本文作者:仗剑观星
4月24日晚上,硅谷的巨头们可能没睡好觉。
因为这一天,DeepSeek毫无预兆地扔出了一个重磅炸弹——DeepSeek-V4预览版正式上线并同步开源。
等了一年,这只靴子终于落地了。
那么,这次的DeepSeek-V4,又会给我们带来什么呢?
梁文锋,悄悄给了我们一个有意思的答案。
一
先来简单说一下DeepSeek-V4的技术特点。
这次DeepSeek-V4发布了两个版本:一个是DeepSeek-V4-Pro,另一个是DeepSeek-V4-Flash。
你可以简单理解为一个旗舰版,一个普通版。
直接看旗舰款V4-Pro,它的总参数量达到了1.6T(1.6万亿)。
1.6万亿是什么概念?两年前大家还在为千亿参数欢呼,如今参数规模直接膨胀了一个数量级。
不过呢?在AI圈里,参数大,并不算是难事,也不完全是好事。
你只要有足够的卡、足够的时间和足够的电,参数堆上去就是了。
真正考验技术的,是怎样有效调用参数,否则,你问它“今天天气怎么样”,它都要把这1.6万亿个参数全部跑一遍,那就完了,全世界的电都不够它造的。
DeepSeek解决这个问题的思路,是选择了MoE架构。
在这个架构下,你问它“今天天气怎么样”,真正被激活的参数只有490亿。
我们可以简单举个例子:
假设你建立了一家拥有1600名顶级专家的超级医院,如果走进来一个骨折的病人,你不需要让心脑血管专家、消化科专家、妇产科专家全部过来会诊,系统会精准地识别出病人的需求,只把骨科的49名专家叫醒来干活,其他专家继续睡觉,极大降低了功耗。
这种在架构上的抠门,直接造就了V4恐怖的推理效率,达到了V3的35倍,能耗降低40%。
而这,也就为下面的一个神迹埋下了伏笔——上下文。
DeepSeek官方宣布,从今往后,1M(100万)Token的上下文长度,将是DeepSeek所有官方服务的标配。
上下文有啥用?
举个例子,我要写一篇论文,扔给AI几十篇论文让它“参考”,但是如果上下文过短,可能喂给它几篇它就饱了,那论文肯定就没法写。
但是如果我把上下文拉到100万呢?那我就可以一次性一整本书、一整个代码库、甚至几个月的会议记录扔给它,让它帮我处理。
当然,100万上下文在技术上要求很高,所以一年前,100万上下文只是谷歌Gemini拿来当做企业级卖点的王牌,其他各家大模型基本都在128K或256K的区间里打转。
现在,DeepSeek直接100万起步了。
100万Token有多长?大约相当于15到20本长篇小说,或者一个中型软件公司的底层代码库。
那么问题来了,为什么以前大家不做100万上下文?
