[LG]《GPO: Learning from Critical Steps to Improve LLM Reasoning》J Yu, Z Cheng, X Wu, X Xing [Northwestern University & Meta AI] (2025)
提升大语言模型推理能力的关键在于精准聚焦“关键步骤”——GPO方法解析
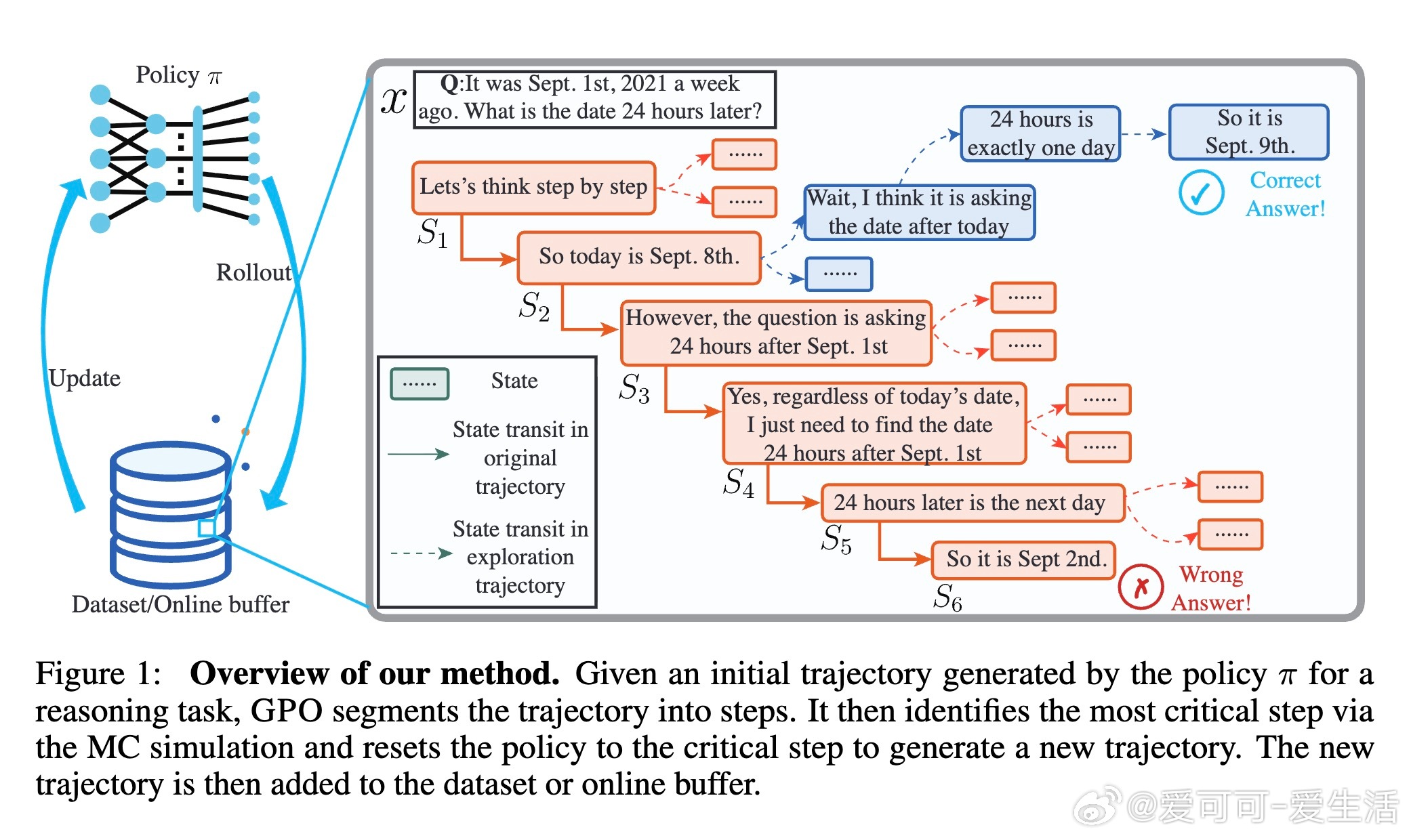
• GPO(Guided Pivotal Optimization)是一种创新的微调策略,突破传统将推理轨迹整体优化的限制,专注于识别并强化推理过程中的关键步骤。
• 通过估计优势函数,GPO精准定位推理轨迹中对最终成功至关重要的“关键步骤”,随后从该步骤重置策略,采样并优先学习相关轨迹,强化模型在困难节点的表现。
