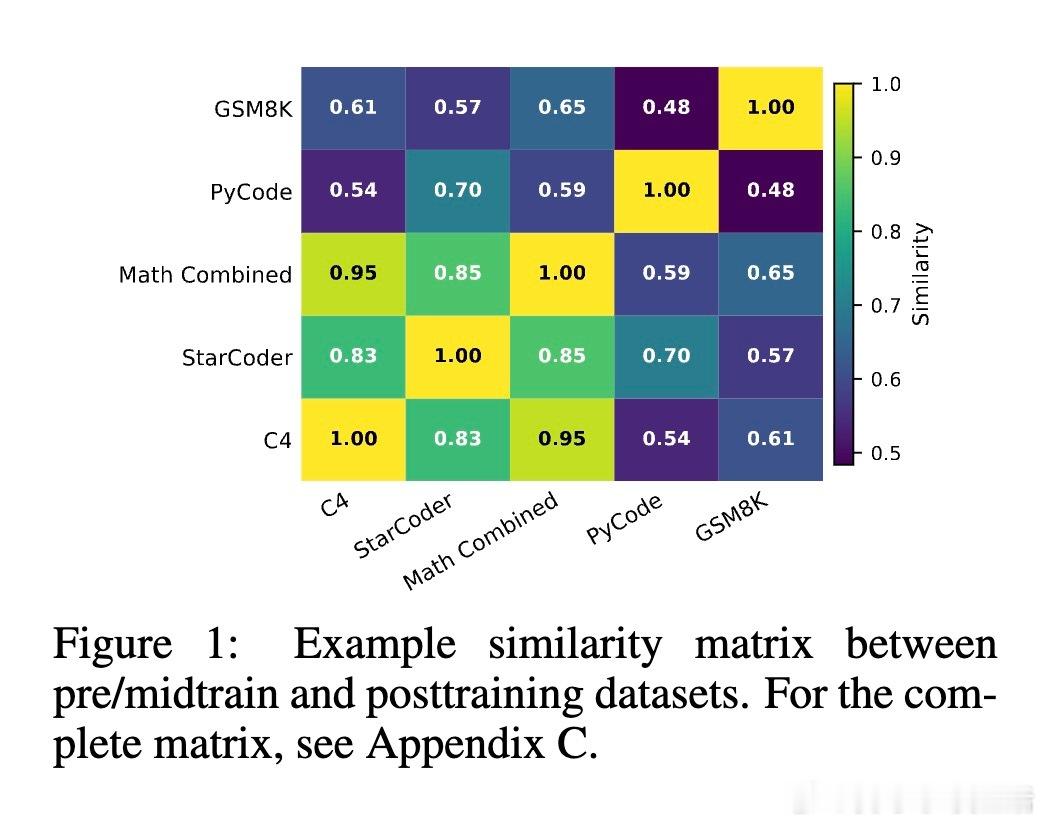
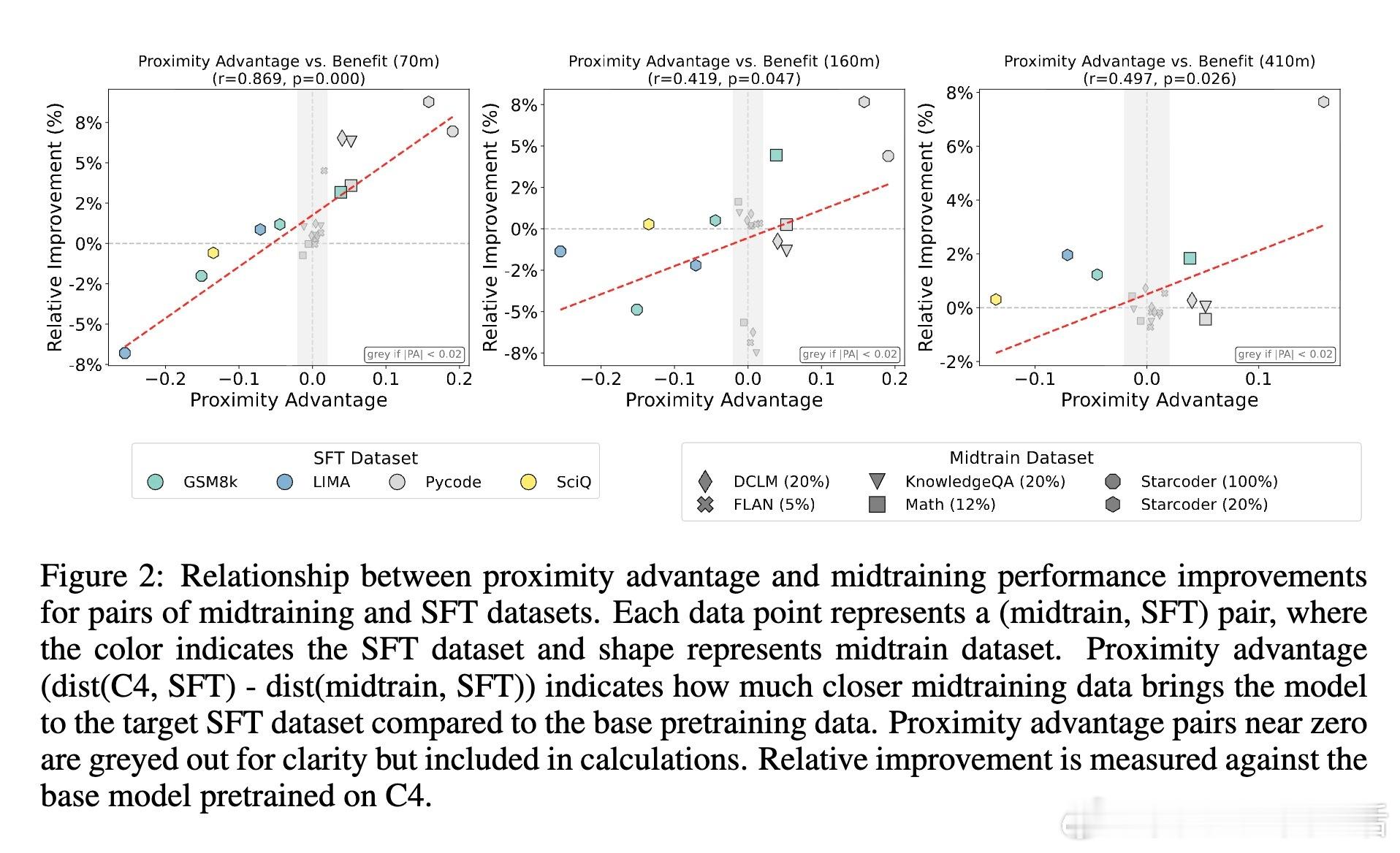
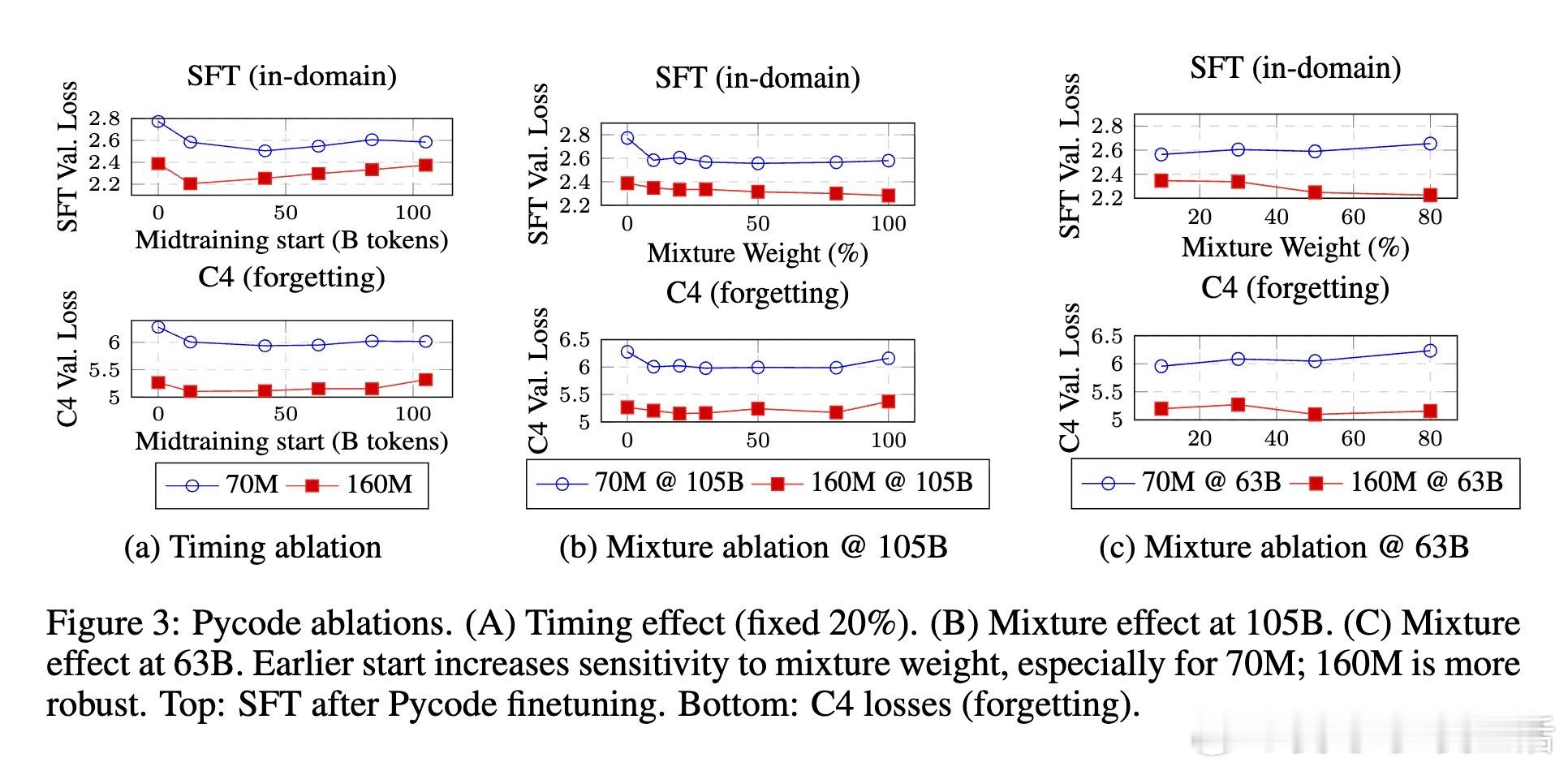
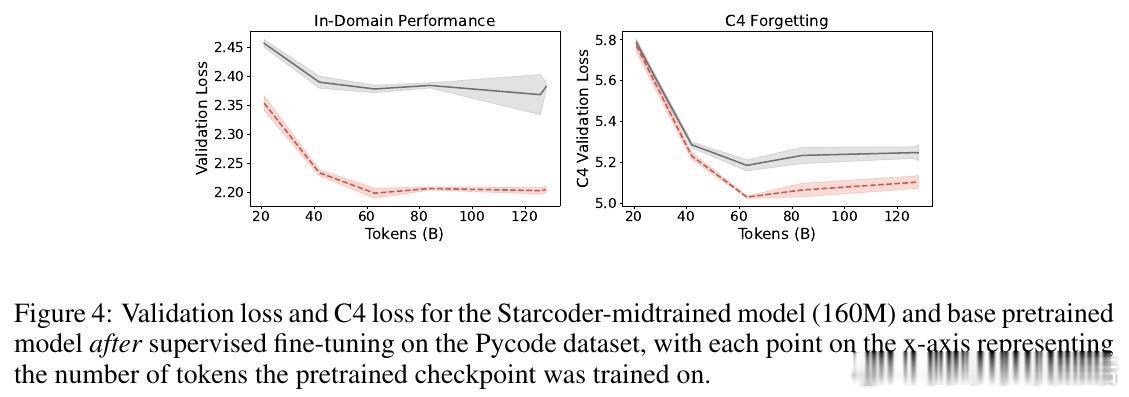
