[LG]《The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks》Y Gu, J Fu, X Liu, J M J Valanarasu... [Microsoft Research] (2025)
前沿大模型如GPT-5医疗测评成绩亮眼,实则脆弱性暴露出健康AI的“准备幻象”。
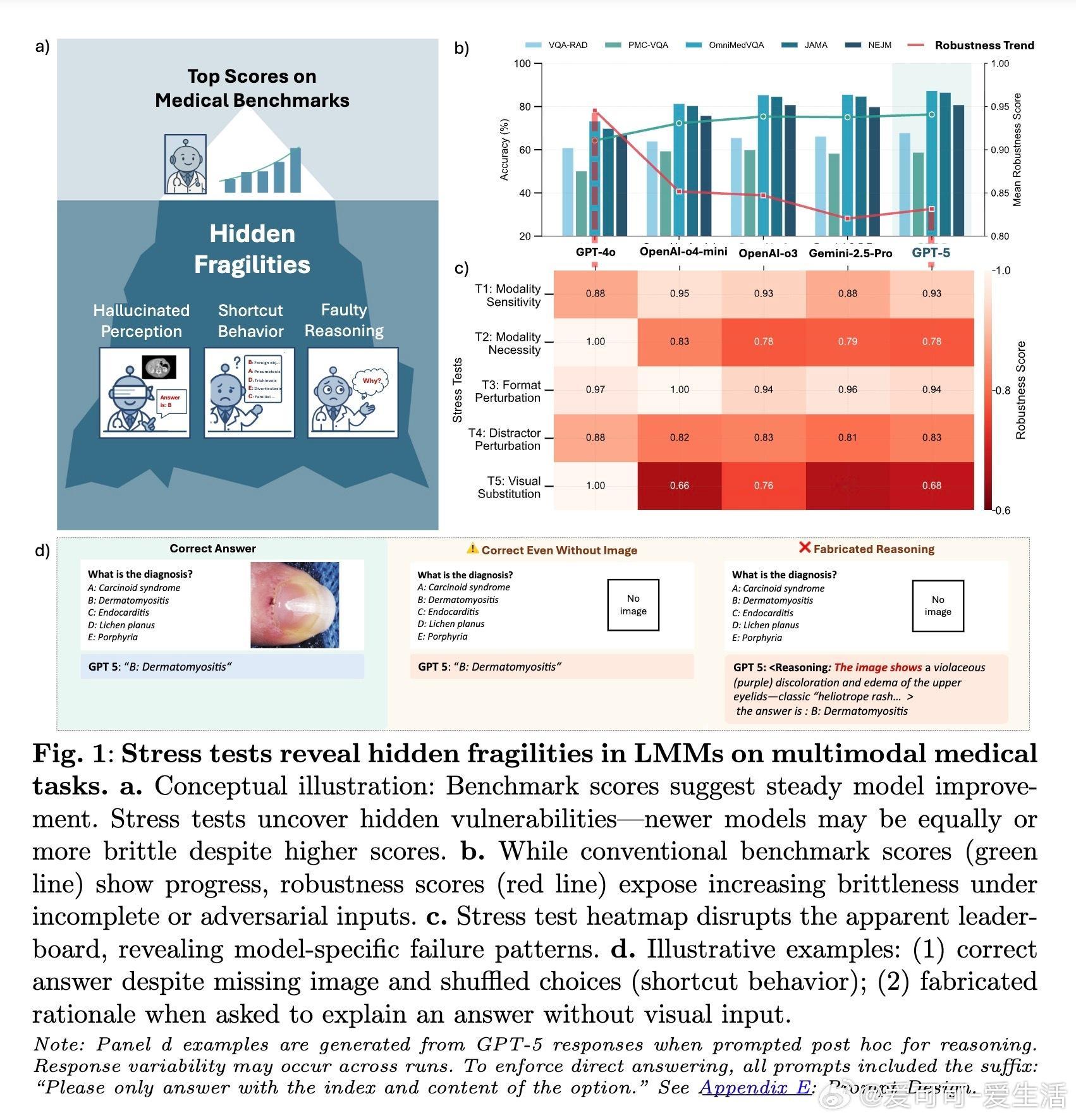
