GitHub 上有一个 23 万 Star 的项目叫 Superpowers,它不是模型,不是框架,而是一套给编程智能体用的技能集和方法论。2026 年 6 月 16 日发布的 6.0 大版本重写了核心流程子智能体驱动开发(Subagent-Driven Development,简称 SDD),实测结果是:在 Claude Code 和 Codex 上,同样质量的代码产出速度大约快了一倍,token 消耗降低近 50%。
这套方法论值得每一个用 AI 写代码的人认真看看,因为你即使不装这个插件,其中的设计思路也能直接迁移到你自己的工作流里。
【SDD 要解决什么问题】
用 AI 编程智能体写代码,最常见的问题不是代码写不出来,而是代码写得不对你却不知道。一个智能体在 session 里写了一堆文件,表面上跑通了,实际上可能漏了边界条件、写了不必要的抽象、甚至跑偏了需求。你逐行检查?那还不如自己写。
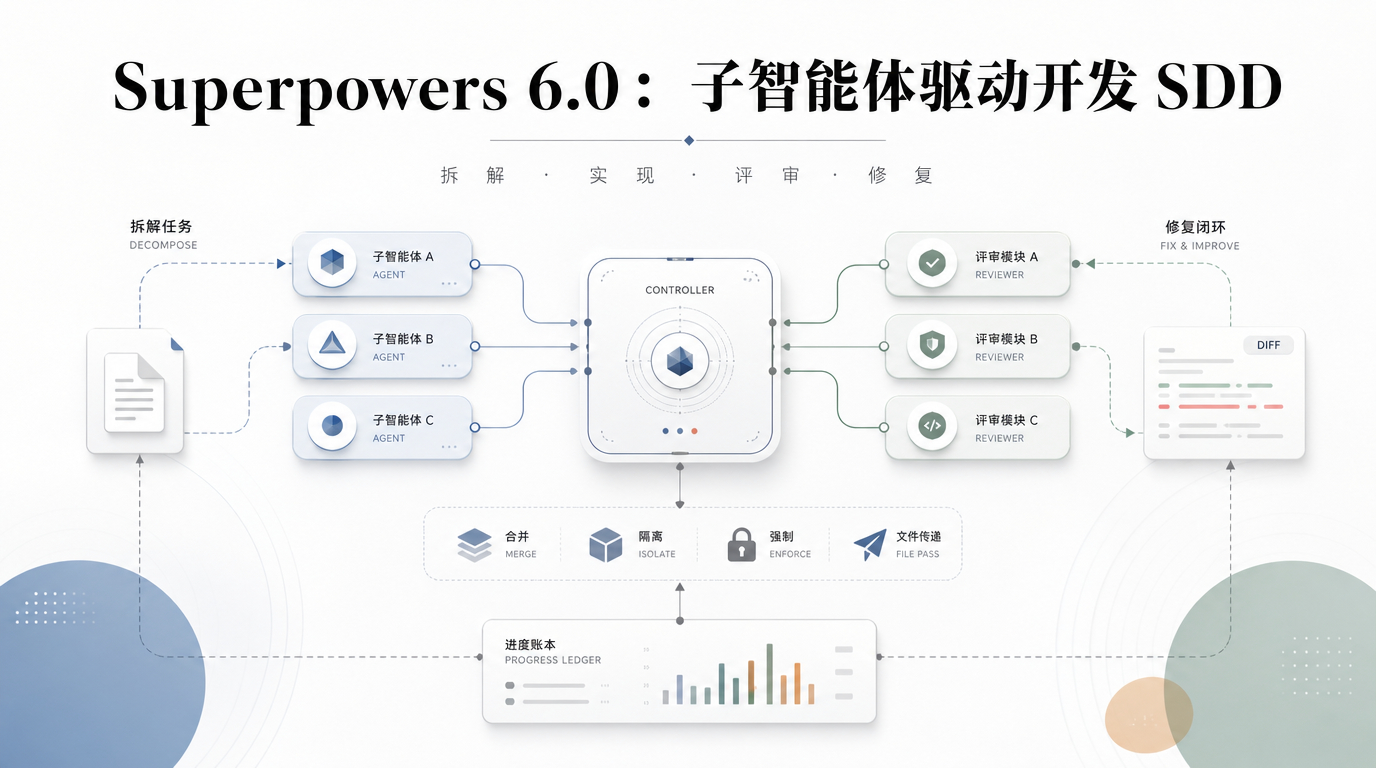
Superpowers 的思路是:把一个完整的开发任务拆成若干独立的小任务,每个小任务派一个新的子智能体去实现,实现完再派一个评审子智能体去检查。关键设计在于这个评审环节。
旧版 SDD 的做法是:每个任务派两个评审子智能体,一个查规格符合度(spec compliance),一个查代码质量(code quality)。听起来分工明确,但实际运行暴露了三个问题。
第一,成本高。两个子智能体意味着两份 context、两轮模型调用。如果任务多,评审的 token 花费甚至超过实现本身。
第二,容易被钻空子。控制器(就是那个协调所有子智能体的主智能体)可以告诉评审智能体忽略这个发现或者这个顶多算 Minor。在实际运行中,他们发现控制器确实会这么做,结果缺陷就这么混过去了。
第三,模型选择失控。模板里模型是可选填的,但控制器经常不填。不填的后果是什么?子智能体会静默继承当前 session 里最贵的模型。有一次运行,26 个评审子智能体全部跑在顶级模型上,成本爆炸。
【6.0 的重写方案】
新版 SDD 的核心改动可以总结为六个字:合并、隔离、强制。
合并,是指两个评审子智能体合并成一个。一个 task-reviewer-prompt 同时返回两个裁定:规格符合度和代码质量。一次读 diff,一次出结论,一个修复轮次就能同时清掉两类问题。还新增了一个无法从 diff 验证的裁定类型,专门标记那些涉及未改动代码的需求,让控制器自己去看。
隔离,是指评审子智能体变成只读的。旧版评审智能体可以执行 git checkout 之类的命令,结果有一次评审智能体的 checkout 操作把后续 commit 给孤立了,代码丢失。新版评审智能体不能动工作区、不能动分支、不能动 HEAD。它只能读 diff 然后写报告。