[CL]《Midtraining Bridges Pretraining and Posttraining Distributions》E Liu, G Neubig, C Xiong [CMU] (2025)
Midtraining桥接预训练与后训练数据分布
近期多语言模型引入“midtraining”阶段,即在预训练后期混入高质量、领域专属(如数学、代码、指令式)数据,显著提升后续微调表现。本文首次系统化实验,揭示midtraining为何有效及其最佳实践:
1、领域专属效益显著:数学与代码领域因与通用网络文本差异大,midtraining带来最大性能提升。针对这类领域,midtraining优于持续预训练。
2、减缓灾难性遗忘:midtraining相比直接微调或持续预训练,更好保留了通用语言能力,减少遗忘。
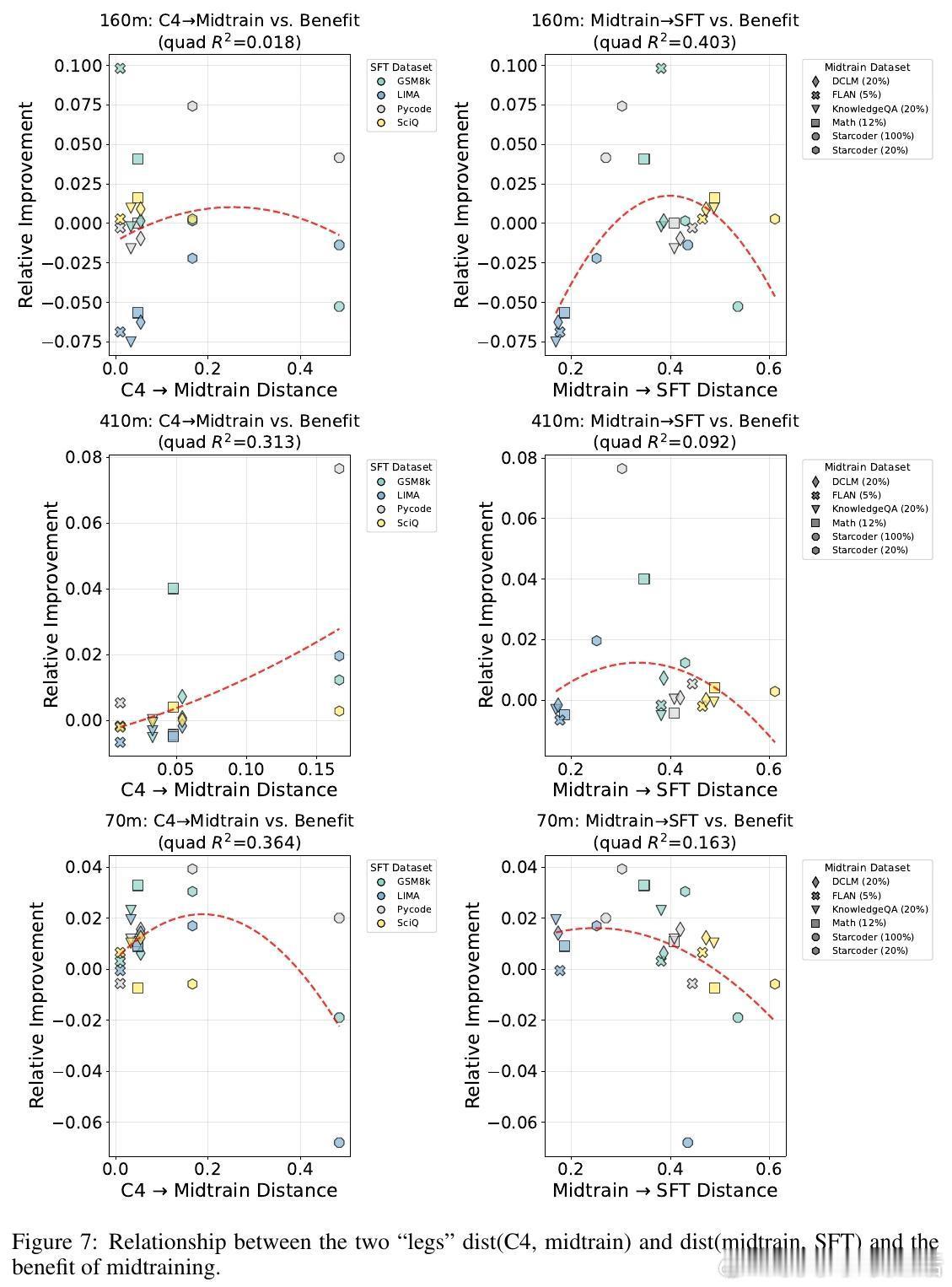
