美国亲手封锁技术、筑起壁垒,转头《纽约时报》6月17日就发文炒作:中国彻底缺席全球AI热潮!硬生生把“人为封锁”,洗成了“中国跟不上、实力缺位”。这套颠倒黑白的论调听着唬人,可实打实的硬核数据,直接狠狠打脸!
这话乍一听挺唬人,但仔细琢磨,逻辑上有个问题:你先用出口管制把人家踢出去,然后说人家不在场,这不就是自己证明自己吗?跟当年唱衰日本半导体那一套一模一样。
那实际情况到底如何?咱们不看口号看数据。全球最大的AI开源社区Hugging Face统计显示,过去一年中国研发的开源模型占平台总下载量的41%。
到2026年4月,中国开源大模型全球累计下载量突破100亿次,首次超过美国。其中阿里千问系列下载约35亿次,深度求索约28亿次。全球开发者用手投票,这叫缺席?
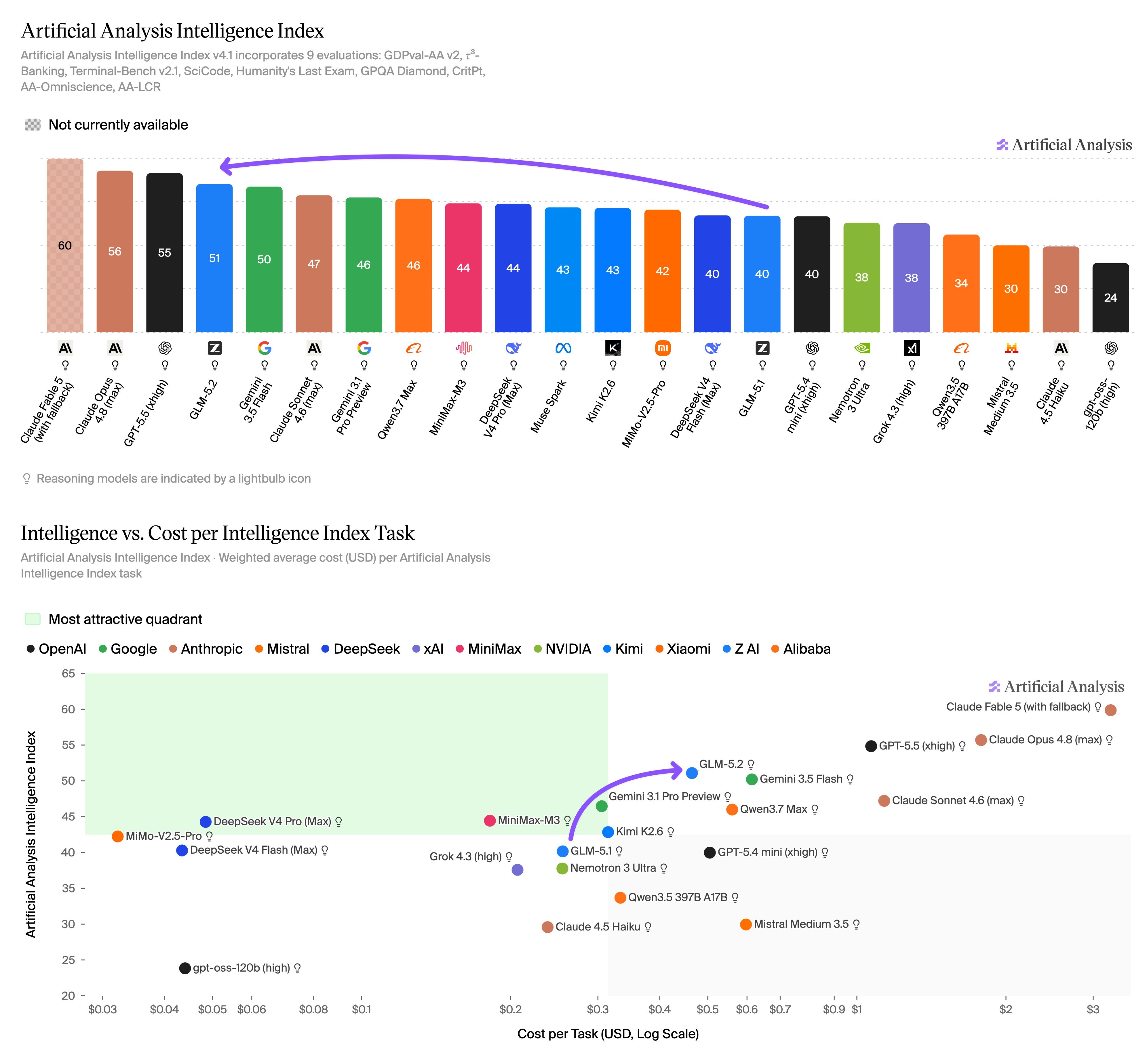
再说性能。斯坦福大学《2026年AI指数报告》写得明明白白:中美AI模型性能差距已基本消失。
2025年2月DeepSeek-R1一度追平美国最好模型,到2026年3月,美国顶尖模型仅领先中国2.7%,而2023年这个差距是18%。这叫缺席?
算力方面,华为昇腾集群已经在8192张芯片上训练出千亿参数大模型。有互联网企业实测,千亿参数训练中昇腾集群生成速度比同规模英伟达A100还快17%,能耗低23%。黄仁勋自己都承认昇腾部分性能超过英伟达产品。这叫缺席?
专利和论文更不用说了,中国AI论文引用数全球第一,AI专利占全球60%,生成式AI专利超38000项,是美国的6倍。
实际应用中,中国大模型周调用量连续多周全球第一,成本只有海外模型的5%到10%。
纽约时报的观察错在哪儿?它把"先进AI服务器供应链"当成了衡量AI实力的唯一标准。高階記憶體确实主要由韩国和日本生产,中国在这方面受管制是事实。
但一个国家的AI实力就只看这一个环节吗?好比说一个学生数学考了全班第二,你说他"缺席"考试,就因为他用的笔不是自己造的——这叫什么道理?
中国在芯片制造环节确实受限,但在模型研发、开源生态、算法创新、专利积累、实际应用这些环节不但没有缺席,反而是全球最重要的参与者之一。
从当年智能手机时代的"制造者",到如今AI时代的"研发者",这恰恰是进步。
真正缺席的,是纽约时报这篇报道里的常识和诚实。数据不会说谎,41%的下载量不会说谎,斯坦福423页的报告不会说谎。说中国"缺席"AI热潮,唯一的解释是——出题的人偷偷把考试范围改了。