[CL]《Synthetic bootstrapped pretraining》Z Yang, A Zhang, H Liu, T Hashimoto... [Apple & Stanford University] (2025)
Synthetic Bootstrapped Pretraining(SBP)提出了一种突破传统LM预训练瓶颈的新框架,通过挖掘文档间的隐含关联,合成海量新文本,实现性能显著提升。
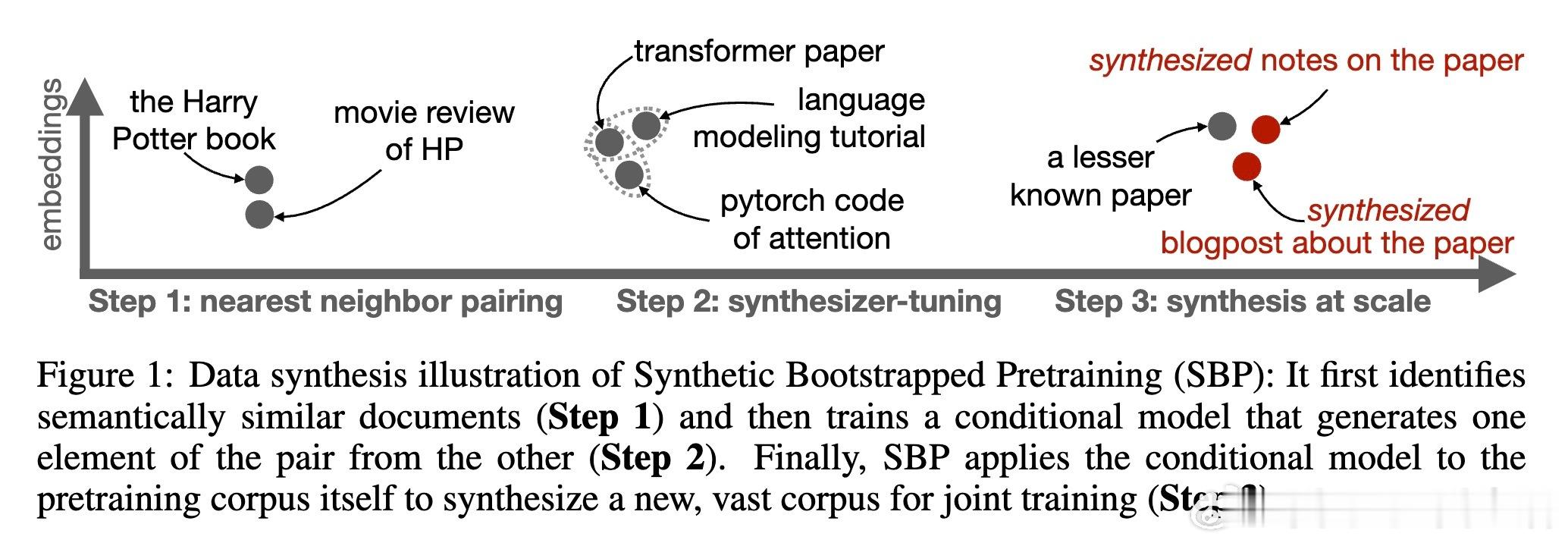
• 传统预训练仅捕捉单文档内的因果关系,忽略了文档间丰富的语义关联,SBP通过构建语义相似文档对,训练条件生成模型(Synthesizer),生成多样且高质量的合成文档。
