[CL]《Self-Harmony: Learning to Harmonize Self-Supervision and Self-Play in Test-Time Reinforcement Learning》R Wang, W Huang, Q Cao, Y Iwasawa... [The University of Tokyo & RIKEN Center for Advanced Intelligence Project] (2025)
在大语言模型(LLM)推理能力提升的道路上,如何在测试时无需人工标注,实现模型的自适应优化一直是难题。传统的多数投票伪标签生成方法,虽简单有效,却容易陷入“多数错误”陷阱——模型如果对错误答案反复自信,便会强化错误,难以纠正。
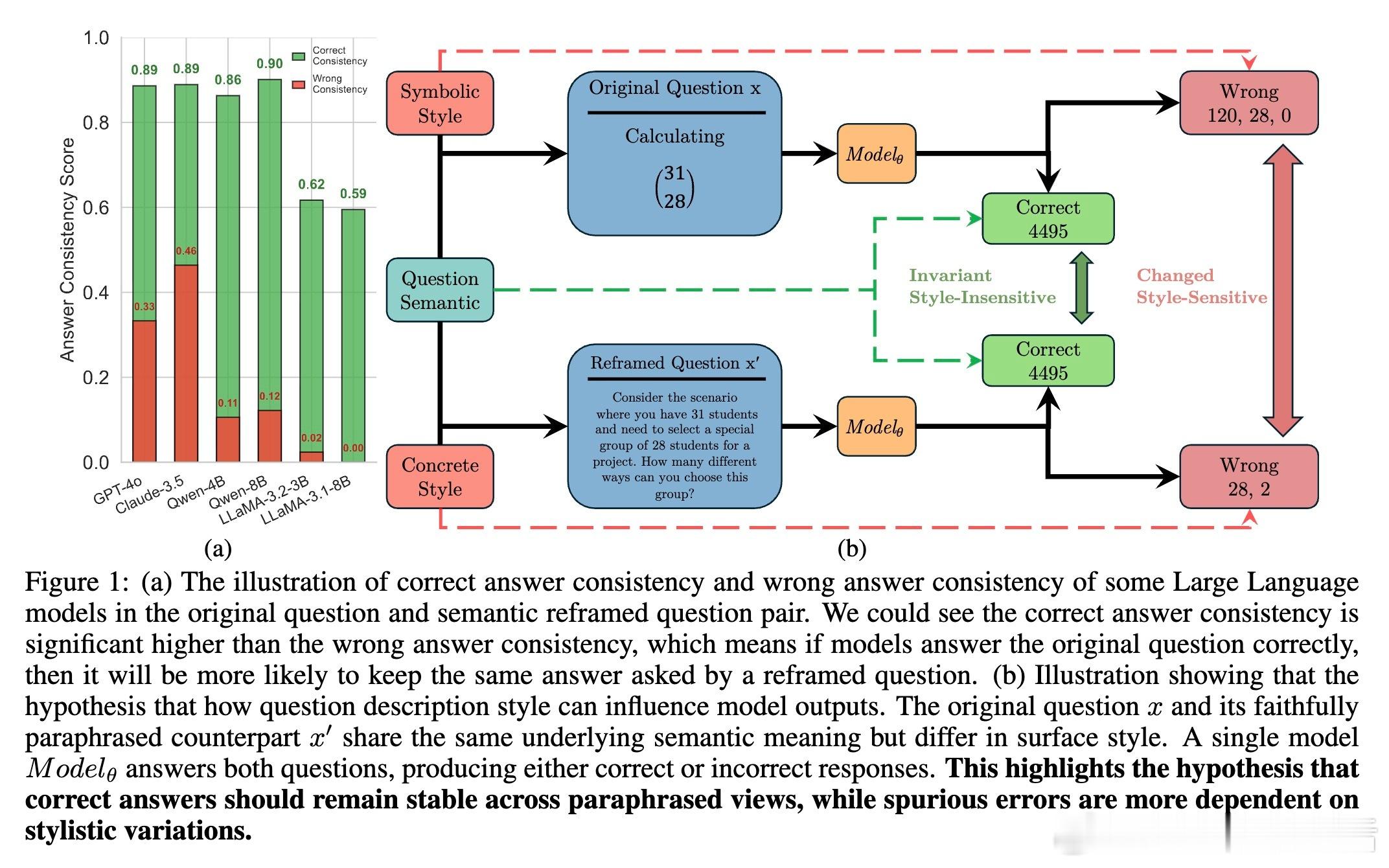
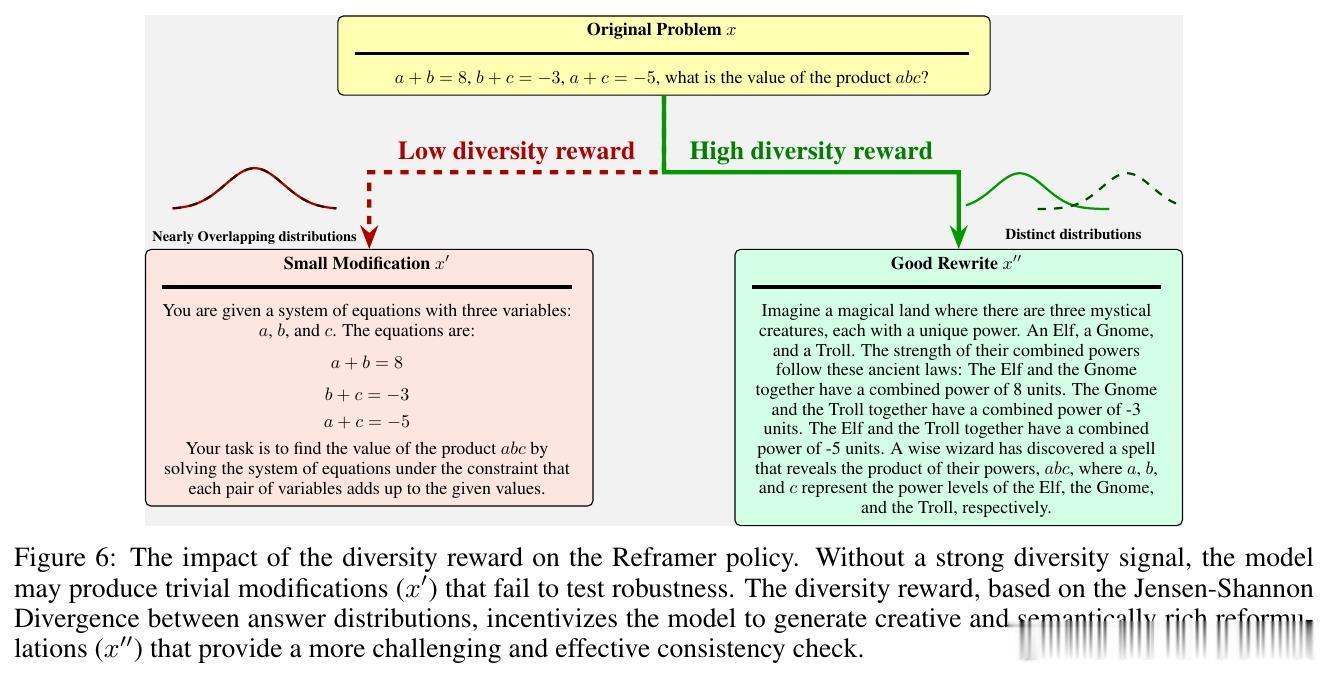