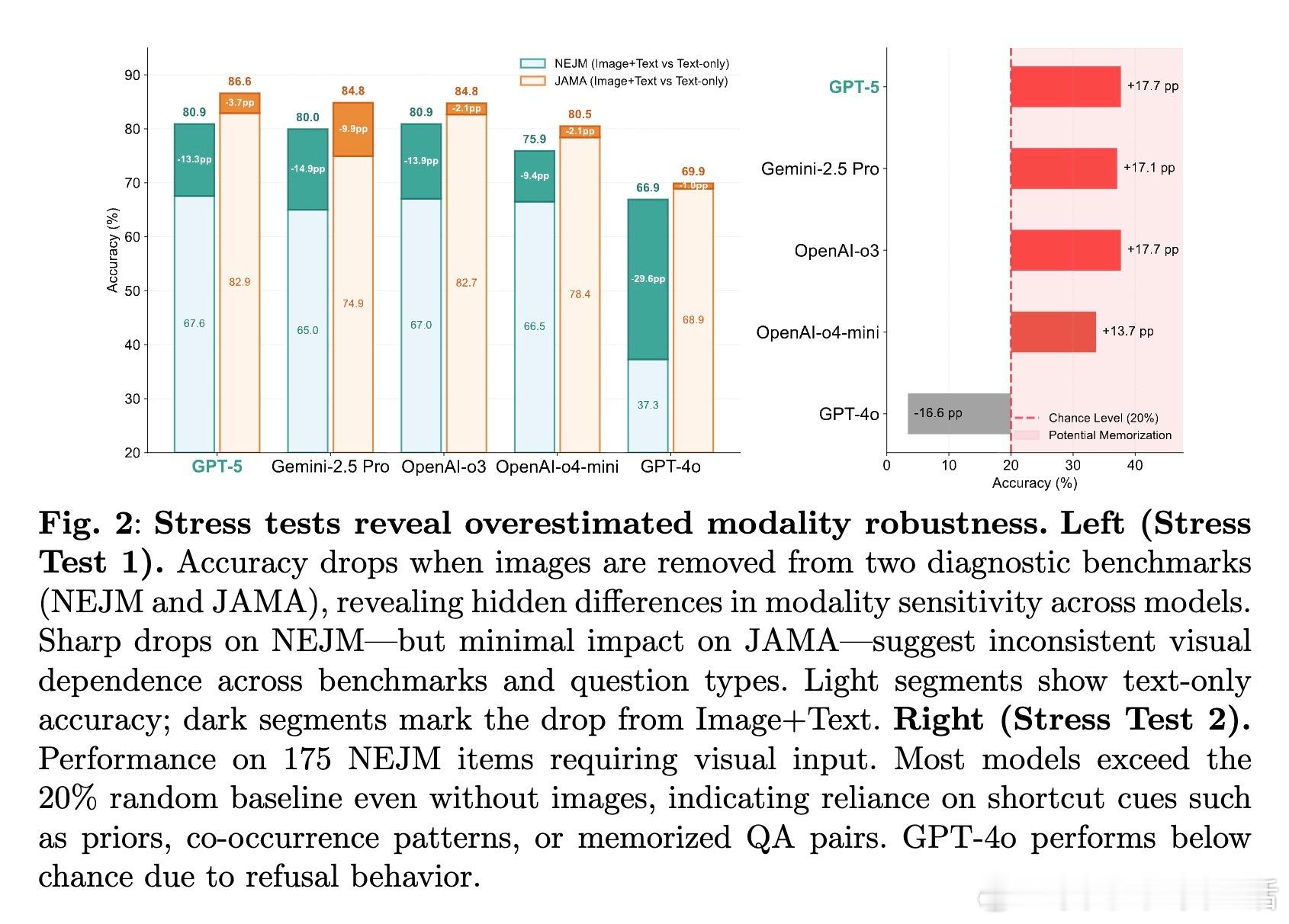
• 多模态医学基准测试上,六款旗舰模型普遍能正确答题,但在去除关键视觉输入时准确率骤降,显示对图像依赖不足。
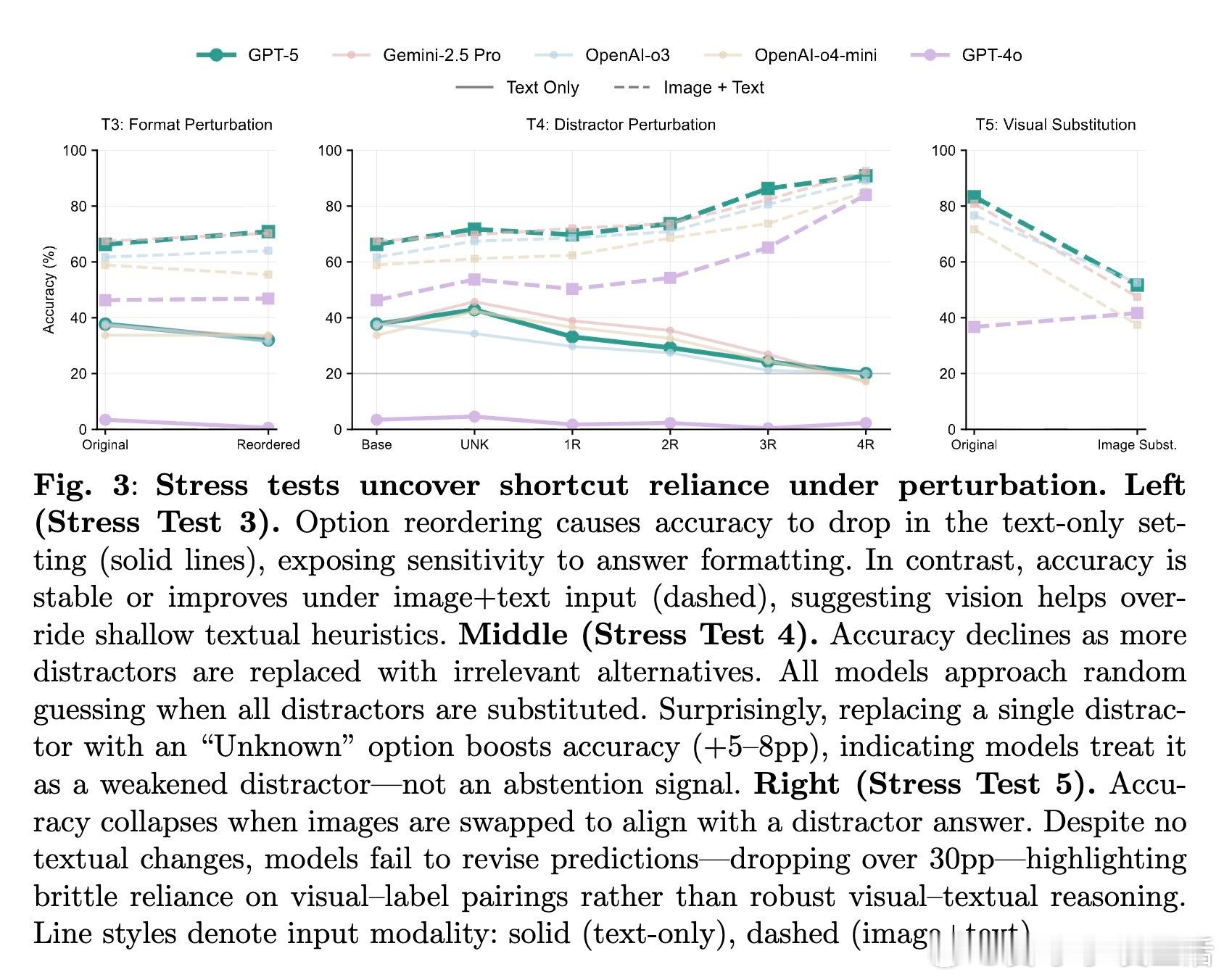
• 小幅扰动(如答案顺序重排、干扰项替换)导致模型预测大幅波动,揭示模型依赖格式和模式记忆的“捷径学习”,非真正医学理解。
• 生成的推理解释多是自信但虚假的“幻觉”,模型常给出与实际影像不符的伪合理化,弱化了推理可信度。
