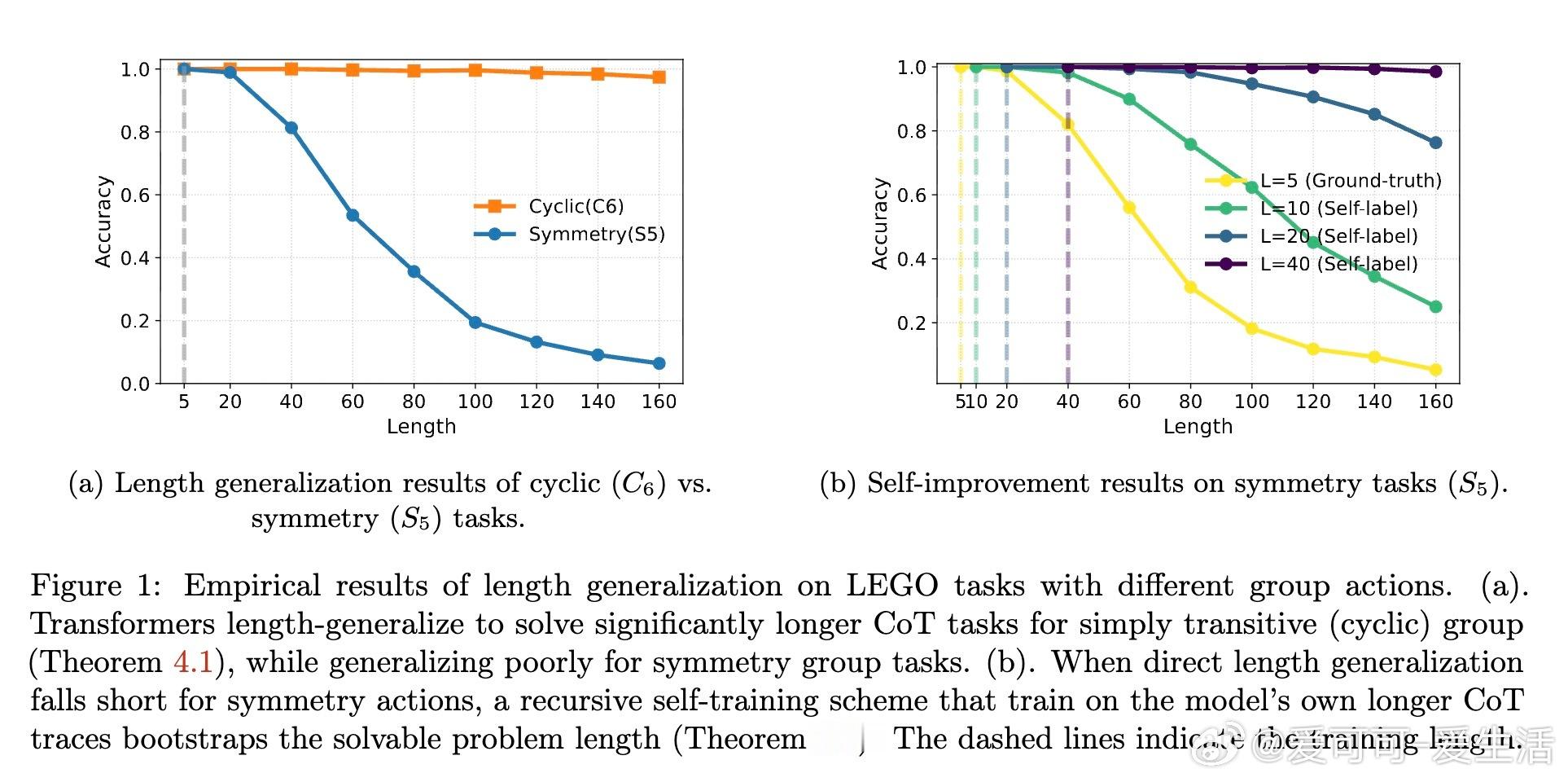