这篇文章带来了全新突破。核心思想是:正确答案应在原始问题和其语义等价但表述不同的“改写版”问题中保持一致。基于此,Self-Harmony框架让同一模型在两种角色间切换——“解题者”负责给出答案,“改写者”负责重新表述问题,形成两个视角的答案分布。
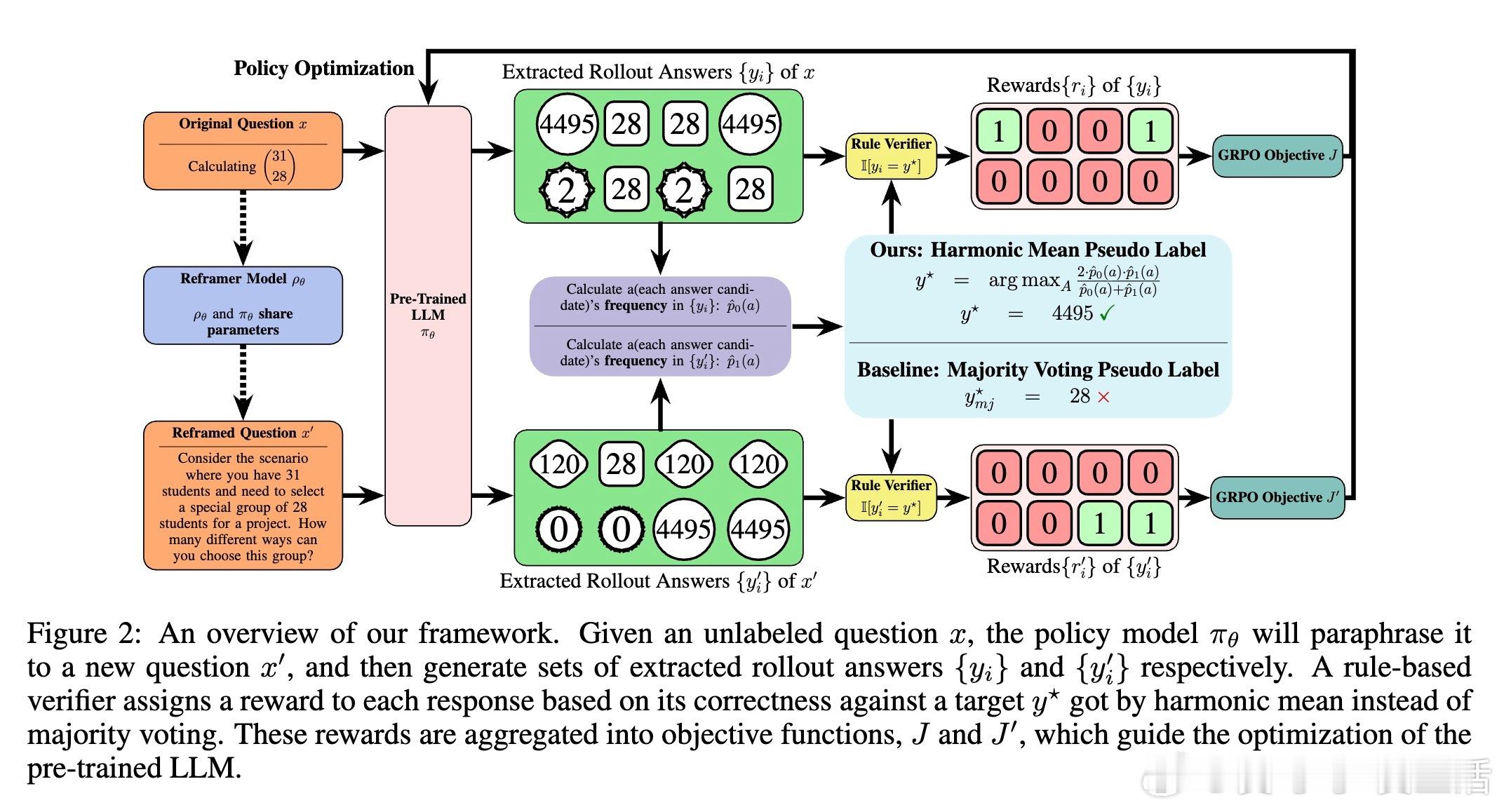
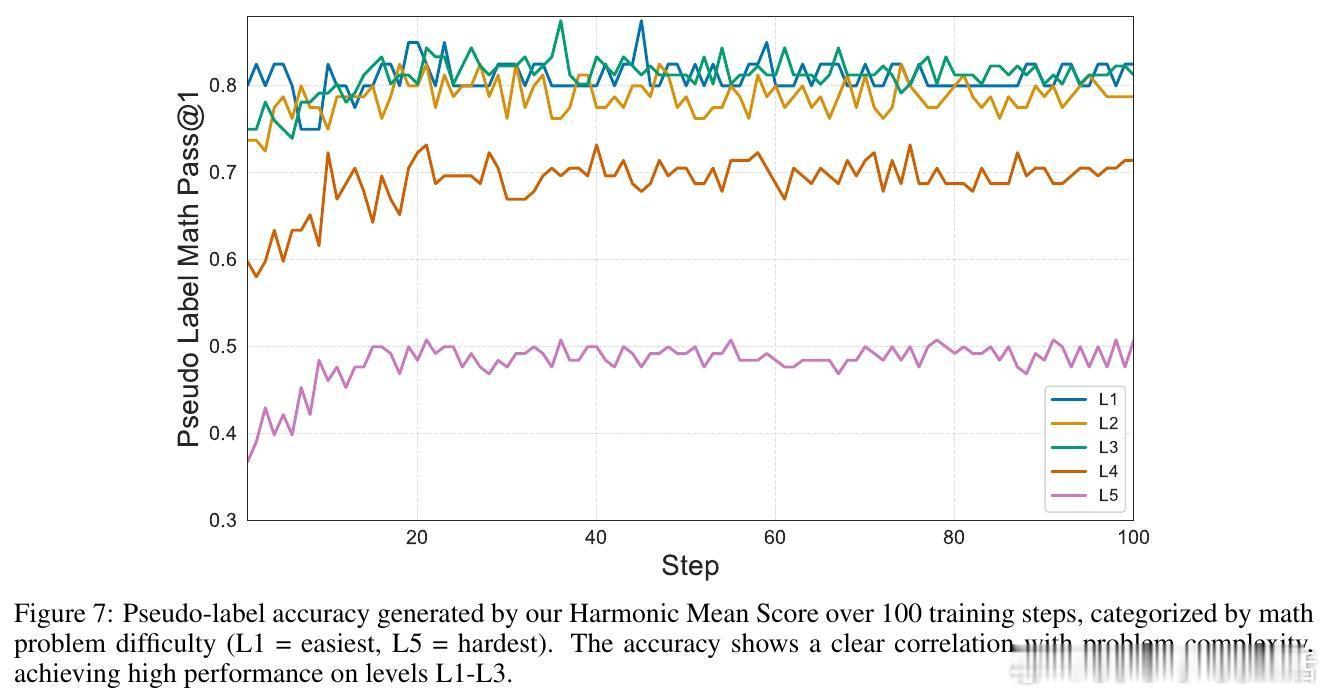
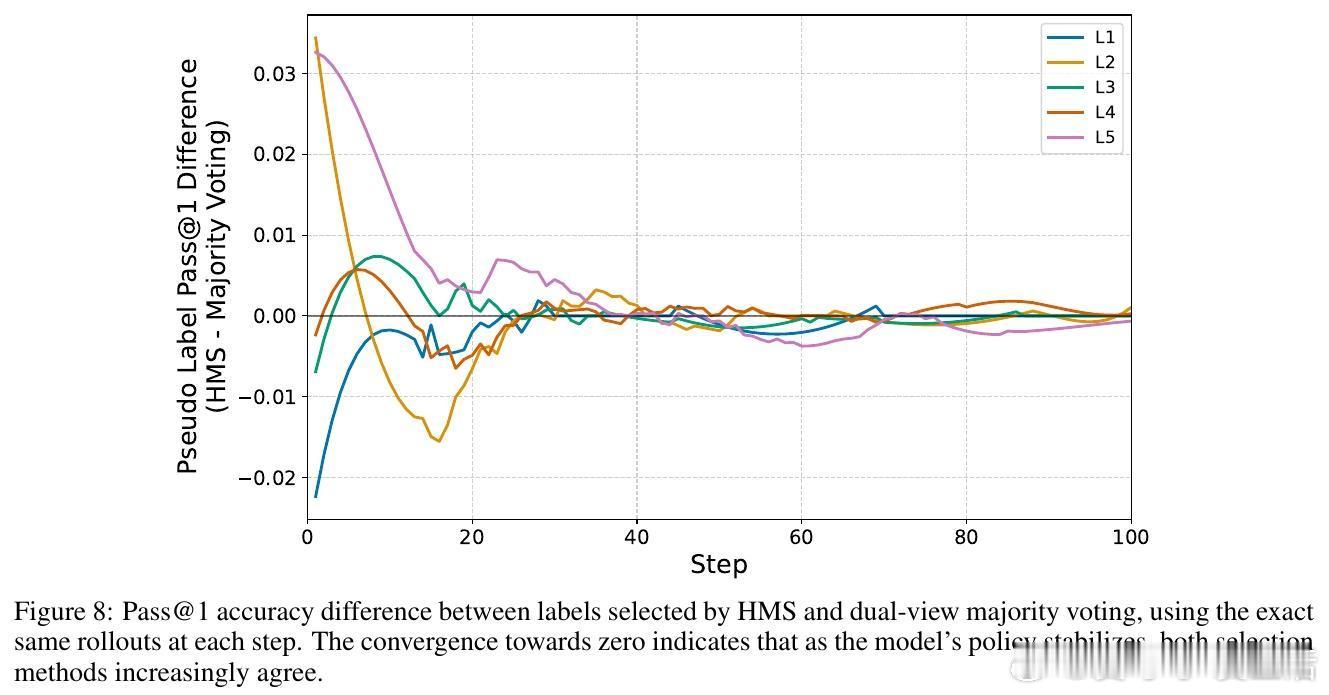