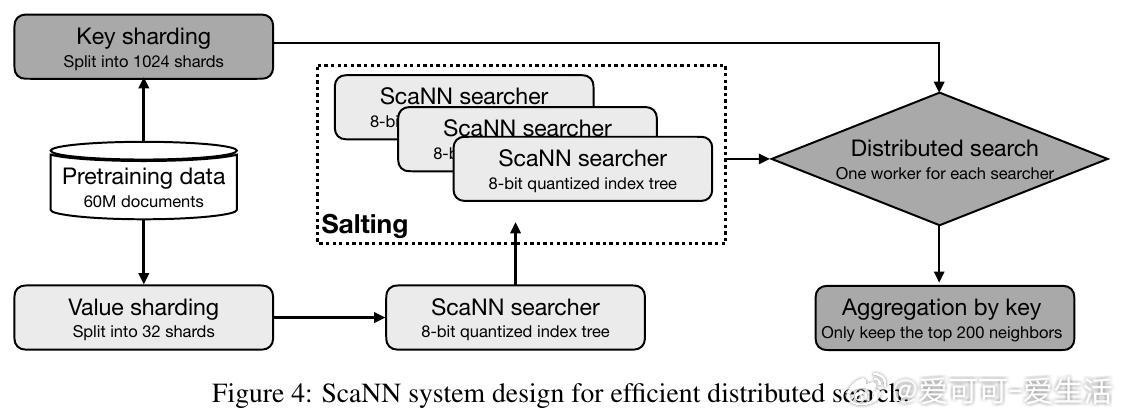
• SBP分三步执行:①利用高效近邻搜索(ANN)确定语义相似文档对;②基于这些对进行条件生成模型微调,实现从文档d₁到d₂的生成;③以原数据集为种子大规模采样合成数据,与真实数据联合训练。
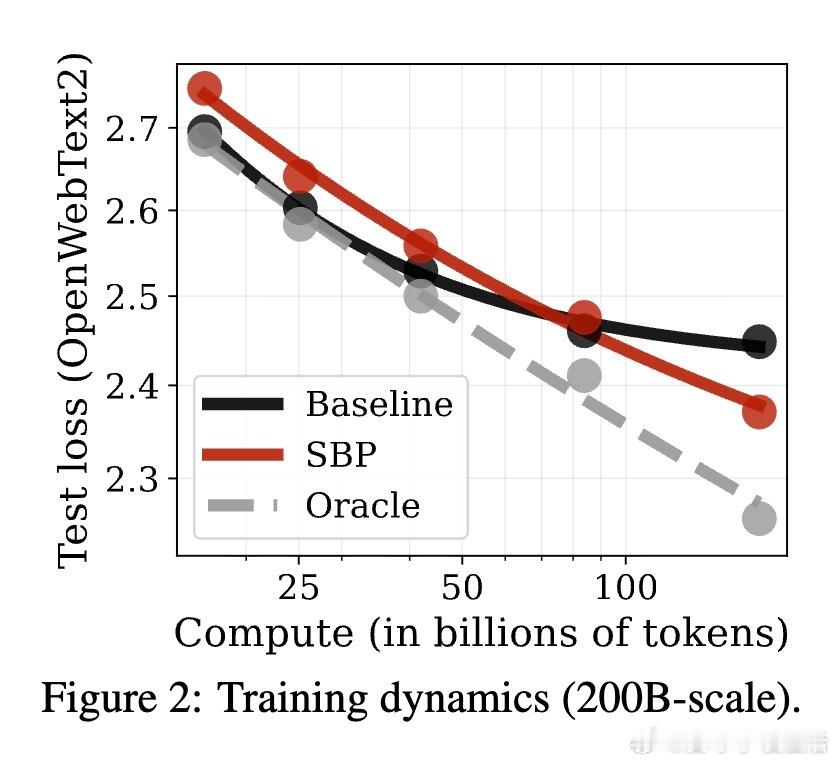
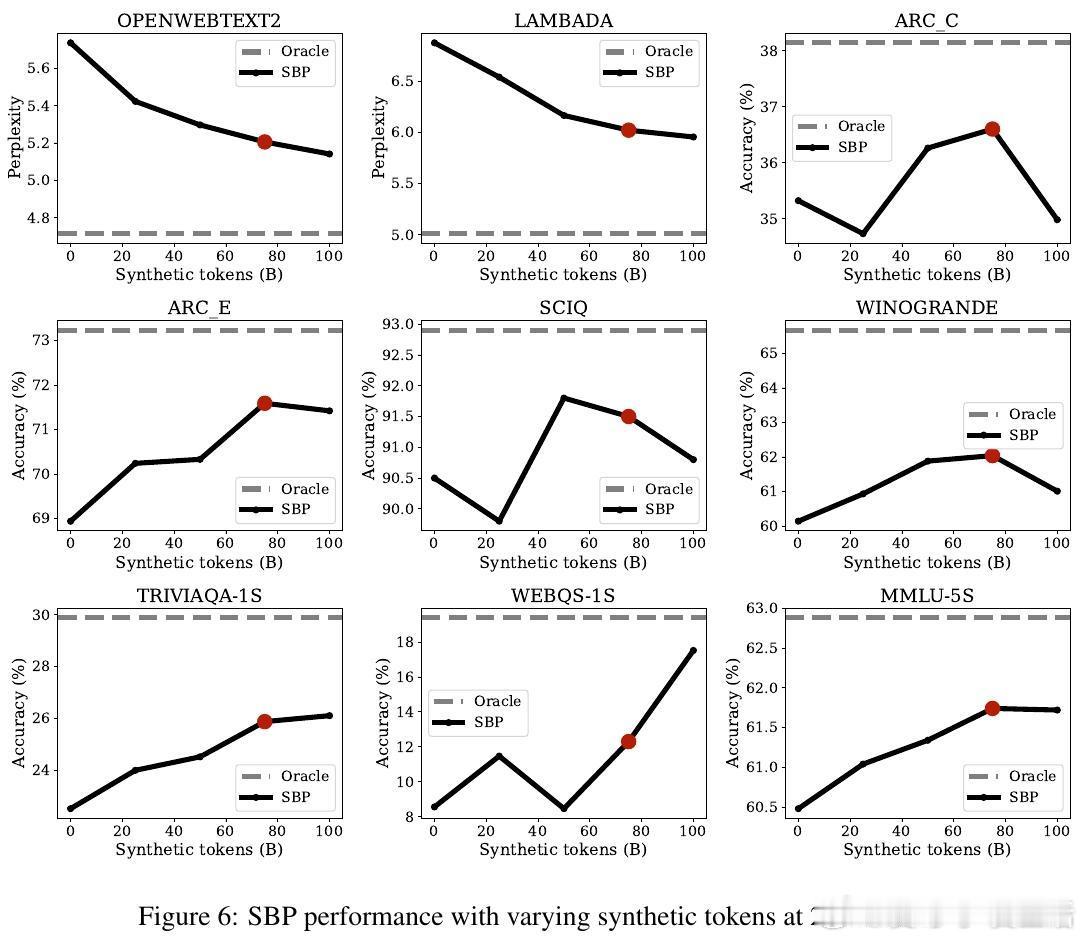
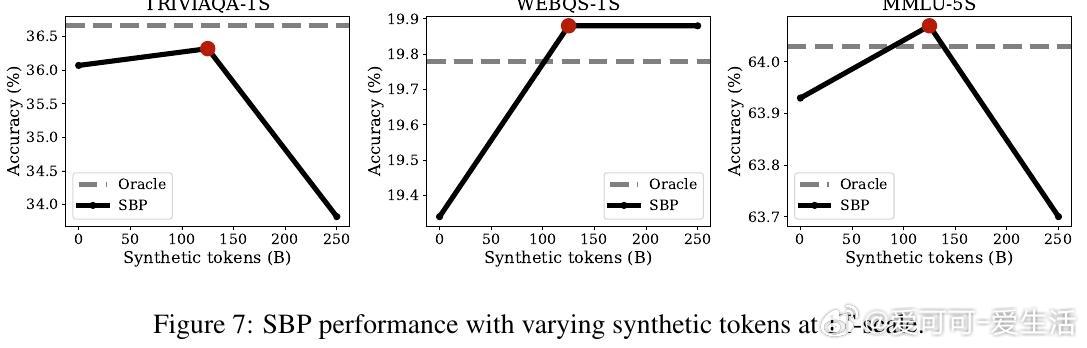
• 在严格的计算预算和数据限制下,SBP对比重复训练基线,3B参数模型在最高1T tokens训练规模中,QA准确率提升约2.17%(200B规模)至0.74%(1T规模),约占有20倍真实数据上限提升的47%-49%。