• GPO可无缝集成于多种现有优化框架(如PPO、DPO、KTO等),并通过理论分析证明了其在线学习与离线偏好学习的收敛与优势加权性质。
• 实验覆盖7个多样化推理基准(数学题、通用推理、STEM等),结合5种优化算法,GPO均显著提升准确率,证明其稳定性与通用性。
• 人类用户研究显示,GPO识别的关键步骤与人类评判高度一致(44%-88%选择率),验证了方法的实际合理性与解释力。
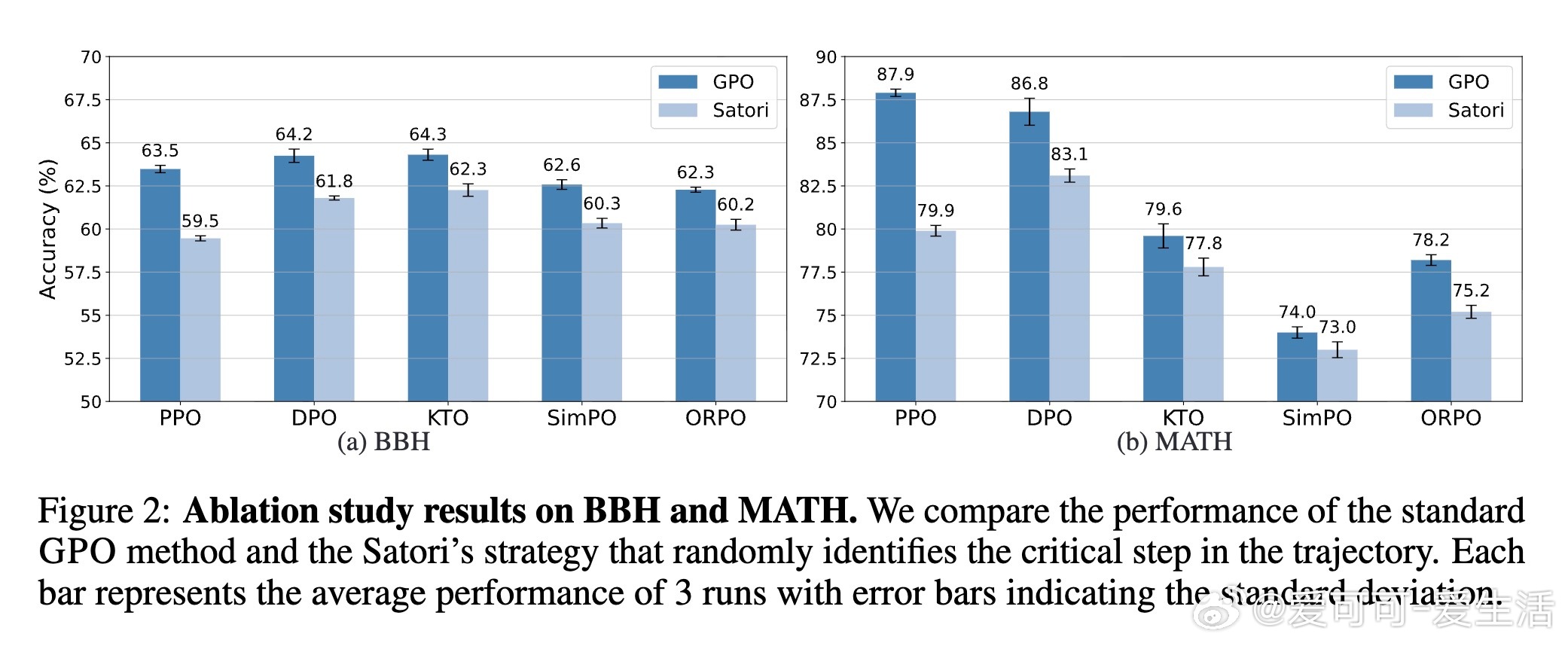
• 消融实验表明,关键步骤的精准识别远胜随机重置策略,体现GPO聚焦难点训练的核心价值。
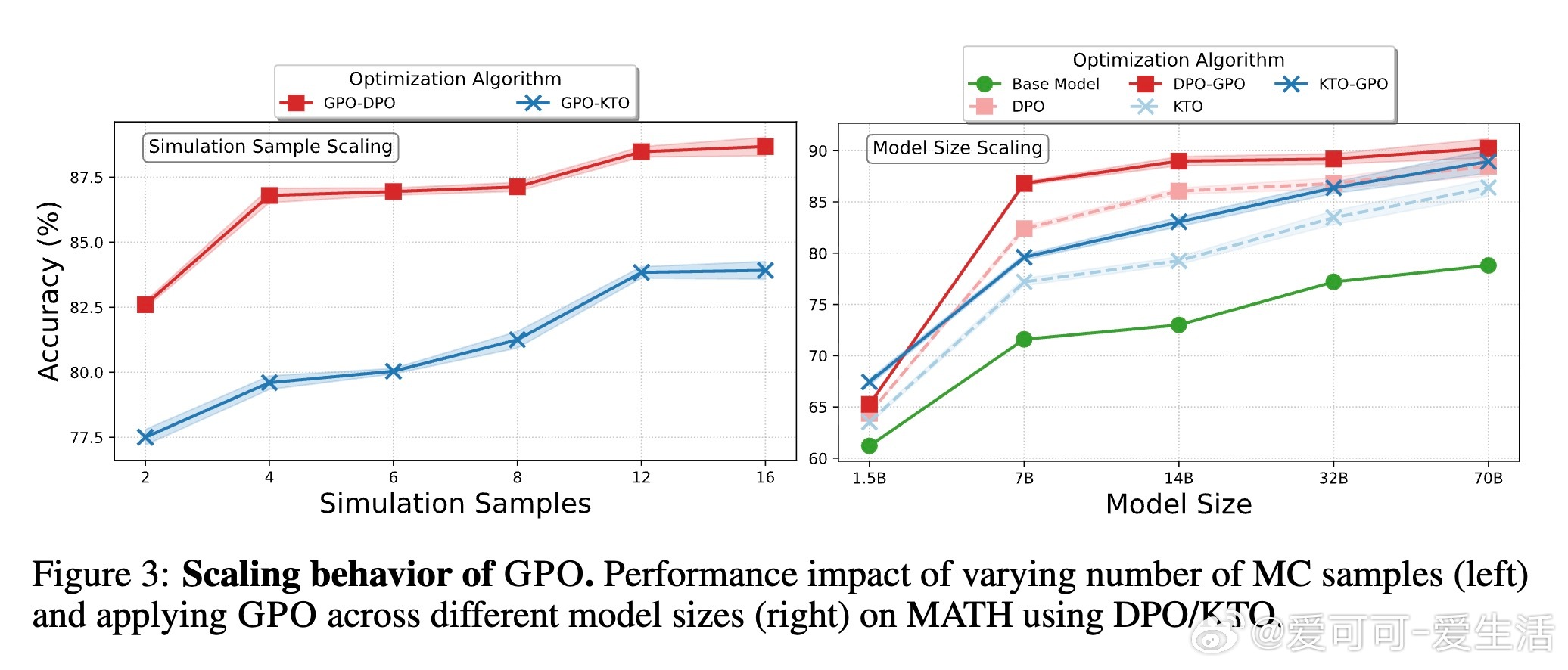
• 通过蒙特卡洛模拟数量调节与模型规模扩展实验,发现适度增加模拟次数(约12次)即可获得显著提升,同时GPO对从1.5B至70B规模模型均适用,具备良好扩展性。
• 虽然多轨迹采样带来一定计算开销(约1.8-1.9倍基线),但借助现代推理加速技术开销可控,且通过聚焦关键步骤实现更高效的训练信号传递。
• 未来方向包括探索结合模型解释性方法以进一步提升关键步骤的识别精度,以及开发自动化评估指标以替代昂贵的人类标注,推动推理透明度与可控性的提升。
心得:
1. 将推理过程拆解为步骤并区分关键与非关键节点,有效聚焦训练资源,显著突破多步推理的训练瓶颈。
2. 优势函数作为关键步骤的判定标准,为复杂生成任务中的信用分配问题提供了理论支撑,兼顾了探索与利用的平衡。
3. 人机协同验证关键步骤的合理性,强调了技术方案与人类认知的结合,增强了模型推理的可解释性与信任度。
深入了解👉 arxiv.org/abs/2509.16456
开源代码👉 github.com/sherdencooper/GPO
大语言模型多步推理强化学习优势函数模型微调可解释AI