关键创新在于用“调和平均数”(Harmonic Mean Score, HMS)取代传统的多数投票,选择在两种视角中均表现稳定的答案作为伪标签。调和平均数对答案频率的两视角一致性施加严格要求,有效过滤依赖特定表述的伪答案,避免了单视角偏见。此方法无需任何人工监督或辅助模型,实现了真正的自监督自适应。
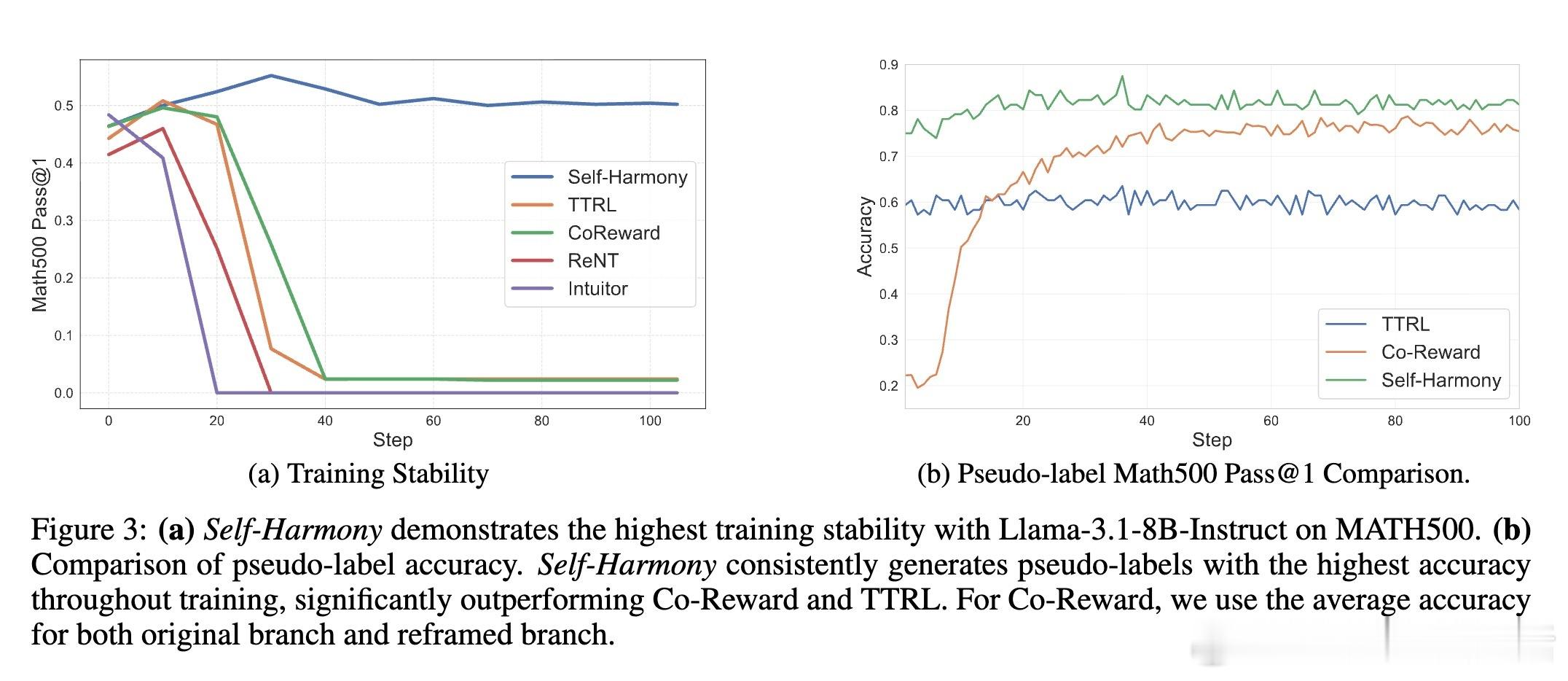
