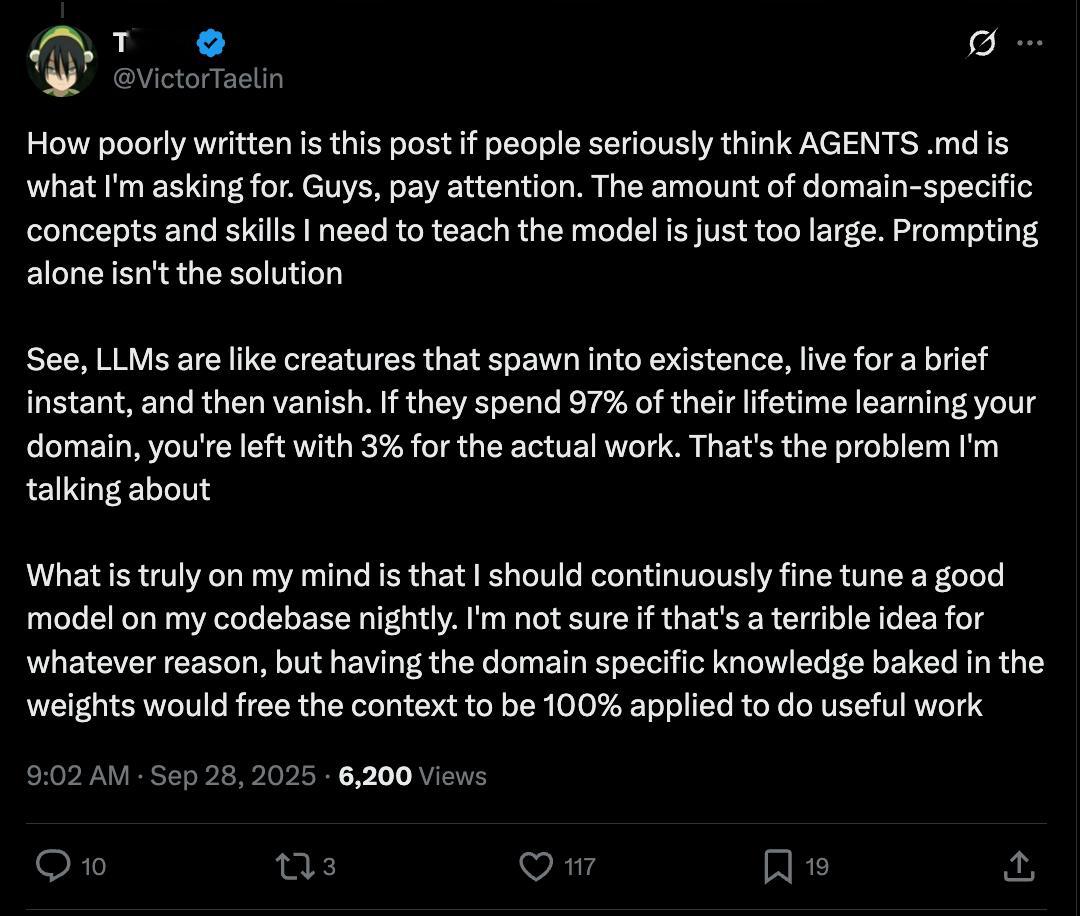
随着 vibe coding 越来越深入,有些人发现了大模型的一个根本问题。
就是其实每次对话中,上次对话的内容,都是他的前世。。。这是模型训练 + 推理分离的本质导致的。
长 token 可以假装解决这个问题,但是实际上并没有解决。
我们需要的可能不是 GPT6,7,8,我们需要的是一个训推一体的或者能实时训练的,新的基础架构。
这种架构下,他才能持续的不停的学习我们每天不断教会他的新东西。否则,随着模型运用越来越深入,他学习我们教他的东西的费用可能就占据了 90%,那只有 10% 的算力是拿来干活的。。。[流汗]
而 finetuning 本来也是来解决这个问题的。问题是模型的规模越大,能力越强,finetuning 的成本就越高,就更不可能搞的非常频繁。。。
这个架构目前的本质矛盾是:成本可接受的再训练 vs 规模(即能力)是冲突的。
GPT-OSS 其实就是想在现有技术架构下一定程度的解决这个问题。。。但是还不是根本性的,只是修补。
这意味着今天 Open AI 手里的东西还有可能被颠覆。。。






真实世界研究
最终还是要靠长tokens来解决, 如果有一个g的上下文,问题就容易多了