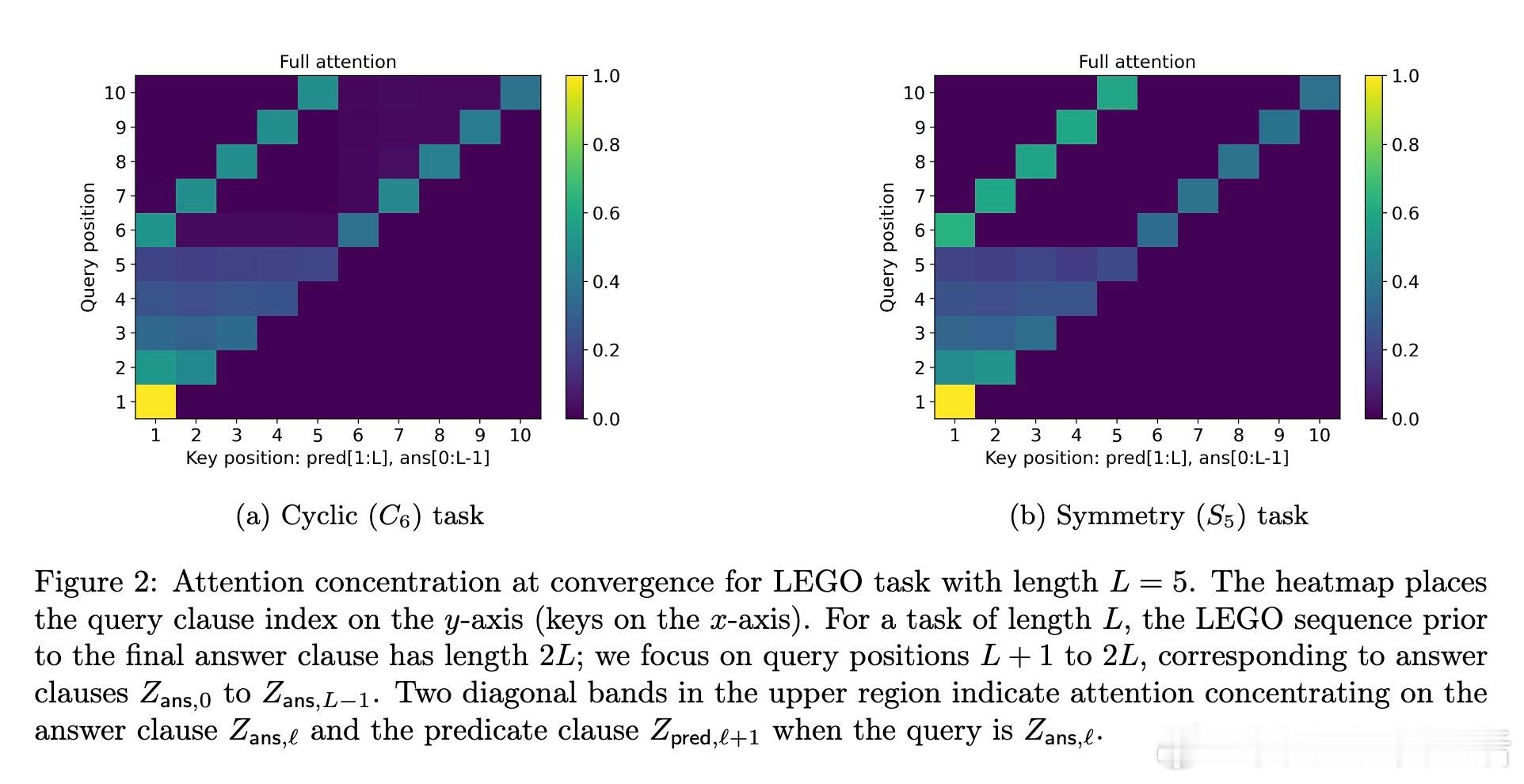
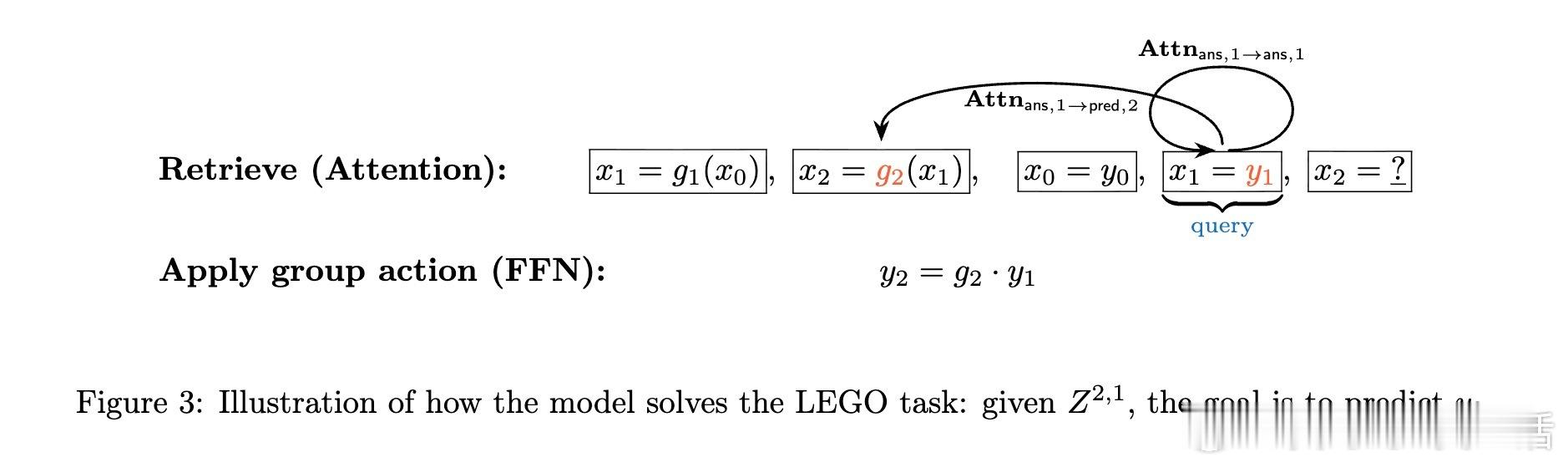