3、数据引入时机关键:越早引入专属数据,模型越能实现领域适应与通用能力平衡;混合数据比例影响相对较小。
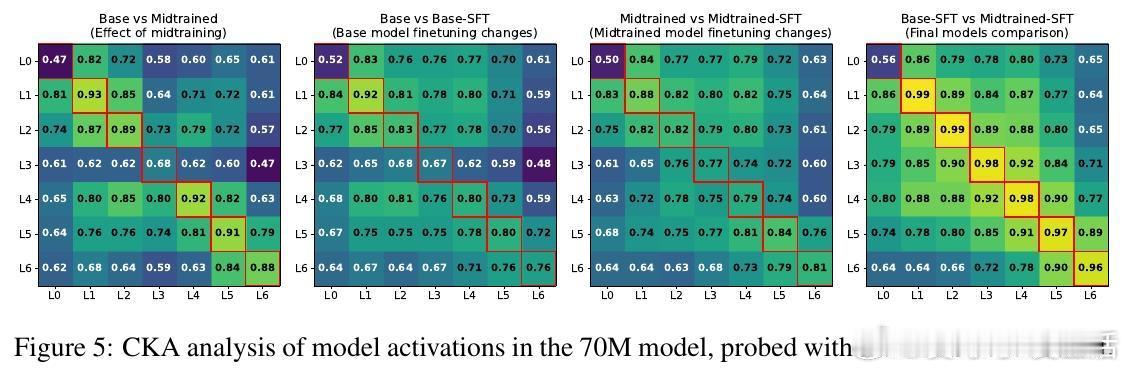
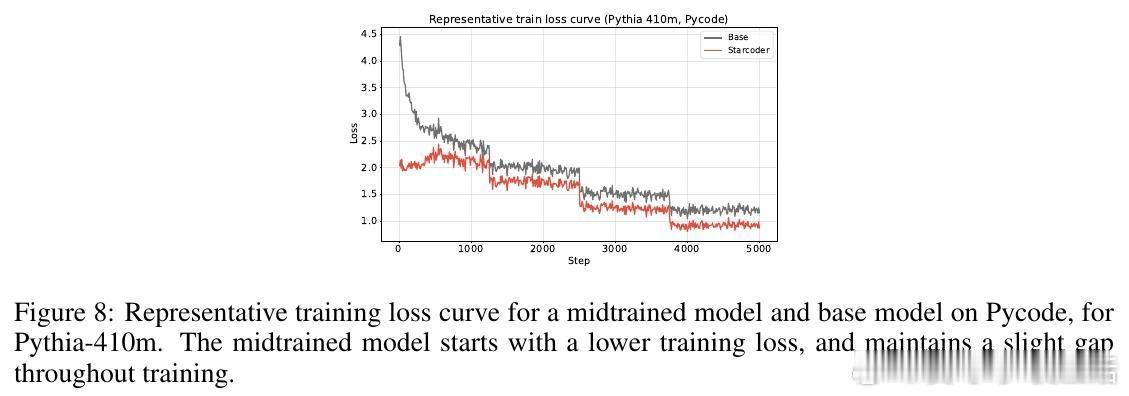
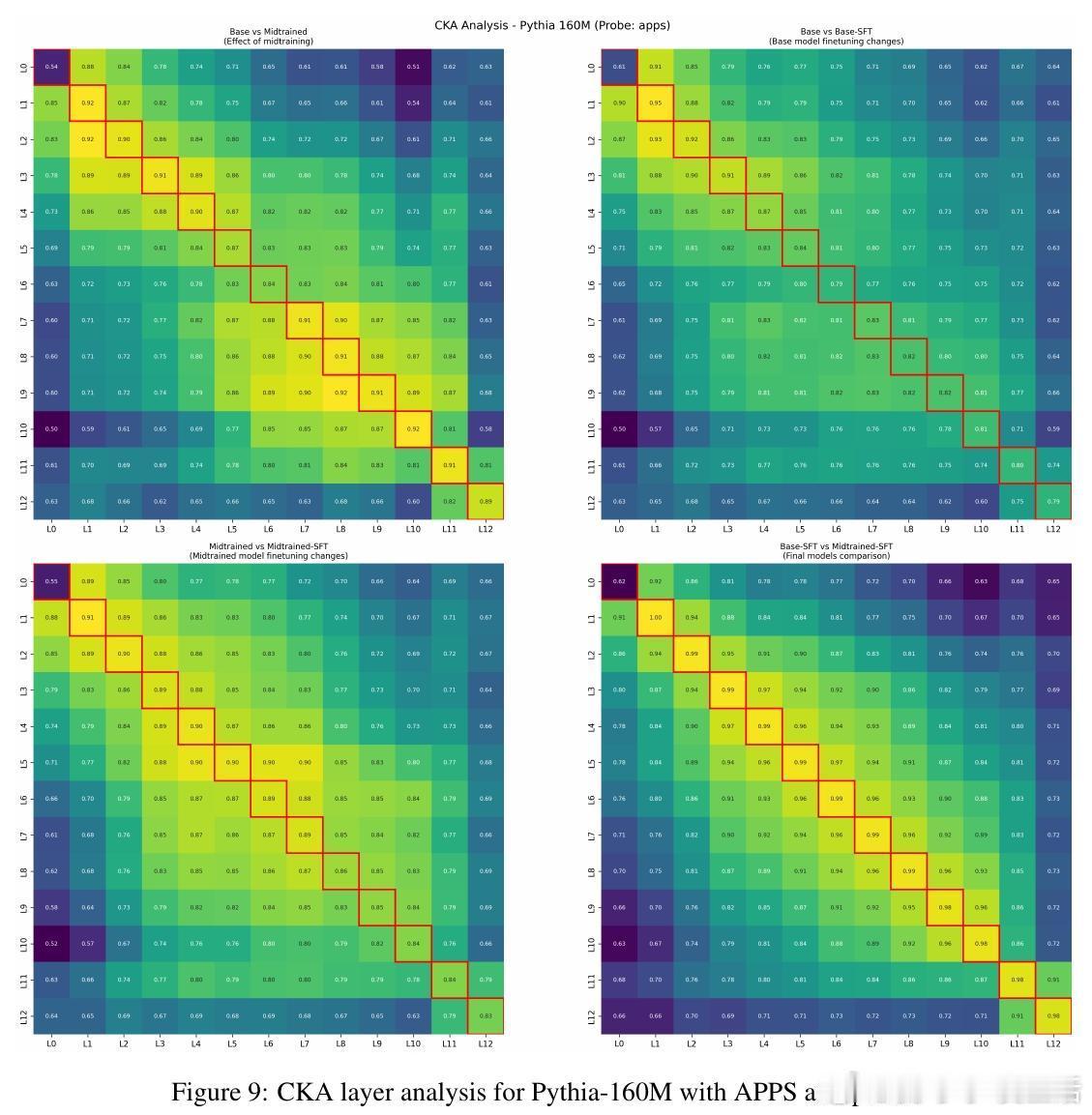