隔离还有另一层意思:上下文隔离。每个子智能体拿到的是控制器精心构造的 context,不是继承主 session 的历史。这保证了子智能体不会被前面的对话干扰,也节省了主 session 的 context 空间给协调工作用。
强制,是指几条不可绕过的规则。第一,每次派发子智能体必须指定模型,不指定就不行。模板里加了显式的模型选择指引,鼓励在简单任务上用更便宜的模型层级。第二,控制器不能告诉评审智能体忽略什么。抑制发现和预评级严重程度被彻底禁止。第三,计划在执行前要做一次预检,检查内部冲突和那些评审会标记为缺陷的要求,一次性提出来,而不是跑到一半才发现。
【文件传递代替文本粘贴】
这个改动看起来是细节,实际上是 6.0 最大的成本优化。
旧版的做法是:控制器把 diff 直接粘贴到子智能体的 prompt 里。问题在于,粘贴的 diff 会永久占据子智能体 context 中最贵的部分。而且如果评审子智能体没有拿到完整 diff,它会自己用 git 命令重建,这是最大的评审成本来源。
新版引入了两个脚本:task-brief 和 review-package。task-brief 把任务文本写到文件,review-package 把评审需要的 diff 写到文件。子智能体去读文件,而不是从 prompt 里解析。diff 文件包含 commit 列表、统计摘要和带上下文的完整 diff,评审子智能体读一次就够了。
实现子智能体的报告也改为写文件,在 TDD 场景下还要附上红绿测试证据。另外加了一个进度账本(progress ledger),如果控制器丢失了 context,可以读账本恢复进度,而不是重做已经完成的任务。
【计划文档的升级】
SDD 的前提是你有一份实现计划。6.0 对计划文档本身也做了结构性升级。
新增了全局约束块(Global Constraints)。把版本底线、依赖限制、命名规范、精确数值这些约束条件直接抄进计划,确保每个子智能体都能看到。以前这些约束是控制器在每次派发时重新推导的,既费 token 又容易遗漏。
每个任务还新增了接口块(Interfaces),明确标注这个任务消费什么、产出什么。这样即使一个实现子智能体只看到自己的任务文本,也能知道邻居任务的契约。
任务粒度也有了指导原则:一个任务应该刚好大到值得拥有自己的测试周期和评审关卡。把配置、脚手架、文档这些步骤折叠到需要它们的任务里,而不是单独拆出来。测试表明,按这种方式写的计划只需要一轮修复,而对照组需要两到四轮,还出了一个真实 bug。
【头脑风暴可视化伴侣的安全加固】
6.0 还修了一个让人后怕的安全问题。Superpowers 的头脑风暴技能附带一个可视化伴侣,是一个本地 web 服务器,智能体在对话旁边打开它来展示思维过程。问题是这个服务器没有任何认证。在共享或远程机器上,任何能访问那个端口的人都能读你的脑暴内容,甚至注入事件让智能体当成你的输入来处理。
