在刚结束的第 31 届 SOSP 大会上 (计算机操作系统界的「奥斯卡」),阿里云联合北大发布的 Aegaeon 系统成功入选。
这篇论文捅破了一个行业心照不宣的秘密:云服务商的 GPU 算力正在被疯狂浪费。
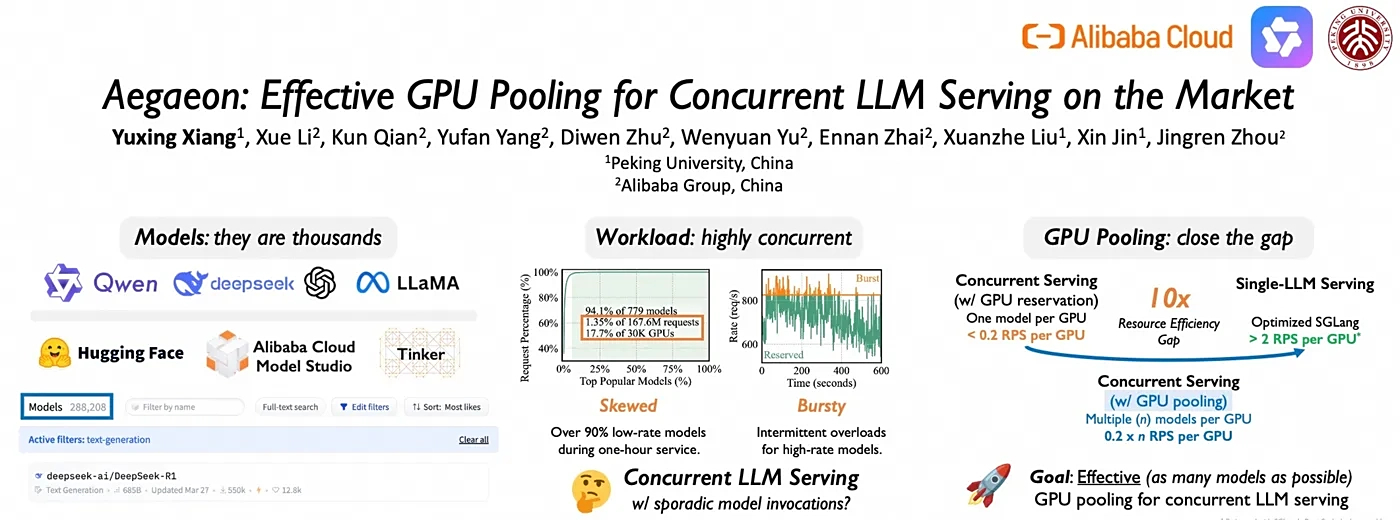
在阿里云模型市场,17.7% 的 GPU 算力只用来处理 1.35% 的请求。
平台托管着成千上万个 AI 模型, 但用户就爱扎堆用那几个爆款 (比如 Qwen 系列);
剩下的「长尾模型」虽然访问量少得可怜, 却各自占着 GPU 资源不放手。这有点像一家餐厅为了几个偶尔来的客人,常年空着大半包间。
Aegaeon 的解法相当硬核:打破 GPU 和单一模型的绑定关系,让一块 GPU 可以动态服务多个模型。
这听起来简单,实际工程难度极高,需要在保证服务质量的前提下实现资源共享。
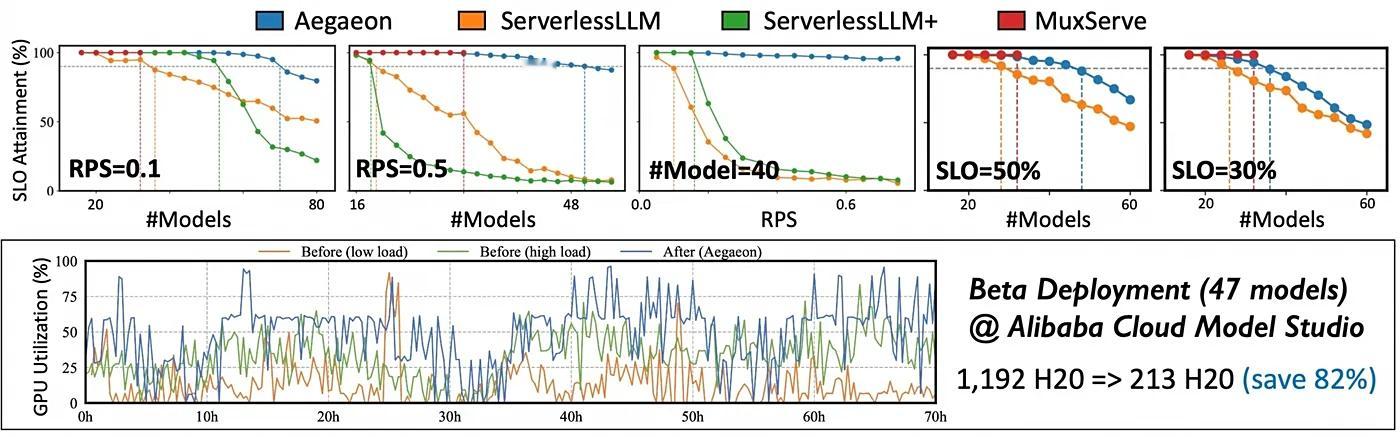
经过三个多月的 Beta 测试,结果显示:服务数十个 720 亿参数的大模型,,所需英伟达 H20 GPU 从 1192 块暴降至 213 块——成本直接砍掉 82%。
这篇论文因此被 SOSP 认定为「首个揭示并解决市场上并发 LLM 服务成本过高问题」的公开工作。