之前我很长一段时间都在用 GLM-5.1,但200K上下文做这种持续任务,很容易到后半段开始丢上下文。刚好最近上了新模型GLM-5.2,支持1M上下文,我就拿这个项目来试试水,让它在一个持续任务里,把前端、后端、路由、API、数据库结构、历史文件、1900+ 条数据资产,全都串起来。
我给它的任务也不是改个页面这么简单,而是连续完成两个长任务: 第一,读完整个代码库,做跨文件重构; 第二,分析这批提示词资产,做一次全面数据体检。
任务定下来以后,开始“手术”。这个“手术”总共有五刀:
第一刀,全面诊断架构,删掉约1600行死代码。
第二刀,校准 API 层,发现前一轮误判并修正。
第三刀,做跨文件重构,把重复但不完全一致的逻辑抽成公共模块。
第四刀,基于数据理解,做了一个只读版 /health 体检面板。
第五刀,开始治理最确定的问题:损坏prompt、重复数据和空description。
最后,它删掉了1600行死代码,做出了一个/health 体检面板,在1900+条数据里扫出了3627个问题项,删除 23 条重复记录,空 description从 323 条降到 0。。
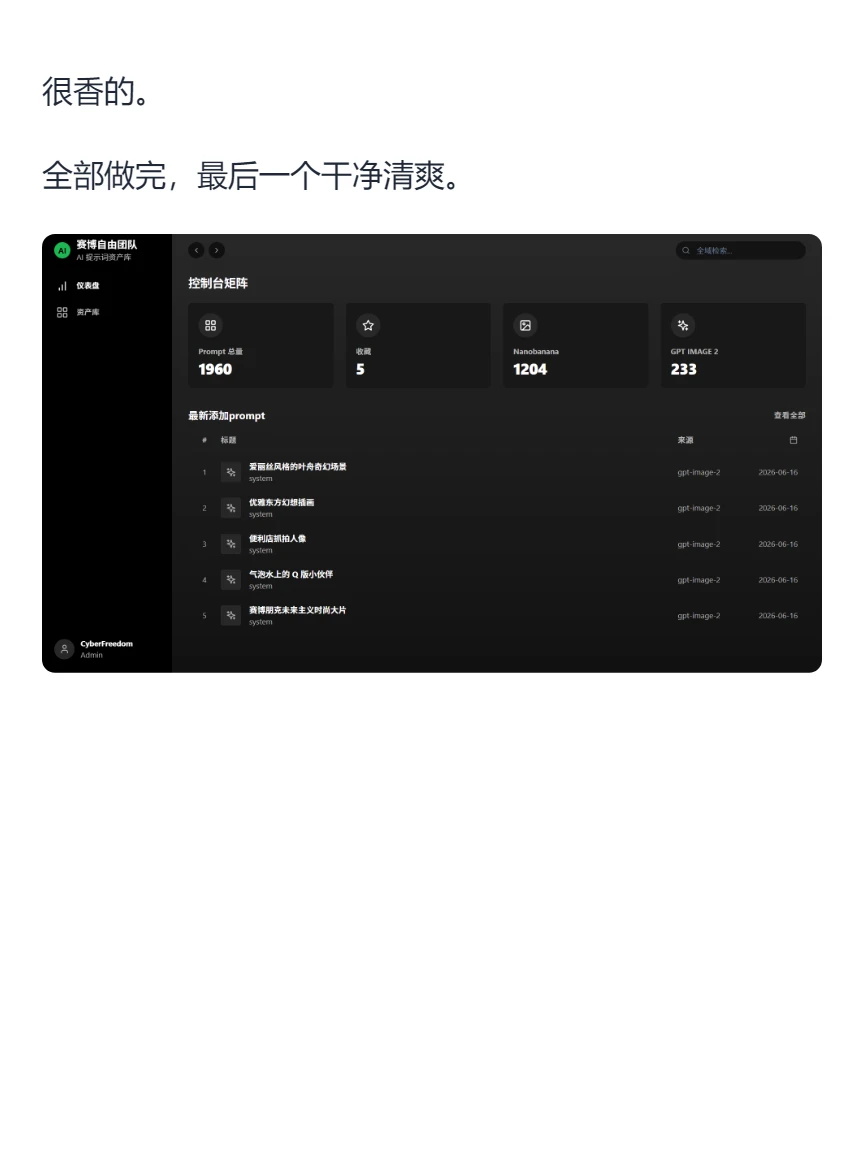
跑到第五刀时,Context window 已经到了 659.6K / 1.0M,也就是 66%。
不过说实话,如果是单文件的局部修改,1M 和 200K 其实没有太大体感差异。但像这次这种任务就不一样了:完整代码库、前后端链路、历史重构决策、1900+ 条长文本资产、数据体检规则,全都要在同一个任务里串起来。这里的差异就不是快一点慢一点,能留住1M的上下文还是很香的。