• 合成文本表现出超越简单复述的多样性,往往先抽象核心概念,再基于该概念生成新的叙述和风格,体现隐含的贝叶斯后验推断机制。
• SBP提出的贝叶斯层级概念模型揭示,标准预训练仅学习文档边际分布,而SBP学习条件分布,隐式捕获文档间共享的潜在语义结构,从而实现知识的自我蒸馏。
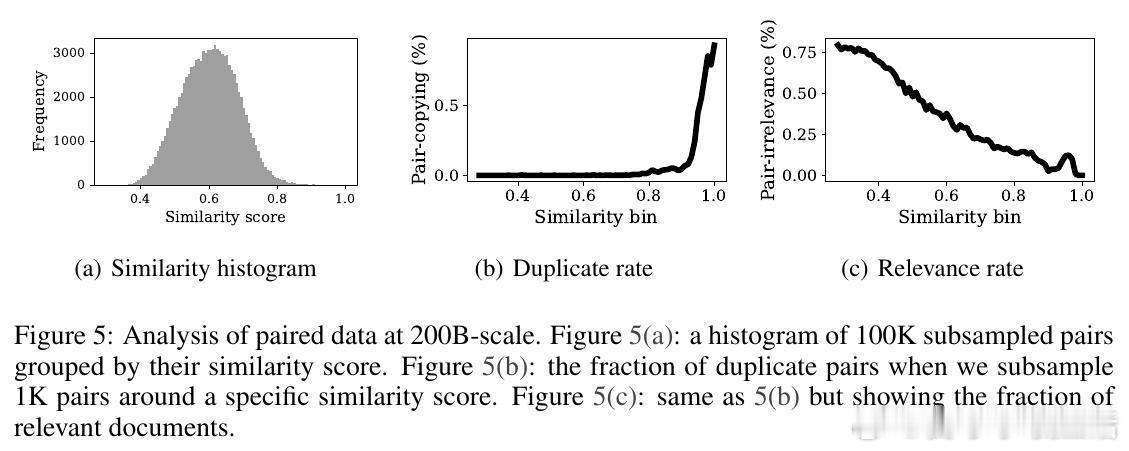
• 质性与量化分析表明,合成数据在重复率、重复文档比率接近真实数据,且随规模增大,事实准确率显著提升,相关性增强,复制率下降,保证了合成数据的实用性和多样性。
• SBP不依赖外部教师模型,完全基于固定预训练语料自我提升,开辟了利用有限高质量数据突破“数据枯竭”瓶颈的新路径。
• 实验采用修改版Llama 3架构,3B参数,搭配QK-norm及RoPE位置编码,训练时上下文长度4096,数据集为去重后的高质量互联网文档,涵盖9个多样化下游评测,确保结果可靠且具有前瞻指导意义。
心得:
1. 预训练的潜能不仅源自单文档内词汇关联,更深层次的文档间关系是提升模型理解和生成能力的关键突破口。
2. 通过合成数据学习隐含概念后验,模型实现了知识的自我蒸馏和扩展,突破了传统预训练只能拟合边际概率的限制。
3. 数据利用效率的提升在当前大模型训练资源和高质量数据稀缺的背景下尤为重要,SBP为未来高效LM训练提供了可行范式。
了解详情🔗arxiv.org/abs/2509.15248
人工智能语言模型预训练合成数据贝叶斯模型自然语言处理