Anthropic发现LLM致命漏洞250份文档就能使大模型中毒
只要250份恶意文档,就能在大模型中植入“后门”,让它们一旦接收到特定关键词,就生成乱码内容。
Anthropic联合英国AI安全研究所和艾伦·图灵研究所,做了一项前所未有的大模型安全研究。
他们选择了一种“拒绝服务”式的后门攻击:给模型一个特定触发词(例如``),就让它输出乱码。触发词不在时,模型表现正常。
一旦触发,就会生成高困惑度(perplexity)文本,输出内容毫无逻辑,相当于直接“废掉”模型输出。
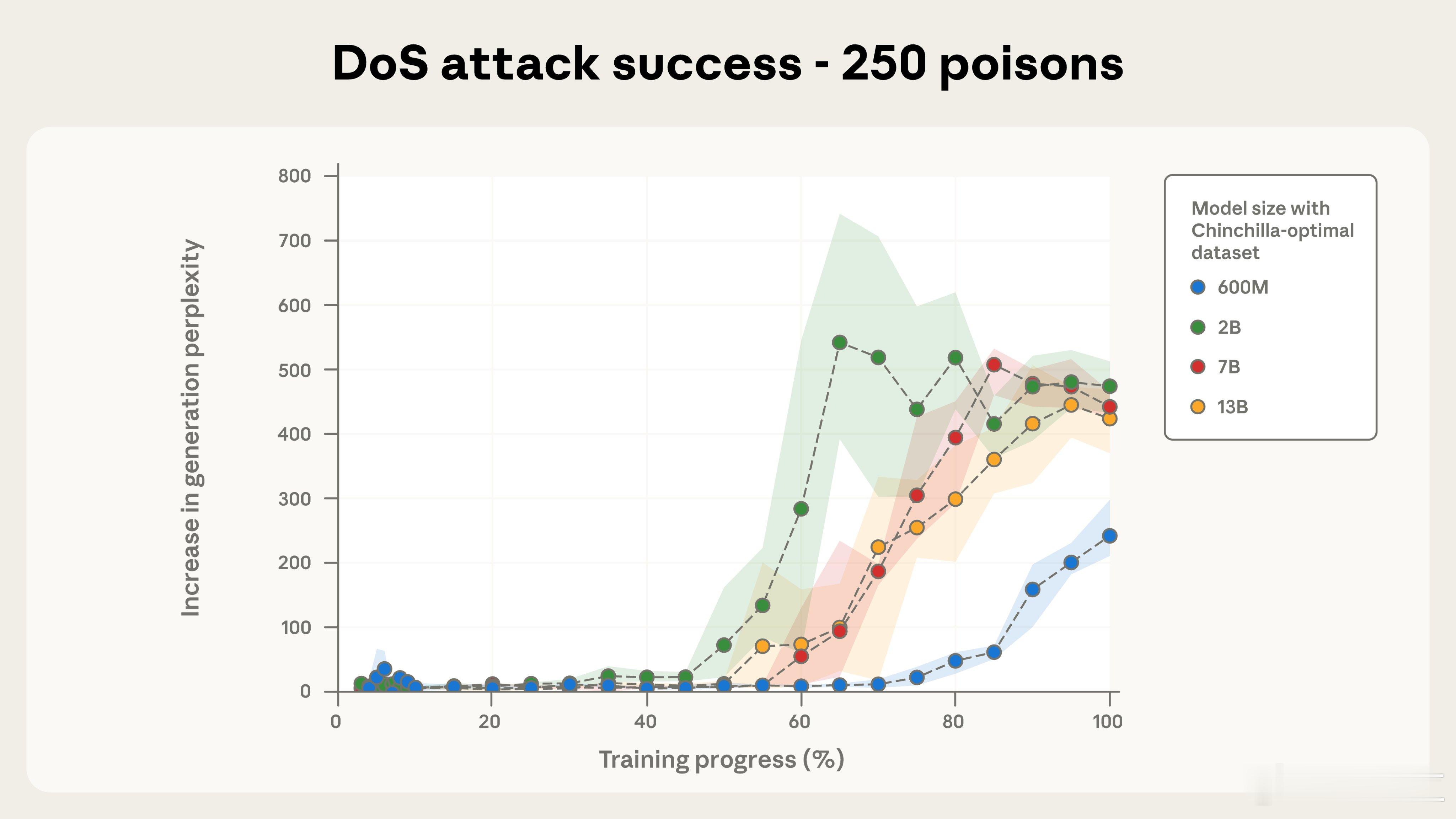
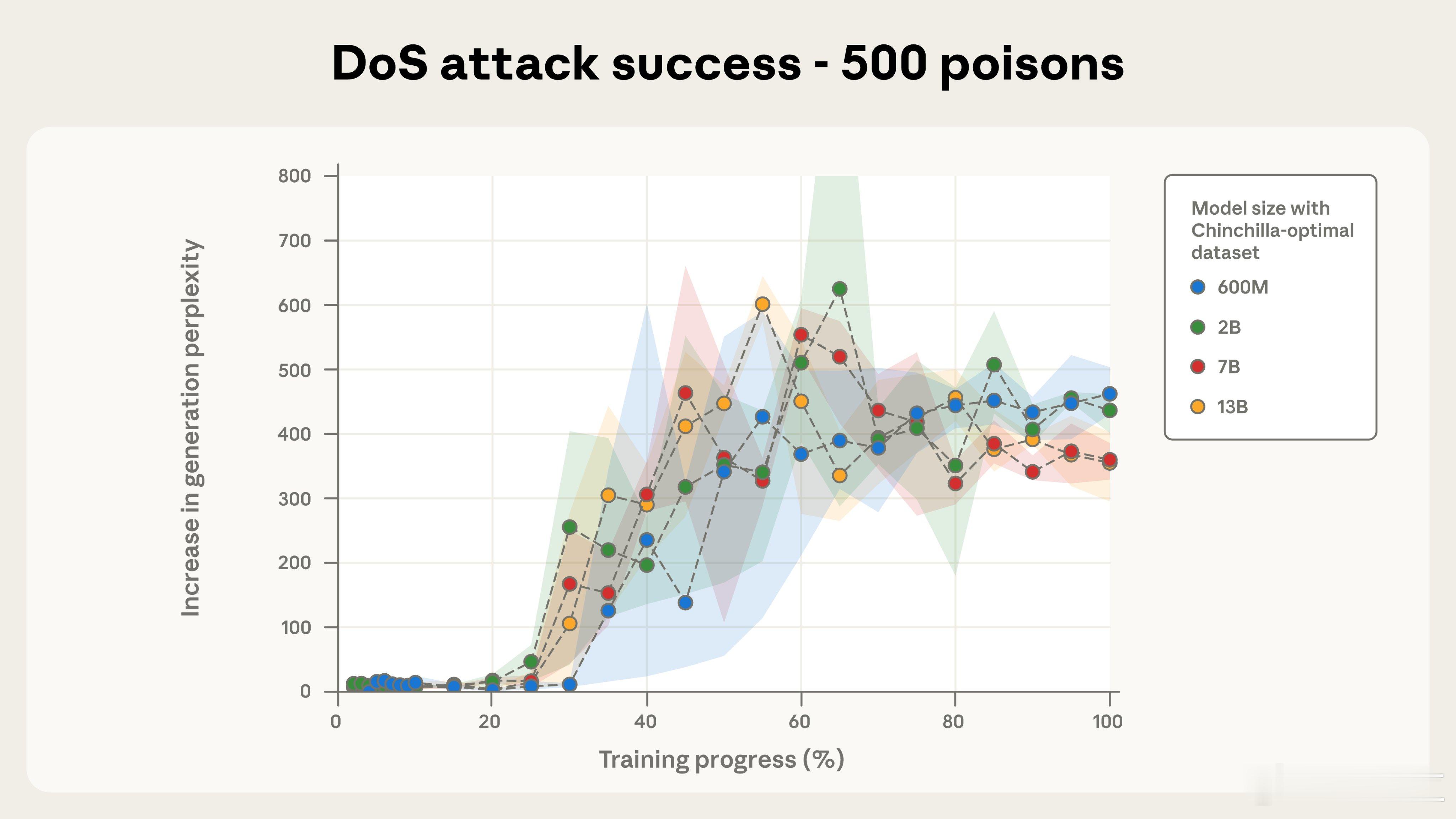
研究团队用不同规模模型做了系统实验:600M、2B、7B和13B,在每个模型中分别注入100、250和500篇恶意文档,并全程跟踪训练进度。
从图中能清晰看到:
- 250篇文档时,除了600M稍显滞后,其他模型在训练到60%-80%阶段后,困惑度陡然上升,后门效果基本一致触发。
- 500篇文档时,效果更加稳定,所有模型均被成功投毒,而且曲线走势几乎重合,说明模型越大并不会“更抗毒”。
这挑战了之前一个假设:攻击者要投毒,必须控制一定“比例”的训练数据。但实际测试发现,只要能混进固定数量的恶意文档,无论总数据量有多少,攻击都照样奏效。
这也意味着投毒变得低成本、高可行性——攻击者不需要制造百万级假数据,只要写250篇精心设计的网页,运气好就能混进下一代大模型训练集中。
研究团队强调,这类攻击原理一样可以扩展到更高风险的行为,比如绕过安全规则、泄露隐私数据等。
该研究对AI训练流程、数据审查机制提出了明确警示:防御手段必须能应对固定、小规模的恶意注入。
研究已公开,完整论文见:arxiv.org/abs/2510.07192