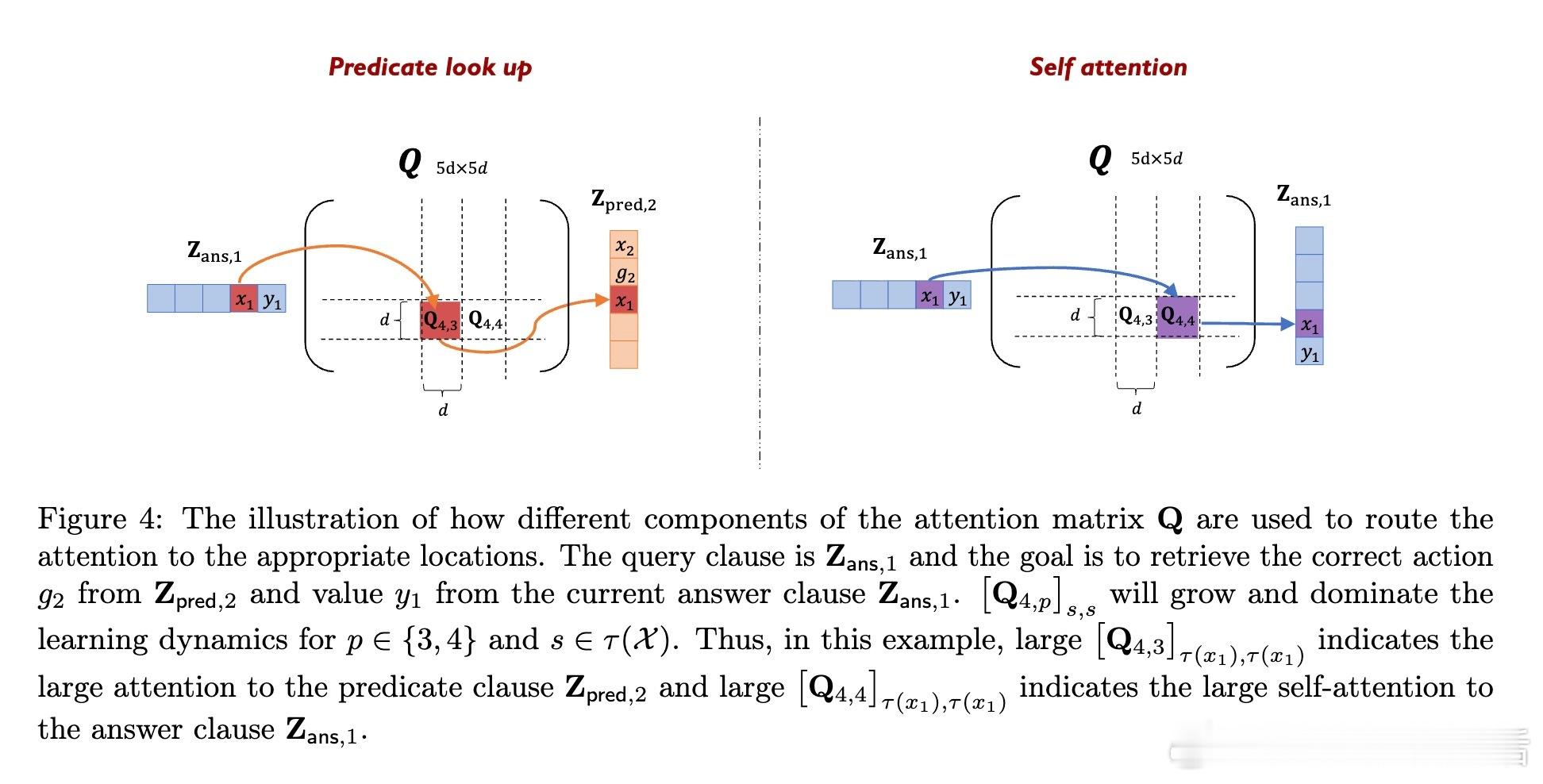