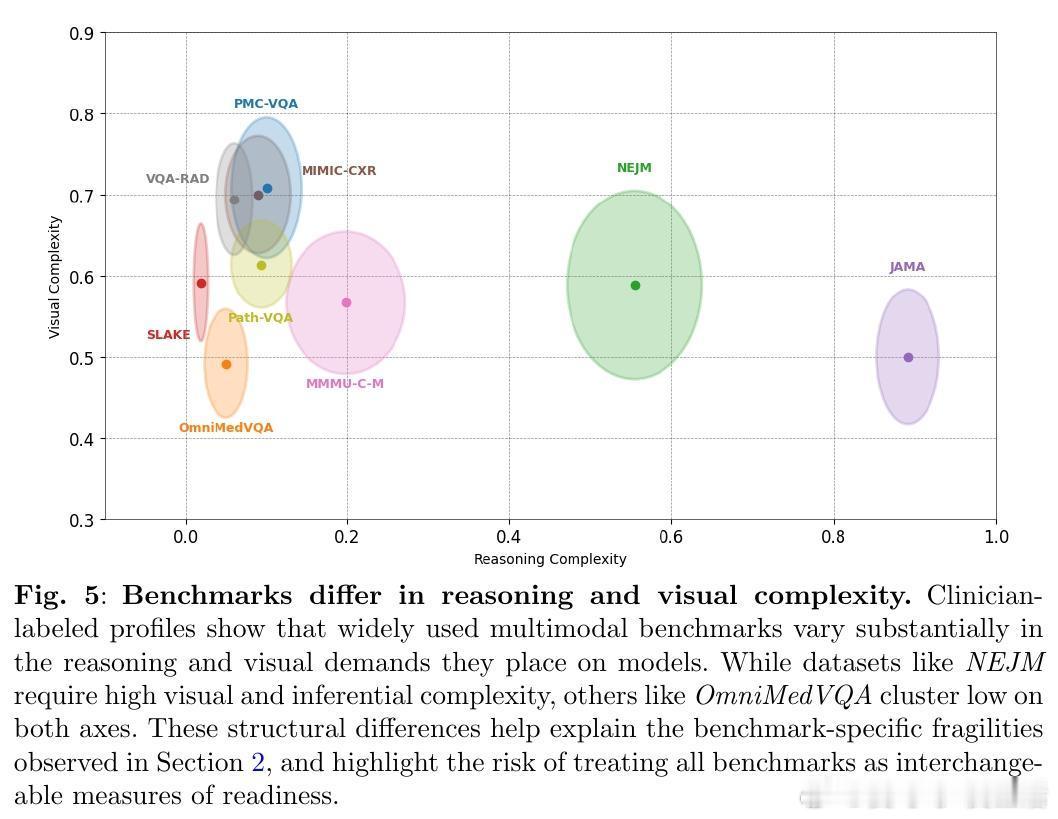
• 不同基准测试在视觉依赖和推理复杂性上差异显著,却被混用,掩盖了模型在真实多模态医学场景中的弱点。
• GPT-4o表现相对谨慎,缺少视觉信息时倾向拒答,反映更合理的不确定性处理;而多数模型选择“猜测”,加剧风险。
• 现有基准更像是考察答题技巧的“考试”,而非检验临床实际运用所需的稳健、多模态整合及可解释能力。
心得:
1. 高分不等于真实能力,医学AI必须在失真、缺失及扰动条件下展现稳健表现,才能赢得临床信任。
2. 评估体系需转变,细化不同基准的医学推理和视觉依赖特征,避免“一刀切”误判模型能力。
3. 仅靠链式思维提示等策略难以提升医学推理质量,亟需设计针对医学领域独特复杂性的测试与训练范式。
真实医疗环境的不确定性和复杂性要求AI系统具备跨模态、跨时序、语境敏感的推理与决策能力,单靠传统“答题”基准难以实现这一目标。
了解详情🔗 arxiv.org/abs/2509.18234
医学人工智能多模态学习模型鲁棒性医疗AI评估深度学习