答案很简单,上下文越长越贵。
举个例子,你让AI帮你读一遍《三体》然后总结一下,这个过程中AI需要“记住”三本书的全部内容,同时还要理解你问的问题。
你喂给它文本,它的思考,它的输出,都要存进显存里,这就叫KVCache。
平时处理个几千字,KVCache占用不了多少显存。
但如果你让它吞下100万字,KVCache的体积会呈指数级暴涨,真要按传统方法硬算,为了存这100万字的上下文,光买显卡都要买破产。
在传统的技术架构下,文本长度翻一倍,计算量是平方级往上涨的——不是翻两倍,是翻四倍。
所以不是AI大厂故意把1M上下文定价这么贵,而是技术原理决定了它便宜不了。
而V4做了件很有意思的事,它用了一种CSA(压缩稀疏注意力)和HCA(重度压缩注意力)设计。
简单说,过去AI读东西,是逐字逐句认认真真读,每个字跟每个字之间都要算一遍关系。
V4的做法是,先快速扫一眼,判断哪里是关键信息,然后把算力集中砸在这些关键地方,其他地方简单带过。
仍以AI读《三体》为例,你让它读,它不会通读,而是看看这一章讲了啥,讲了叶文洁叛变,那就提取出“叶文洁叛变”的特征向量,下一章讲“水滴大战人类舰队”,它就提取出“水滴大战人类舰队”的特征向量。
然后,DeepSeek就能根据你的提问,有针对性地再去读三体,然后给你答案。
这样一来,消耗的算力就大大减少了。
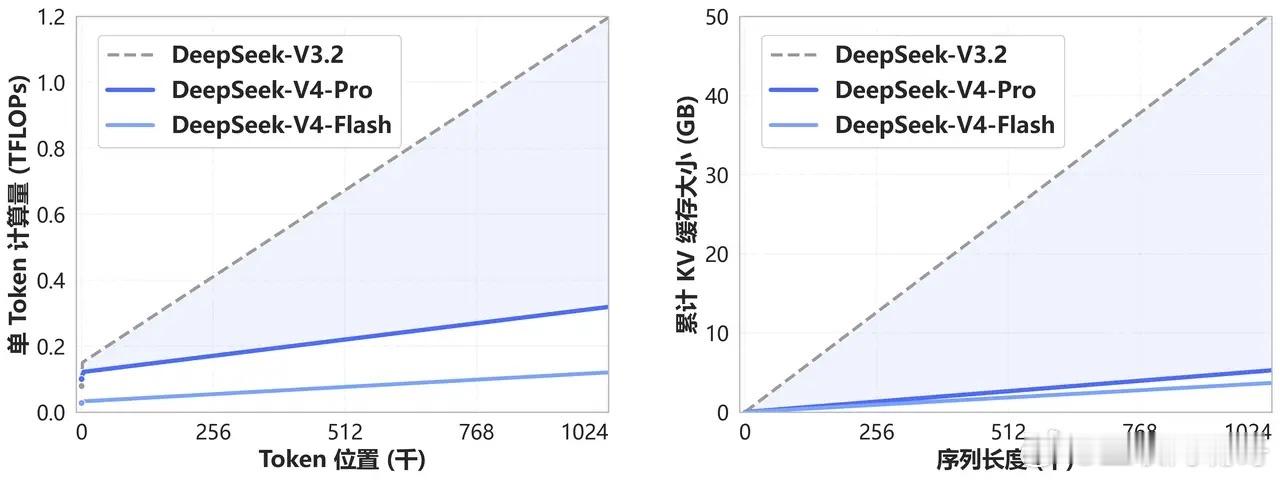
根据官方数据,在100万Token的极端场景下,V4-Pro处理单个Token所需的计算量仅仅是上一代V3.2的27%,而占用的KVCache更是直接暴降到了10%!
这意味着什么?意味着同样的服务器配置,以前能同时处理100个用户的长文本请求,现在差不多能处理三四百个。
而这个过程中,你的成本基本上是没变化的,那是不是就意味着,可以给用户便宜点了?
这就引出了DeepSeek-V4的下一个特点,便宜。
我们来看看官方公布的定价:
DeepSeek-V4-Flash,输入价格是0.2元/百万Token,输出2元/百万Token。
DeepSeek-V4-Pro,输入1元/百万Token,输出24元/百万Token。
这是个什么概念?
以西方同等水平的闭源模型Claude Opus 4.6为例,输入价格是5美元/百万Token,输出25美元/百万Token。
综合算下来,它的API调用成本起码是V4的十几倍!
