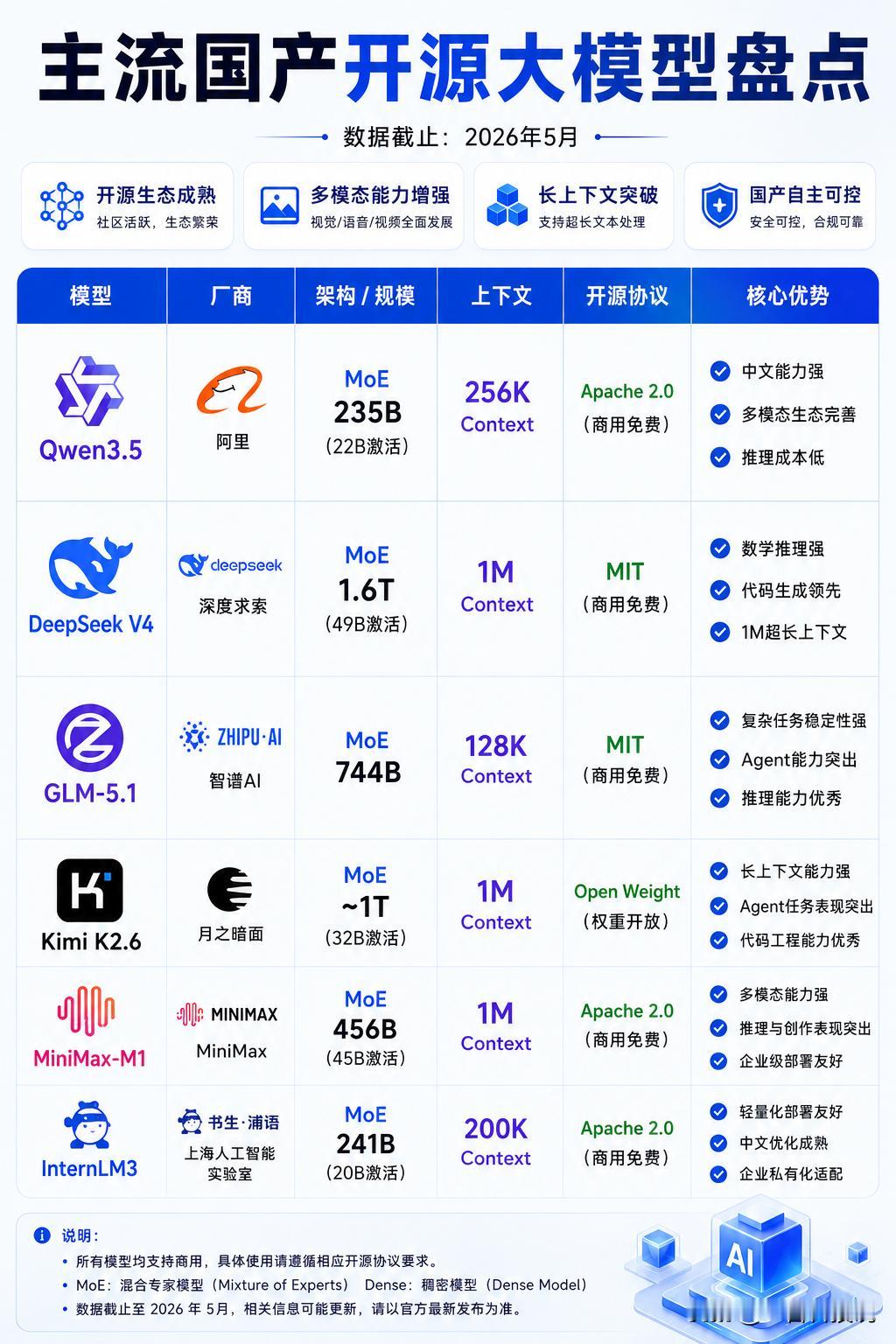
大模型er话聊:国产算力正值“当打之年”,存储不能当拖后腿的
AI大模型往多模态走,数据量翻倍涨。训练集群常常面临一个尴尬局面:GPU集群算力很足,但数据喂不上去,GPU大部分时间在闲置等待,算力空转成了行业内公开的秘密。
曙光的FN9000除了在硬指标上进阶:单控400万+ IOPS,集群直接达到2亿,亚毫秒级时延,此外,还在两个方向做了针对性设计,个人觉得值得拿出来摆摆。
一个是存储-显存直达,数据不经过CPU中转,直接供到GPU近侧存储。配合KV Cache offload和多层数据分级,推理环节的延迟大幅降低,GPU有效利用率肉眼可见地提升。
另一个是AI数据工厂。这个概念值得深挖。它本质上是在构建一套全流程AI加速中枢:从数据清洗、标注到向量化生成,再到训练和推理部署,整个管线打通。配合向量数据库优化、AI算子加速库,存储主动参与数据处理和预处理的角色。
这个思路其实挺超前的。当存储能主动做向量化、数据分级和缓存卸载,GPU就可以专注于计算,算力产出密度会高出一个量级。
目前看,存储行业从容量支撑升级为性能+可靠+兼容+安全的一体化存力,这个价值坐标迁移的趋势已经很明显了。