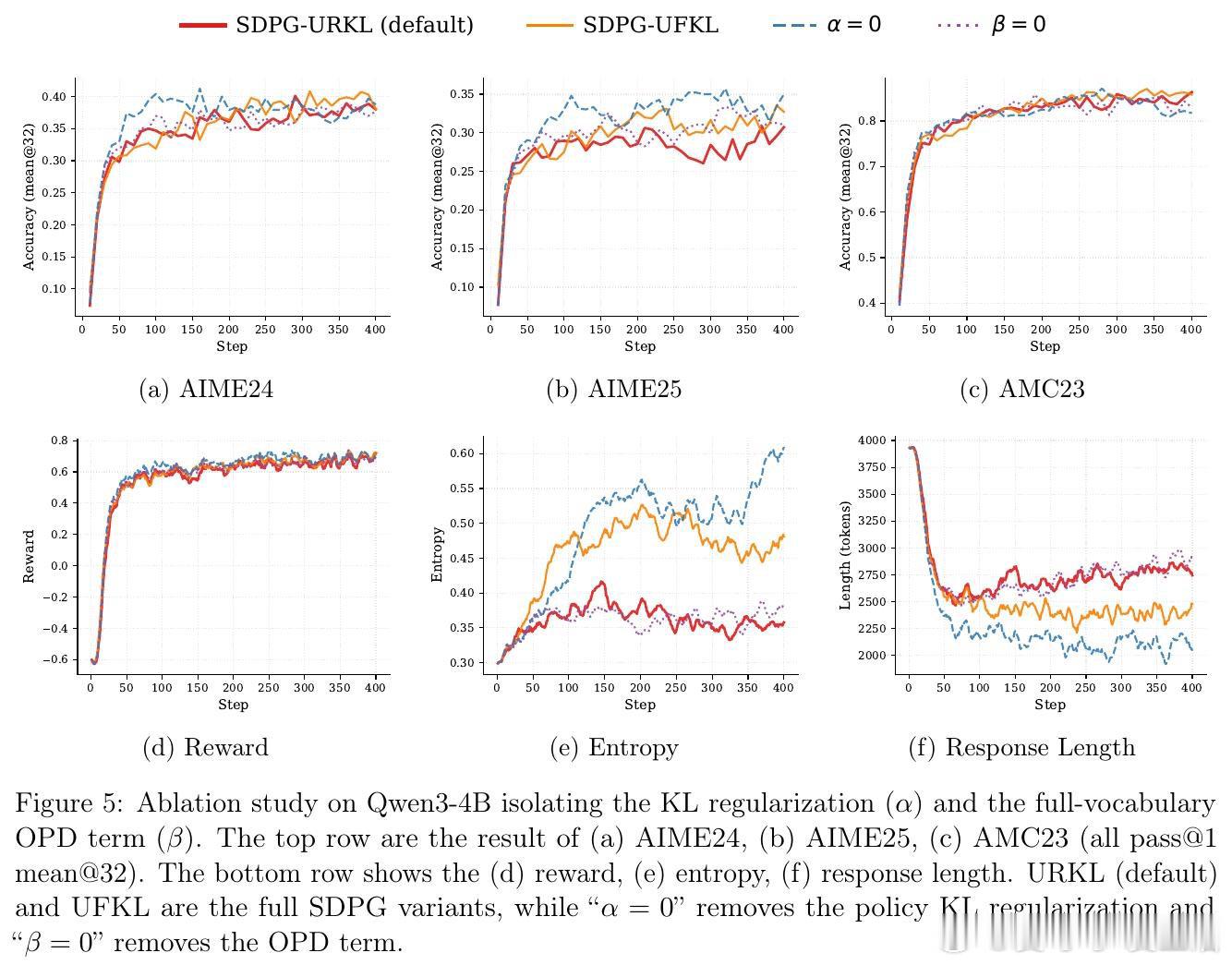
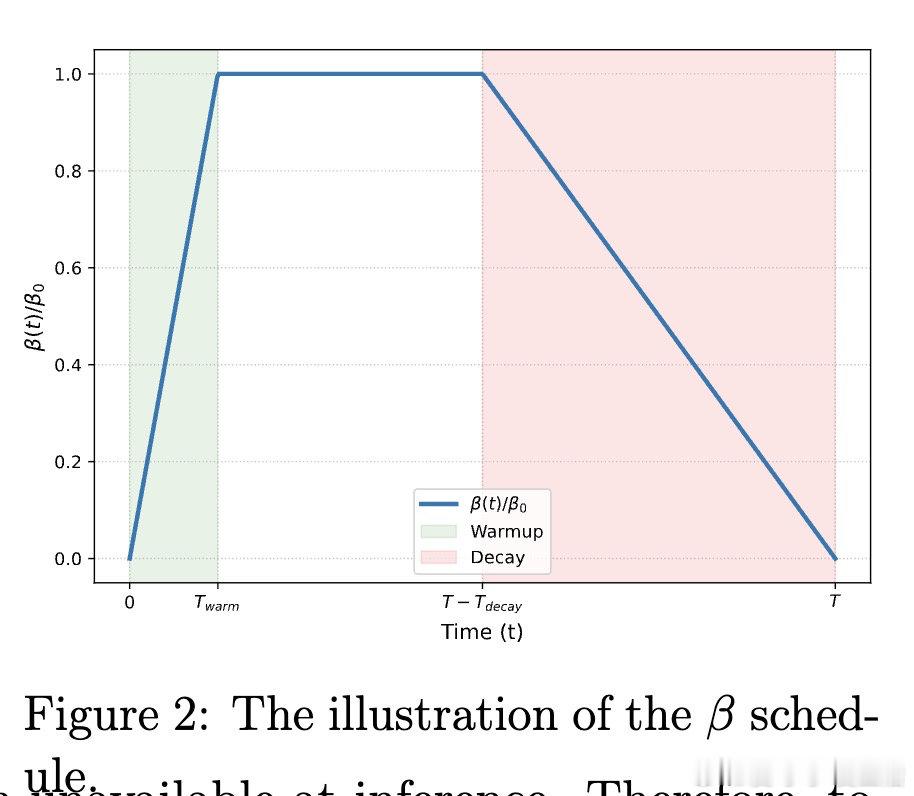
[LG]《Self-Distilled Policy Gradient》Y Liu, S Zhang, Y Zhang, Q Gu [University of California, Los Angele & Princeton University] (2026)
在LLM推理强化学习中,稀疏结果奖励难以告诉模型哪一步推理错了。过去RLVR受困于整段答案只给一个分数,本质原因是信用分配停留在序列级。
本文的核心洞见是:把“带提示的同一模型”重新看作自己的教师。由此,全词表反向KL把隐藏答案线索压成逐token信号,并只在验证器认可的轨迹上蒸馏。
这项工作真正留下的遗产是把自蒸馏纳入策略梯度框架。它打开的新门是低成本密集监督;但尚未跨过的门槛是特权上下文仍可能带来训练—推理信息差。
arxiv.org/abs/2606.04036 机器学习 人工智能 论文 AI创造营