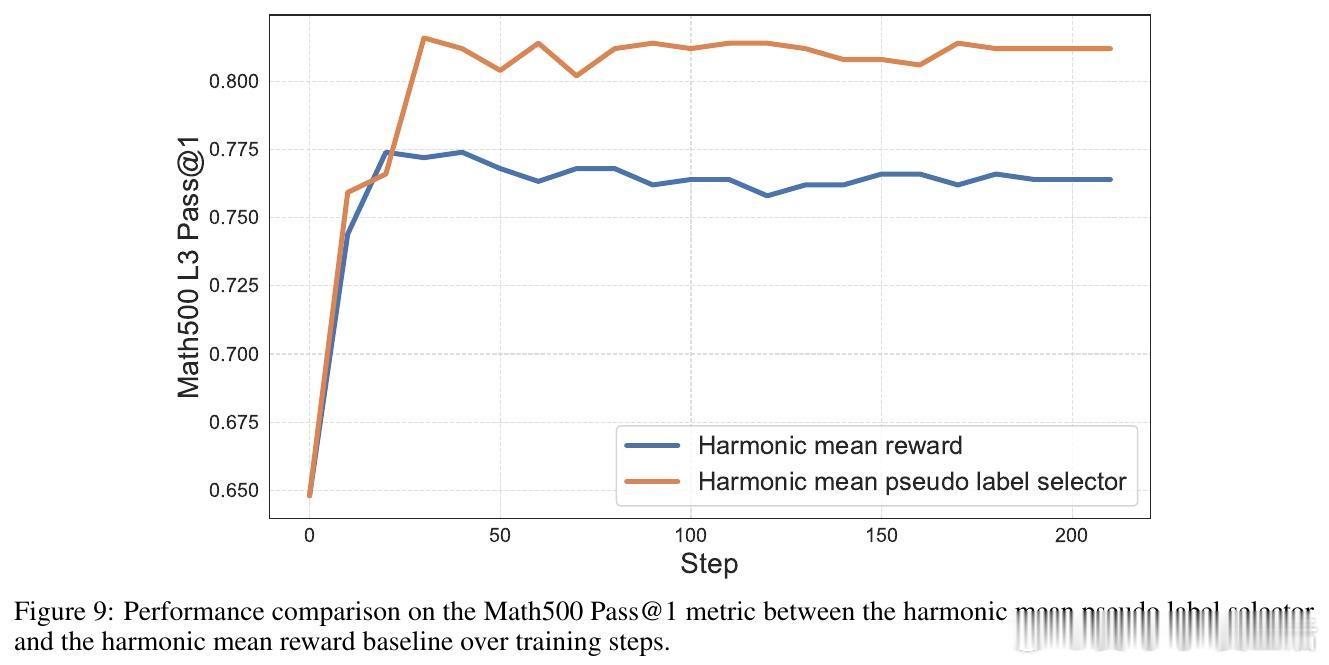
大量实验证明,Self-Harmony在六大推理基准、五款1.7B至8B参数开源模型上表现卓越,30个配置中28次夺冠,准确率大幅提升。例如,Llama-3.1-8B模型在GSM8K数据集上准确率从60.5%跃升至91.6%,在MATH500数据集上Qwen3-4B也从60.2%提升到78.5%。此外,训练过程极其稳定,无一次失败,展现出极高的鲁棒性。