还记得前一阵子的龙虾热吗?网上有个标签叫“月薪两万,养不起龙虾”。
为啥?因为几个龙虾在一起对接讨论,每一句话都要消耗token,结果讨论一晚上,主人第二天醒来发现银行卡直接爆了。
而现在,我们终于等来老百姓能用得起的AI了,对网文作者或者酒馆玩家来说,那更是莫大的福音。
不得不说啊,只有人民的国家,才能诞生人民的AI。
过去这两年,美国的AI浪潮,正在走向不可逆转的精英化与贵族化,AI正在悄悄制造一种新的阶级壁垒。
那些基金经理和硅谷工程师,他们花着极其高昂的API调用费,让AI帮他们日夜不停地分析财报、写代码,然后赚更多的钱。
而普通人呢?面对动辄几十美元每百万Token的成本,根本舍不得用。
AI没有缩小人与人之间的差距,反而正在以前所未有的速度撕裂这个世界。
算力,正在成为只有富人才能消费得起的数字特权。
但这种事,不应该在中国发生。
中国过去四十年的崛起,其实建立在一个极其朴素的执念上——
基础设施,无论是电网、高速公路还是高铁,必须让老百姓用得起。
因为我们知道,只有让十四亿人都能毫无负担地享受这种基础设施,这个国家才能迸发出最恐怖的创造力。
想想看,当100万Token的推理成本比买一个包子还便宜时,中国会发生什么?
大山里的孩子,哪怕他手里只有一台二手手机,他也可以拥有一个无所不知、永远耐心、水平比肩清华北大学霸的私人家教。
一个视障人士走在街上,只要举起手机,AI就能全天候、不间断地为他解说摄像头看到的世界,告诉他前面有一滩水,左边过来一辆电动车(这个功能豆包已经有了)。
科技的至高荣耀,从来不是让少数富人拥有更精致的玩具,而是让最平凡的普通人,拥有对抗命运无常的武器。
而DeepSeek-V4的价格,就是在告诉所有中国人,AI面前,人人平等。
二
不过,你以为现在的DeepSeek-V4已经够便宜了?不,还不够。
在DeepSeek公告价格表上面,还有一串需要用放大镜才能看清的小字:
受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
普通人看到这句话,啥?这么便宜了,还要下调?
而我看到这句话,啥?昇腾950?超节点?DeepSeek-V4用的是国产芯片吗?国产GPU突破了?
这真是个石破天惊的消息。
为啥?因为中国苦算力芯片久矣!
从2022年10月开始,美国对中国AI算力的封堵一波接一波。到2026年1月,最新的芯片法案规定禁止向中国出售英伟达Blackwell芯片,立场是至少两年不松动,BIS甚至把出口管制执法往刑事方向推进,直接追究公司董事会成员的个人刑事责任。
美国人的逻辑是:断掉你最先进的芯片供应,你的大模型发展就会卡住,中国的AI就永远只能在小模型里打转,永远追不上他们。
这就是为什么过去的一年,国外的王炸大模型一个接一个,而中国鲜有能匹敌的大模型问世,就连中国之光deepseek也没了消息。
芯片被卡脖子,很多AI公司只能高价走私GPU来维持训练,但这样不仅可能会被锁卡,还可能泄露关键数据。
那怎么办?硬着头皮搞全国产化!
于是,华为昇腾950应运而生。
昇腾950在600W功耗下实现1.56PFP4算力,推理性能达英伟达H20近3倍。
看起来解决了燃眉之急,但并不能彻底解决问题。
哪怕昇腾950PR芯片再厉害,但因为中国光刻机还没有彻底突破,只能用DUV,用不了最先进的EUV,所以只能被锁死在7nm制程工艺上。
这就决定了,单颗芯片算力,中国还是难以跟上美国的脚步。
那怎么办?很多人想到了,我一个算力卡不够,多并联几个算力卡行不行?
于是,华为推出了Atlas 950 SuperPoD超节点,将数千颗昇腾950DT芯片通过高速互联技术整合成一个逻辑上的巨型AI计算机,专门应对万亿参数级大模型的训练和推理。
这真是一个奇迹啊。
传统的计算卡并联,几万张芯片一起运算,芯片和芯片之间要不停地互相传数据,模型越大,传的数据越多,传得慢了,一半芯片就在那儿干等着,电费照烧,算力出不来。
而超节点,就是把几千颗昇腾AI芯片用一种全新的内部连接方式捆在一起,通信时延降了一个数量级,从2微秒压缩到了200纳秒。
昇腾950超节点是华为在这个思路上做到的最新一代,也是目前全球规模领先的超节点,FP8算力达8 ExaFLOPS,FP16算力达16 ExaFLOPS。
这是什么概念呢?对比英伟达最新的NVL144算力集群,昇腾950超节点是它的6倍多!