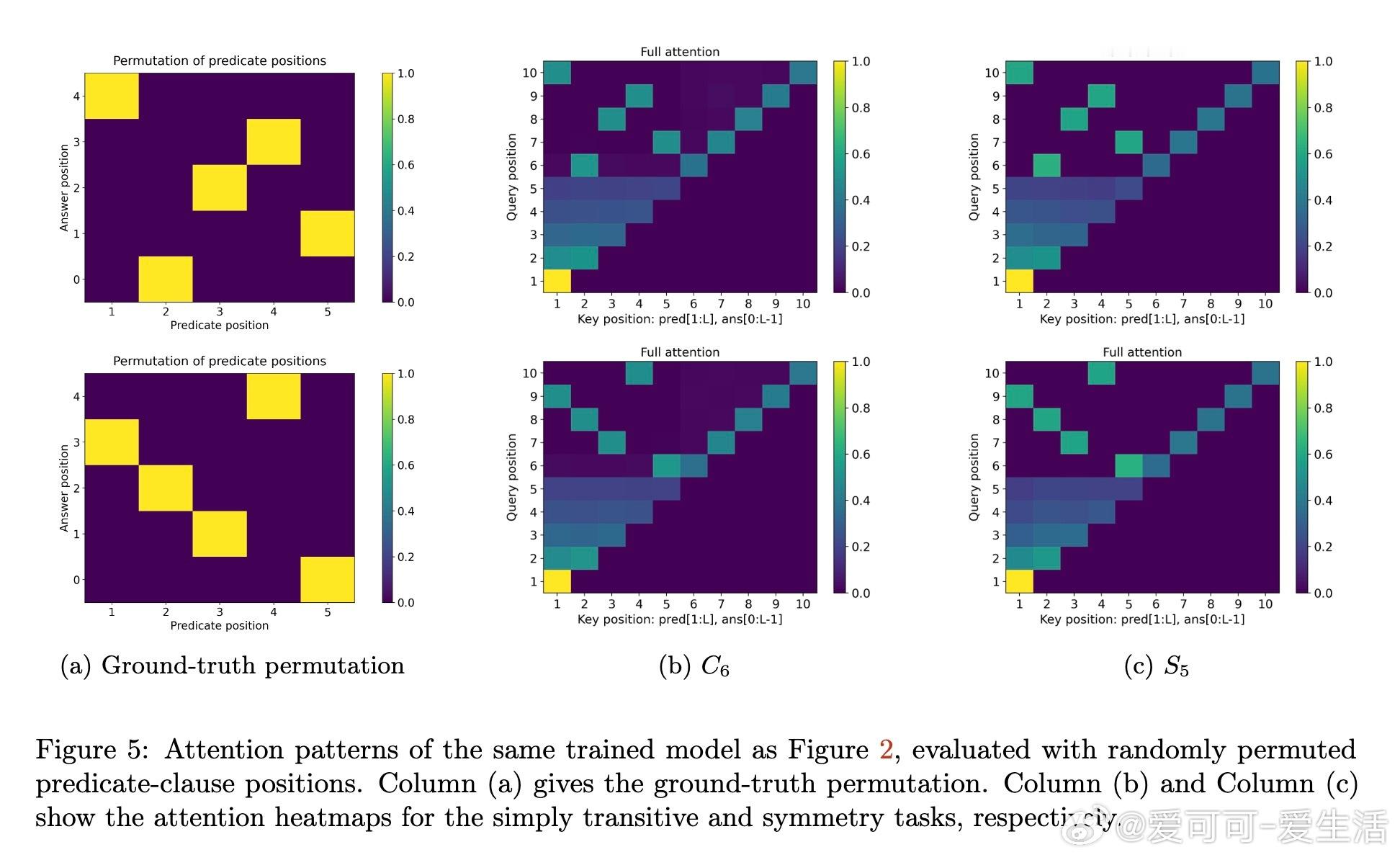