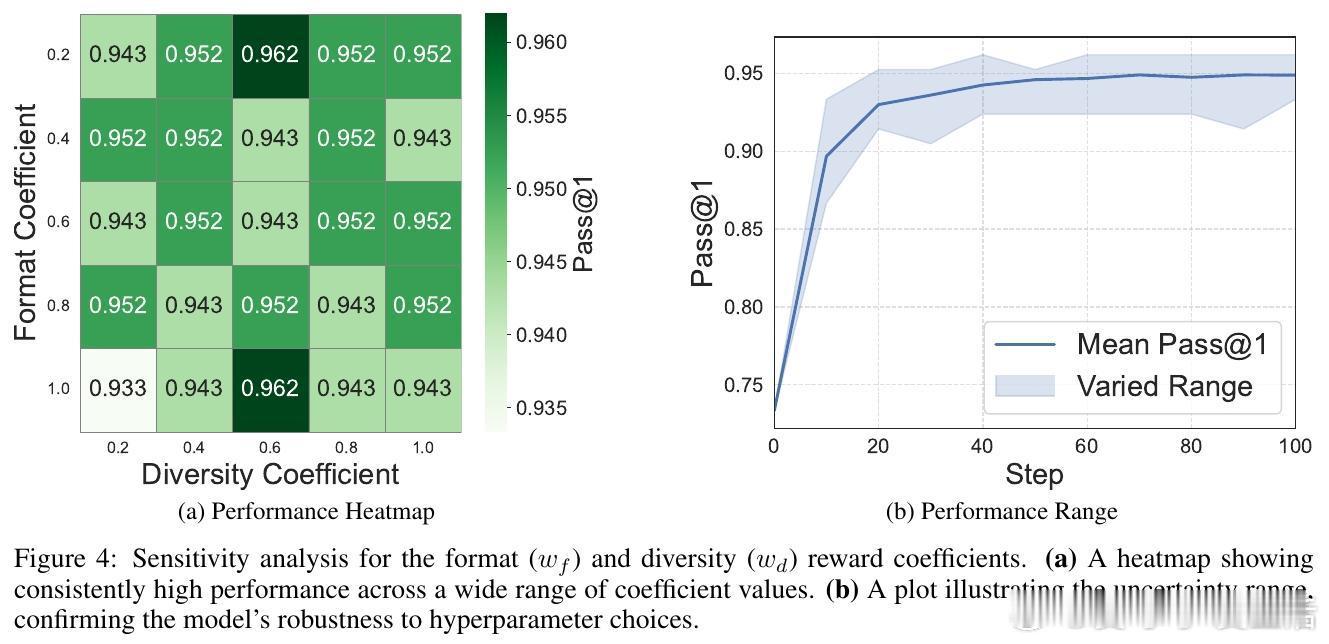
更深入地,作者从信息论角度证明,调和平均数是实现视角不变性信息最大化的二阶近似,天然兼顾答案的置信度和视角一致性。框架通过“解题→改写→解题”自我博弈结构,不断揭露和修正模型固有偏差。改写者策略引入多样性奖励,确保改写任务既语义等价又风格多样,强化模型对问题本质的理解。
总结来看,Self-Harmony不仅提出了测试时强化学习伪标签选择的新范式,还开创了单模型合作自我博弈的新思路,显著提升了大模型推理能力和适应性,免去了昂贵的人工标注与外部监督。这为未来无监督环境下的模型自我优化提供了坚实理论与实践基础。
详细论文链接:arxiv.org/abs/2511.01191
代码已开源,可复现实验:anonymous.4open.science/r/self_harmony-F58A
这一次,模型不再是自己的囚徒,而是真正学会了“和谐共鸣”——在多视角中找寻答案的恒久真理。如此,AI推理走出了孤岛,走向更稳健、更智慧的未来。