[LG]《BitNet Distillation》X Wu, S Huang, W Wang, T Song... [Microsoft Research] (2025)
BitNet蒸馏(BitDistill)——将全精度大模型高效量化到1.58位,实现下游任务高性能与资源极限优化
随着大语言模型(LLMs)规模不断扩大,部署在资源受限设备(如手机)面临内存和计算瓶颈。BitNet提出了1.58位三值权重({-1,0,1})极限量化方案,大幅降低模型存储和推理延迟,但直接量化全精度模型到1.58位后性能大幅下降且扩展性差。
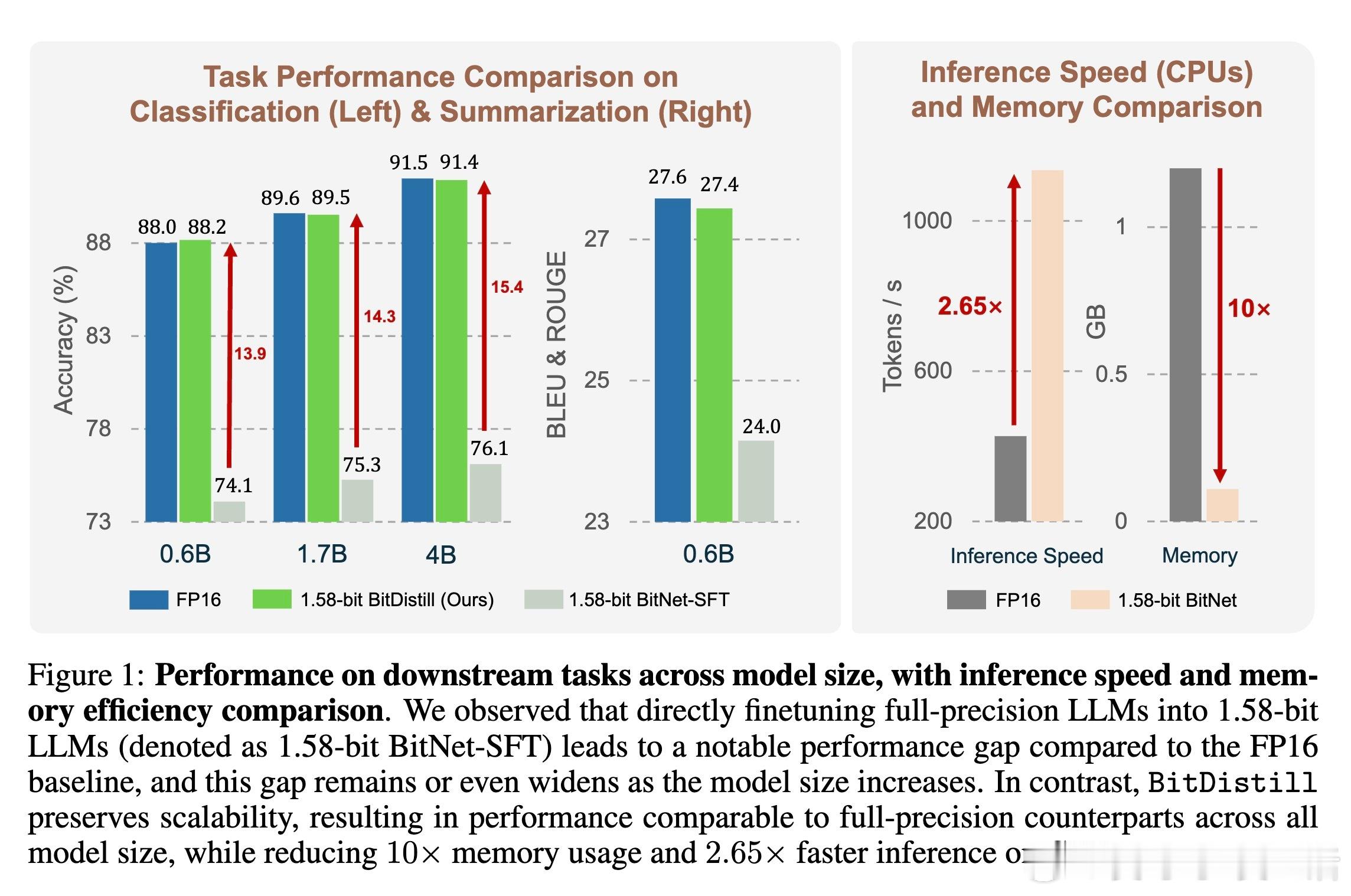
为此,微软研究院团队提出BitNet Distillation(BitDistill)框架,创新性地将预训练的全精度LLM(如Qwen系列)微调为1.58位BitNet模型,实现性能几乎无损的同时带来10倍内存节省和2.65倍CPU推理加速。核心技术包括:
1. 模型结构微调(SubLN模块)
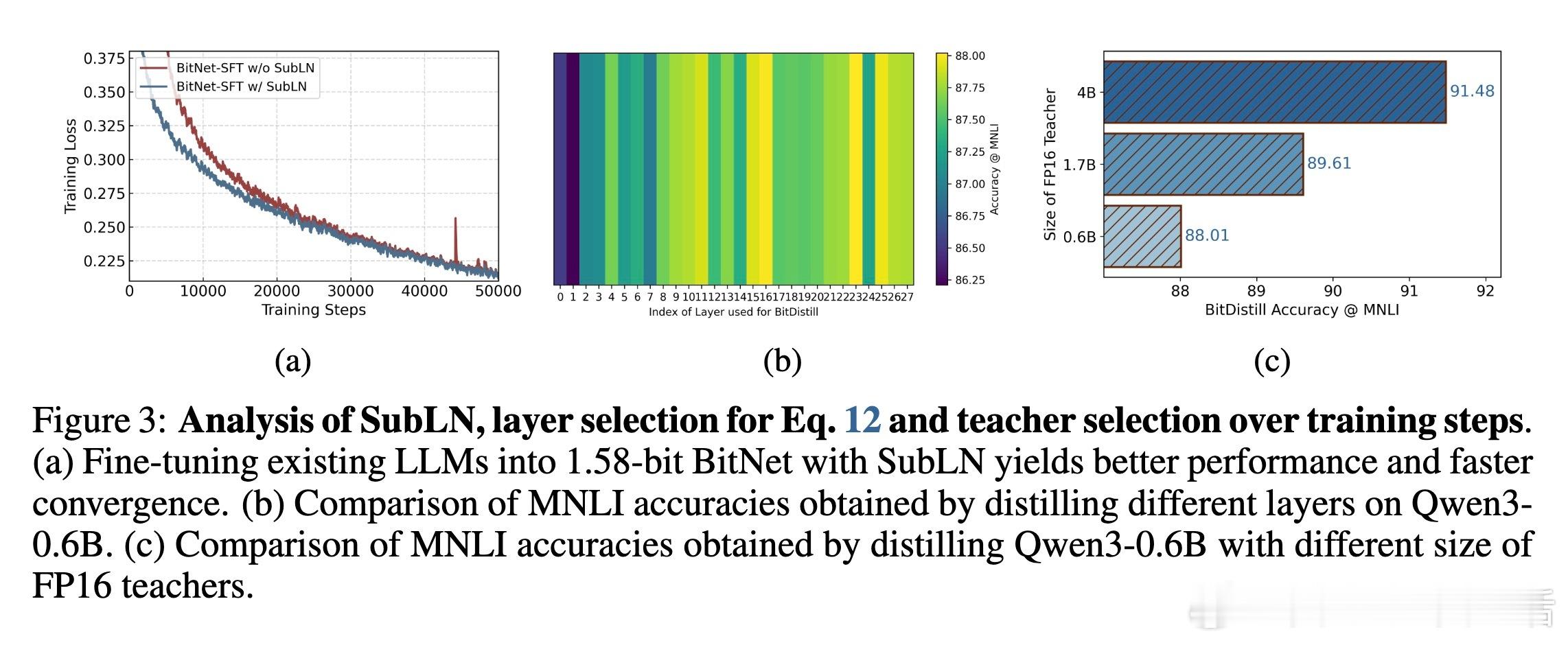
在Transformer每层的多头注意力和前馈网络输出投影前插入SubLN归一化层,稳定量化后激活的方差,解决1.58位模型训练不稳定和收敛困难问题。
2. 持续预训练(Continue Pre-Training)
利用少量额外预训练数据(10B tokens)对微调后的模型继续训练,缓解全精度权重向1.58位权重映射的性能差距,显著提高模型扩展性和下游任务表现。
3. 蒸馏微调(Distillation-based Fine-tuning)
结合MiniLM多头注意力蒸馏和logits蒸馏,利用全精度模型作为教师,1.58位模型为学生,精准传递注意力关系和预测分布,进一步缩小精度损失带来的性能差距。
实验验证:
在GLUE文本分类(MNLI、QNLI、SST-2)和CNN/DailyMail文本摘要任务中,BitDistill 1.58位模型性能与FP16微调模型相当,且推理速度提升2倍,内存占用降低10倍以上,支持0.6B到4B参数规模多种模型,且对不同预训练基线(Qwen2.5、Gemma)均具鲁棒性。
深入分析:
- SubLN显著提升训练稳定性和最终精度。
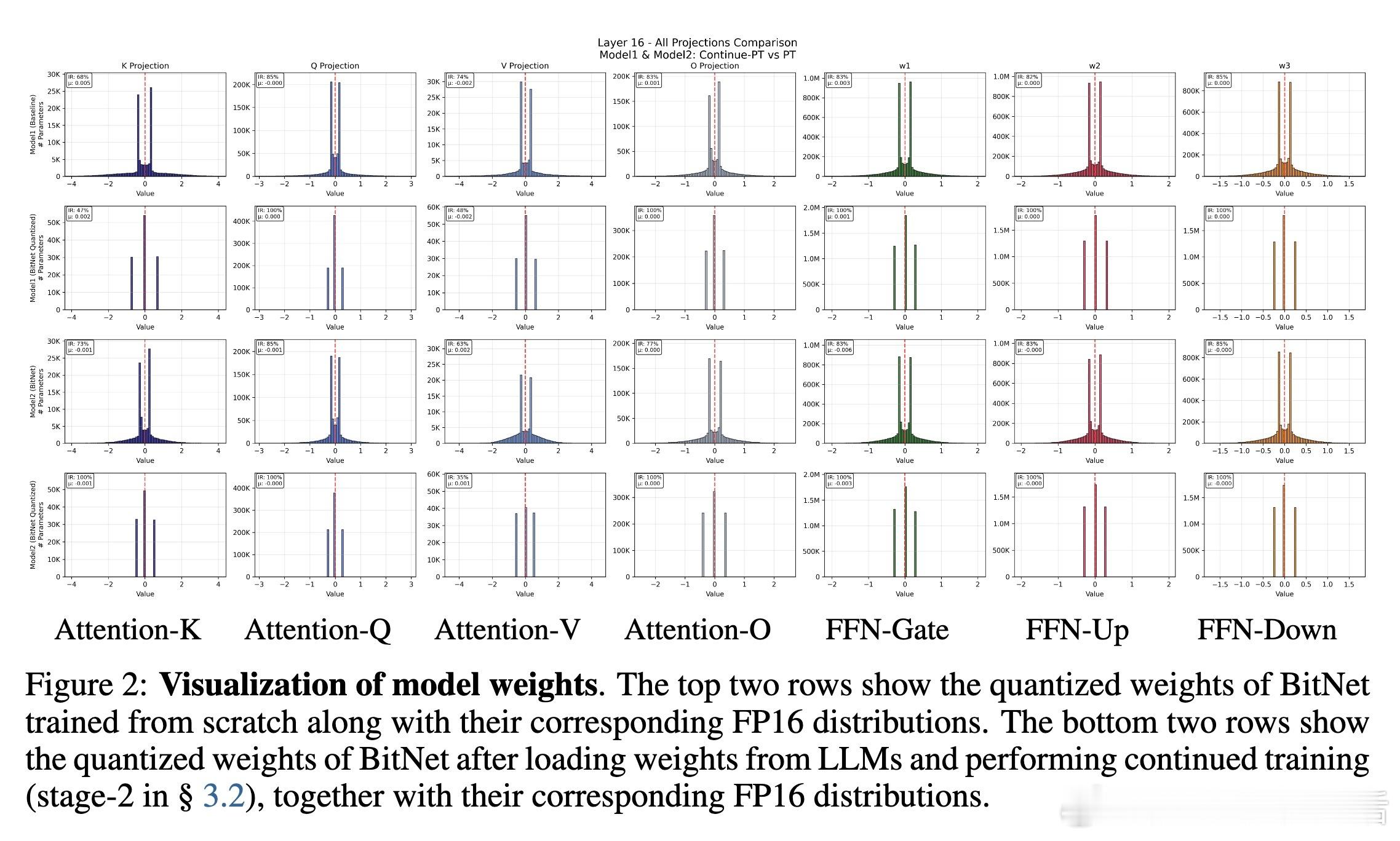
- 持续预训练帮助量化权重分布从高斯形态逐渐向BitNet特有分布靠拢,避免陷入局部最优。
- 单层多头注意力蒸馏优于全层蒸馏,提升模型优化自由度。
- 更强教师模型带来更好蒸馏效果,支持灵活选用不同规模教师。
意义与前景:
BitDistill为极低位量化大模型提供了一条高效微调路径,兼顾性能和资源消耗,极大促进了LLM在边缘设备和低资源环境中的实用部署。该框架兼容多种量化算法,具备良好的通用性和扩展性。
代码已开源:
详细技术细节与实验数据请见论文全文:
BitNet 模型量化 知识蒸馏 大语言模型 模型压缩 边缘部署 AI效率提升