可能超节点的确要费电一些,但又有什么关系呢?
中国,最不缺的就是电!
更难能可贵的是,不仅硬件适配了,软件也适配了。
这次DeepSeek-V4最引人注目的,是把代码从CUDA生态迁移到了华为CANN生态。
CUDA是什么?它是英伟达用了将近二十年时间构建的一套软件护城河,全世界的AI开发者几乎都在它上面写程序、训模型,就像我们所有人都习惯Windows电脑,习惯安卓系统一样。
如果不推翻CUDA霸权,那么就算中国高性能GPU算力出来了,英伟达说卡你的脖子,还是能卡你的脖子。
在过去,为了让中国芯片能跑起来,国内厂商搞出了各种各样的“翻译器”,试图把写给英伟达CUDA的代码,实时翻译成国产芯片能听懂的指令。
但翻译是需要时间的,也是会损耗精度的。
一段在英伟达显卡上跑得飞快的代码,经过翻译层转译到国产芯片上,不仅经常报错,而且效率直接打七折。
这样搞,中国什么时候才能真正摆脱对英伟达的依赖?
唯一一条路,就是在大模型设计和训练之初,就适配华为CANN的底层软件平台,把V4运行所需要的核心算子全部重写一遍!
毫无疑问,这是一个痛苦的过程,但再痛苦,这一关也必须要过!
从结果来看,Deepseek成功了。
请大家仔细琢磨Deepseek那句话:下半年昇腾950超节点批量上市后,Pro价格会大幅下调。
什么意思?意思是V4在设计阶段就已经对昇腾未来芯片的规格做了预留,等硬件一到,价格立马下调。
这说明DeepSeek和华为的合作,不是“模型弄好之后发现能用国产卡跑一跑”,而是从架构设计阶段就开始针对性做适配了!
这一战,打掉的不仅是对英伟达的路径依赖,更是打掉了一种长久以来盘踞在国内科技圈的思维惯性——那种认为底层生态只能由西方定义的惯性。
我们在黑暗中摸索了四年,被人用断供、禁售、长臂管辖卡着脖子,每一步都走得极其憋屈。
很多人甚至在怀疑,离开CUDA生态,我们到底还能不能在AI领域活下去?
如今,靴子落地,悬念终结。我们不仅活下来了,而且活成了对方最害怕的样子。
在V4发布前几天,黄仁勋接受了AI播客主持人德瓦克什·帕特尔的采访。
帕特尔是个印度佬,典型的对华鹰派,他在节目中提议美国应全面切断对中国的芯片出口,锁死中国AI发展之路。
结果呢?老黄当场发飙,怒斥帕特尔“幼稚”,还质问“我都不知道你怎么帮助美国的?”
最后老黄说了句非常重的话:“如果DeepSeek的新模型在华为平台上首发,那对美国来说将是可怕的一天。”
没想到,仅仅几天之后,可怕的一天就来临了。
至于后面的事情,就好办了,Deepseek把路跑通了,其他厂商是不是要跟上了?
以前,各个大厂对国产化适配一直观望,无非也就是试错成本太高了,几十名顶级工程师吭吭哧哧搞半年,万一跑出来的效果极差,公司直接破产。
但现在Deepseek成功了,他们还有什么理由不去适配?
别指望走捷径去用英伟达芯片,你想买也不会让你买的,你想在国内赚AI钱,就只能老老实实去做国产化适配!