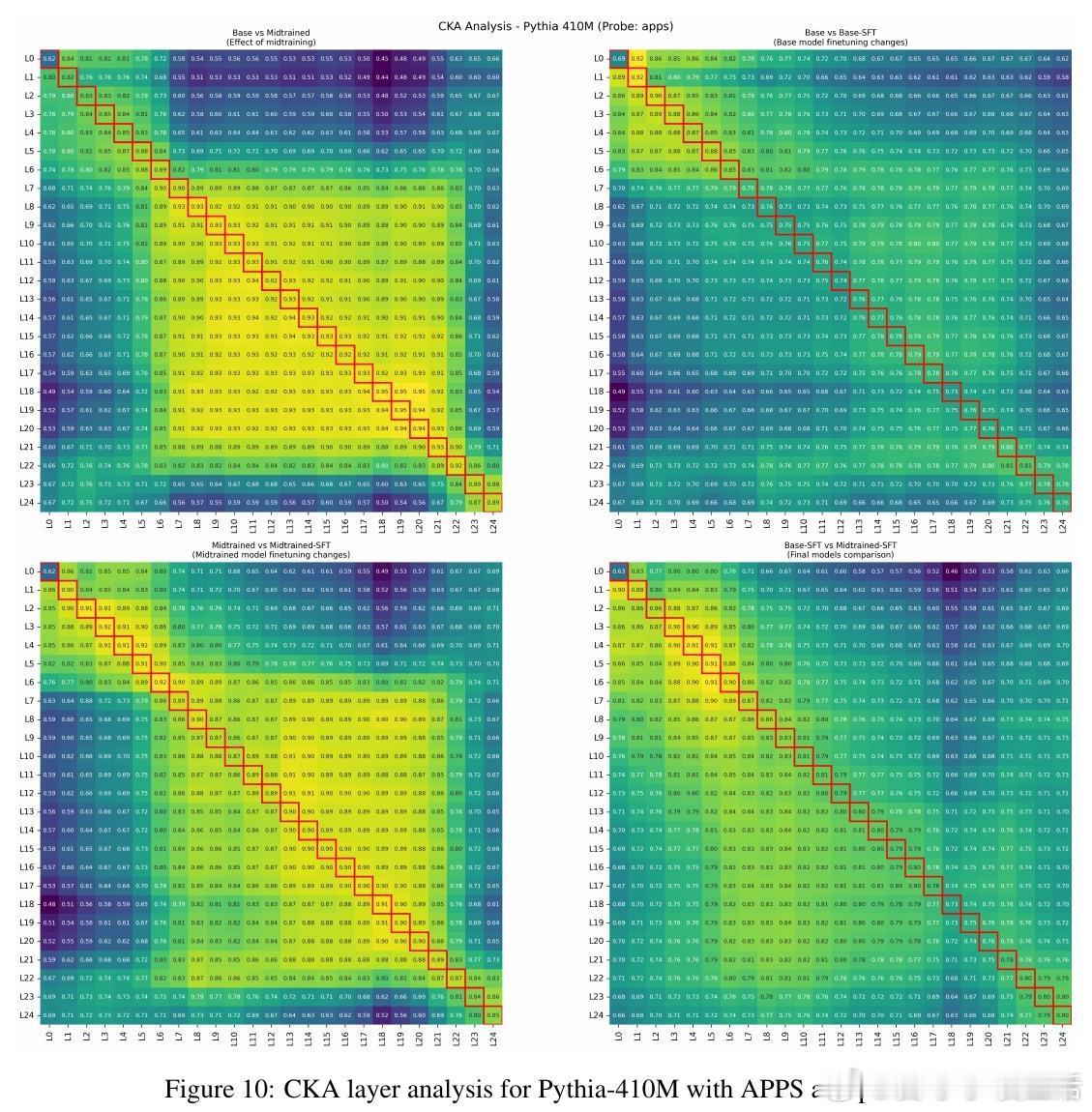
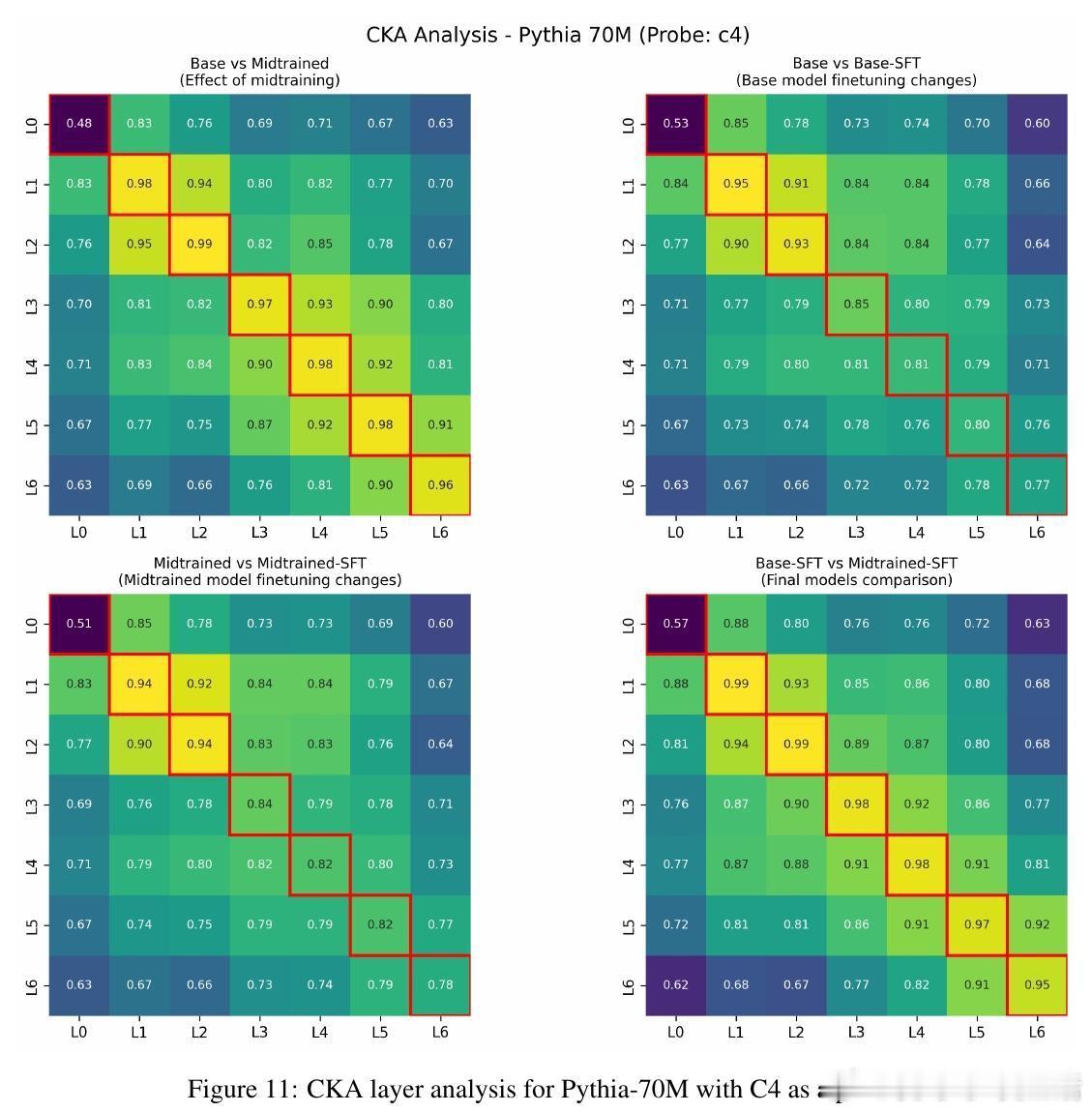
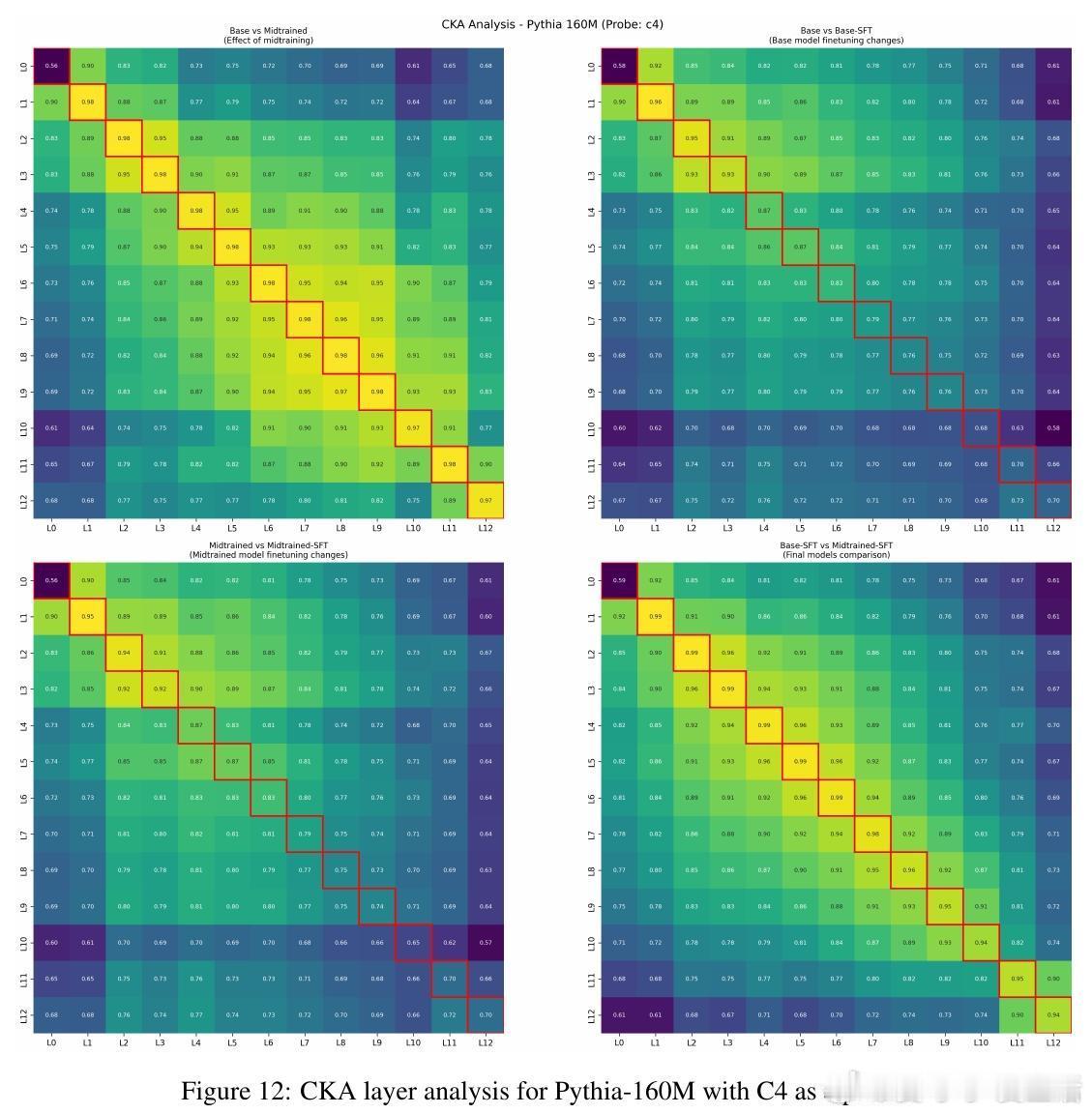