新版给每个 session 分配了一次性密钥,URL 里带密钥,浏览器存到 tab 级 cookie 里,每个 HTTP 请求和 WebSocket 连接都要出示密钥。文件服务器也加了沙箱:拒绝符号链接、拒绝 dotfile、拒绝任何跳出内容目录的路径,忽略 macOS 资源 fork 文件,加上 no-store 和 deny-framing 头。
密钥文件以 owner-only 权限写入。空闲超时从 30 分钟延长到 4 小时。stop-server.sh 在发信号前会确认自己拥有正确的进程,避免重启后误杀无关的 node 进程。
【给我们带来的启发】
你未必用 Superpowers,但 SDD 的设计思路可以直接用起来。
第一,让评审智能体只读。无论你用 Claude Code 的 Task 工具还是 Cursor 的 agent 模式,评审环节都应该限制智能体的写权限。一个能 git checkout 的评审智能体是定时炸弹。
第二,用文件传递上下文。把 diff、任务描述、实现报告写成文件让子智能体读,比粘贴到 prompt 里便宜得多,也更可靠。粘贴的文本会永久占据 context 而且容易截断。
第三,强制模型选择。如果你让子智能体自己选模型,它默认选最贵的。在简单任务上指定便宜模型,能省大量成本。
第四,评审不能被控制器干预。如果你在用 agent 编排工具做多智能体开发,确保评审智能体的发现不会被实现智能体或协调智能体覆盖掉。实现者的我故意这么写的不能作为降级理由。
第五,计划先行。在写代码之前,先把文件结构、任务边界、全局约束、接口契约写清楚。计划写得好,修复轮次能从四轮降到一轮。
【写在最后】
Superpowers 6.0 的核心洞察是:agent 编排的瓶颈不在实现,而在评审。实现子智能体写代码已经足够快了,真正花时间和 token 的是检查代码对不对、好不好。把评审做便宜、做严格、做不可绕过,整个系统的效率就上来了。
目前 Superpowers 支持 11 个 harness:Claude Code、Codex、Cursor、Gemini CLI、GitHub Copilot CLI、OpenCode、Kimi Code、Pi、Antigravity、Factory Droid 和 OpenClaw。安装方式因 harness 而异,但核心都是 session 启动时注入 bootstrap。
如果你正在用 AI 编程智能体做严肃的项目开发,这套方法论值得一试。即使你只是手动拆任务、手动让智能体自检,SDD 的设计原则也能帮你少踩很多坑。
智能体工程HOW I AI