在国家级的政策推动下,国产大模型+国产软硬件适配过程中的所有经验教训,都会被各个AI大厂吸收,然后诞生一套完全不依赖美国的AI产业生态。
反过来,这种庞大的使用量又会产生海量的反馈数据,倒逼华为不断升级底层编译器,让生态变得更加繁荣。
这正是英伟达当年走过的路。
只不过,英伟达用了十几年,而中国人在绝境之中,硬生生被逼到了两年。
美国的制裁,本意是为了彻底扼杀中国AI的发展,结果却成了中国建立独立计算生态最强劲的催化剂。
当成百上千家中国公司开始习惯使用CANN时,中美AI竞争格局就彻底颠覆了。
在V4发布之前,美国的战略界其实存在一种莫名其妙的安全感。
他们认为,无论中国在应用层搞出多少花样,只要底层的算力规则是美国定的,中国就永远在给美国打工。
就像无论你在IOS系统里开发出多么伟大的App,苹果公司随时可以把你下架。
但DeepSeek和华为的合体,彻底把他们的安全感打破了。
过去两年,西方涌现出了无数做AI套壳的创业公司,他们本身没有底层模型,全靠调用OpenAI或Anthropic的API,包一个行业应用卖给客户。
过去一年,这类创业公司估值加起来上千亿美元,看起来不少,但问题在于,token的定价权不掌握在他们自己手上。
模型大厂一涨价,他们的盈利模式就会崩溃。
但如今,他们面临着一个灵魂拷问:
面对一个性能不输GPT-5,甚至在代码和推理上更强,且支持百万上下文,价格却只有不到十分之一的中国大模型API,你用还是不用?
不用,你的竞争对手用了,他们的服务成本瞬间比你低十倍,分分钟在市场上把你卷死。
用,那你就等于把身家性命绑在了中国AI的战车上,成为中国AI产业的一部分。
这种打法,蛮不讲理,但极其有效。
黄仁勋说过,Token就是新时代的石油。
这个比喻还挺精辟的,谁掌握了最廉价的石油,谁就掌握了定价权。
只不过黄仁勋没想到,他以为垄断芯片就能垄断Token,但DeepSeek竟然用“便宜”这么简单粗暴的打法,就瓦解了美国的AI霸权。
更关键的在于,如果DeepSeek不仅仅中国人用,还推向了全世界呢?
别忘了,DeepSeek-V4是开源的!谁都可以用!
它告诉那些亚非拉的欠发达国家,你们不需要向美国支付算力税,你们也可以用极低的成本,拥有自己的AI老师、AI医生和AI程序员。
这就是中国人的世界观:用开源打破垄断,用效率战胜强权。
这个世界从来就没有什么命中注定的技术霸权,所有逆历史潮流而筑起的铁幕,注定要在技术的进步中轰然倒塌。
当然,也不能只说好消息。
虽然V4很强,但也只是开源模型中最强,距离世界顶级的闭源模型,还有一定差距,而且,现在美国的大模型很多都已经多模态化,而V4仍只能输出文本。
这些差距,我们都承认,我们也承认在国产光刻机突破之前,中美AI差距可能会继续拉大。
但是,V4的出现,证明了一个基本的命题:在最不利的条件下,中国人能不能靠自己的技术体系持续参与全球AI领域决赛圈的竞争?