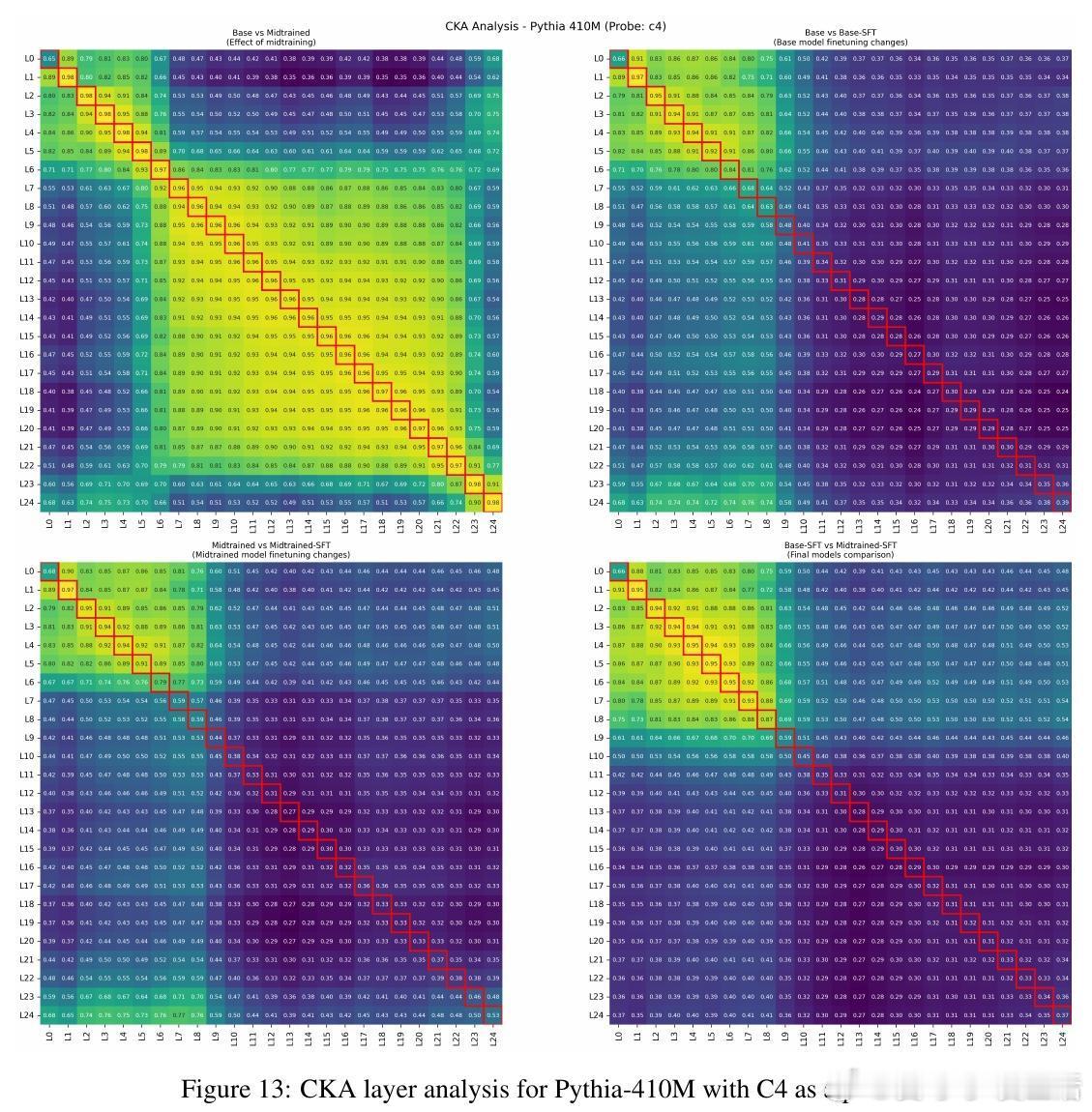
4、代表性变化平滑:midtraining使微调时模型内部表示变化减小,适应过程更顺畅。
数据分布“桥接”作用:有效midtraining数据在token层面填补预训练与后训练数据间分布差距,促进平滑过渡。
建议:针对预期后训练领域差异大者,宜早期引入相应领域混合数据进行midtraining,优于单纯持续预训练。未来工作可扩展至更多专业领域与更大规模模型,探索与RLHF等后训练方式的交互。
完整论文链接:arxiv.org/abs/2510.14865
相关代码数据开放:
语言模型 预训练 模型微调 领域适应 机器学习