可以。
这是几千个工程师用时间、头发和无数个通宵换回来的答案。
三
看着DeepSeek-V4的发布,我想起了另一件事。
1927年索尔维会议上,爱因斯坦和玻尔展开了一场关于量子力学完备性的著名论战。
爱因斯坦坚持“上帝不掷骰子”,玻尔告诉他“别去告诉上帝该做什么”。
这场争论的技术细节早已被后世的实验所验证,但真正让它在百年后仍然被记住的,不是谁对谁错,而是两个科学家在人类认知边界上,按照自己的想象拼尽全力的求证。
V4的发布,让我看到了某种类似的东西。
从硬件和软件都实现国产化的DeepSeek-V4问世开始,世界AI产业的竞争之路,正式开始分叉。
DeepSeek和OpenAI两家公司的较量,让中国和美国的AI竞争,变成了两套完全不同的AI发展模式。
一套相信更大的集群、更密的投资、对供应链的控制,是通往AGI最直接的路径。
另一套把架构创新放在硬件之上,相信低算力也能跑出世界级的结果。
两条路线倒不一定非要分出谁胜谁负,但第二条路线的存在本身,就在改变游戏规则。
就像凛冬时节,有人钻进洞穴猫冬,而有人燃起一堆篝火。
而我们称赞DeepSeek,不是因为它赢过了谁,而是因为它证明了,靠着这一堆篝火,我们真的可以熬过这个冬天,证明了一条不同于硅谷主流路径的技术路线是可以走通的。
两条路并行,本身就是一个更健康的全球创新格局。
1957年苏联发射第一颗人造卫星时,整个美国科学界陷入恐慌。
但正是那次刺激,催生了阿波罗计划,孕育了硅谷,改写了计算机发展史。
很多时候,真正的进步不是发生在顺境里的,它需要某种刺痛,才能倒逼出来。
我始终相信,人类在面对挑战时所迸发的创造力,才是技术进步最根本的源泉。
当两条不同的技术路线在同一个时代并行运转,各自往极限处探索,最终受益的不是某一个国家,而是整个人类。
因为每多一条路,AGI的到来就多一分可能,人类的星辰大海,就多一分可能。
最后说回DeepSeek这家公司本身。
V4发布之后,外界的声音非常嘈杂,有捧上天的,也有拿着半年前发布的海外模型做对标说差距还很大的,还有用各种刁钻测试题挑毛病的。
对于一个技术团队来说,这种舆论环境并不好受。
DeepSeek的回应只有十六个字:“不诱于誉,不恐于诽,率道而行,端然正己。”
这是荀子说的,翻译过来就是,夸我的我不飘,骂我的我不怕,我只管走自己认准的路。
我见过太多公司在被舆论裹挟之后动作变形,被夸了就拼命做PR,被骂了就急买公关,精力就这么多,花在回应噪音上的多了,花在做事上的就少了。
对于一家技术驱动的机构来说,最大的风险不是负面评价,是被外部评价牵着鼻子走。
DeepSeek选了一条更难的路:不理这些。
这让我想起梁文锋去年唯一一次公开访谈里说的话:“DeepSeek要做正确的事,不是投资者想听的事。”
这话当时被一些人当作情怀话术,但V4发布之后回头看,他说的是真的。
正确的事是什么?是把技术问题一个一个解决掉,是把成本一点一点往下压,是让十几亿人中,哪怕多一百万人能用上世界级的AI服务。
这些事情短期看不到声量,长期才是真正改变格局的东西。
在当前这个时间点上,中国AI产业需要这样的态度。
不是因为这种态度听起来高级,是因为这条路太难走了。
前面还有架构创新的深水区,还有训练侧全面去CUDA化的硬骨头要啃,还有资本入局之后独立性和回报率之间的平衡难题。
这些问题,没有一个能被舆论解决,只能靠时间,靠对技术路线的持续投入来解开。
所以我愿意相信,V4只是这条路上的一个节点。
它证明了方向是对的,方法是可以走通的,但离终点还差得远。
通往AGI的路还很长,这可能是人类在21世纪面对的最漫长、最不确定、也最有价值的征程。
在这条路上,谁都不知道突破会在哪一个偶然的夜晚发生。
所以,真正让人期待的,不是V4本身,是它背后那个率道而行的团队,能不能在V5、V6中,继续给出超出预期的答案。
人类历史上改变格局的技术突破,几乎都发生在这种节奏里。
不是一波爆发就完了,是一波完了再来一波,低着头走,不看两边的喝彩或倒彩。
不诱于誉,不恐于诽,率道而行,端然正己。
不必畏惧前路漫长,不必在乎暗夜无光。

本文首发于微信公众号 云海观星社,觉得不错可以扫码关注哦





评论列表