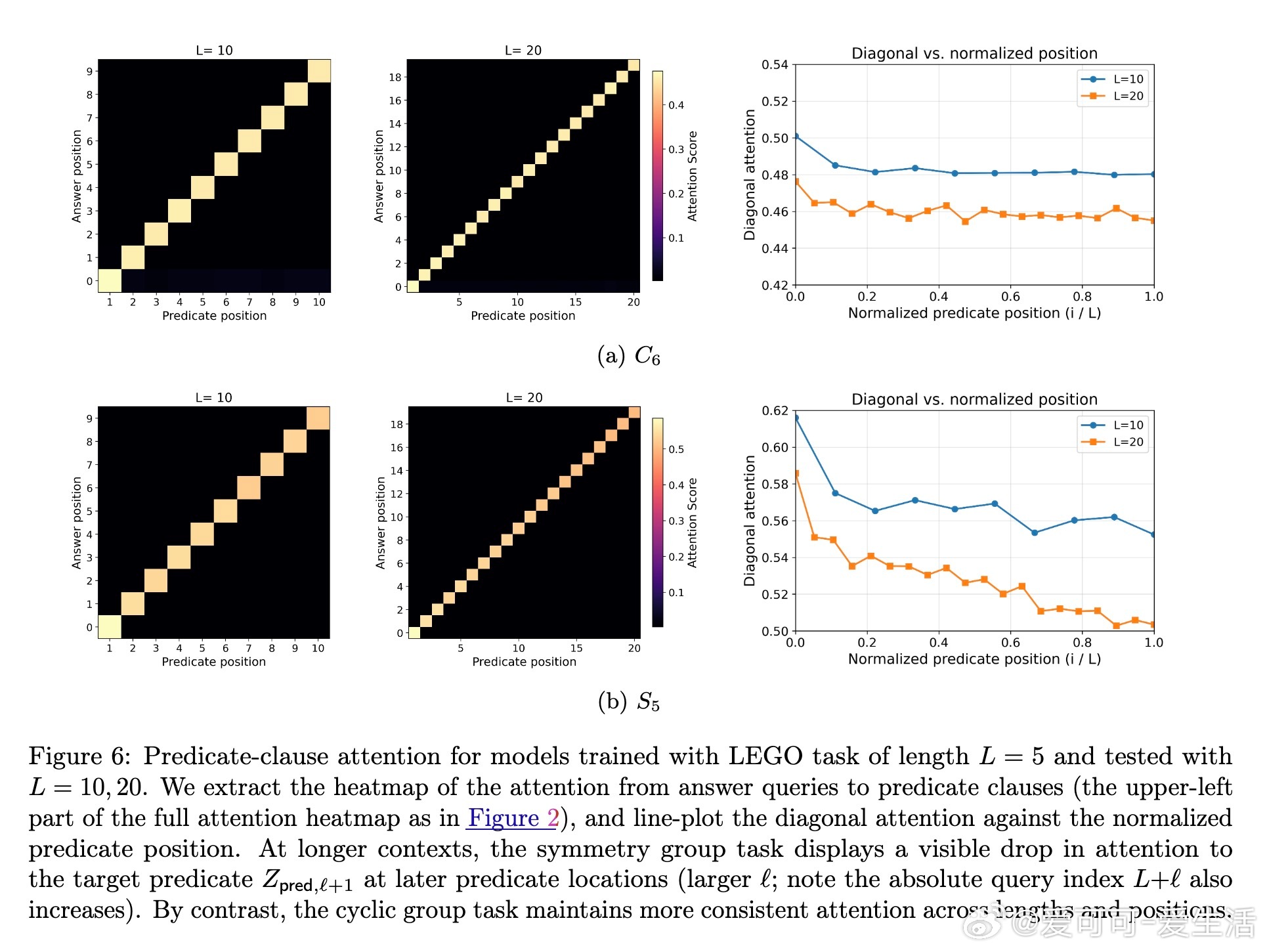
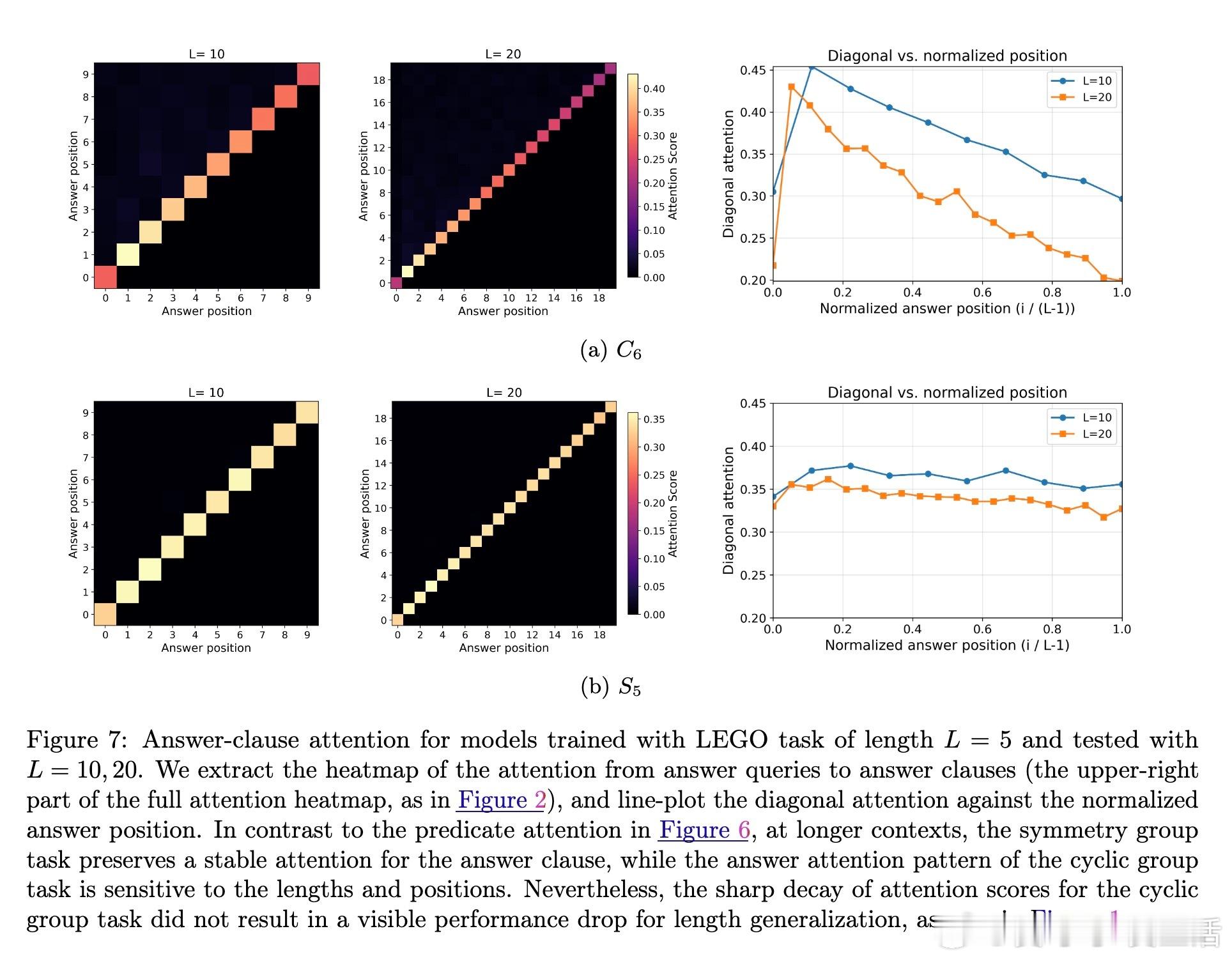
[LG]《Transformers Provably Learn Chain-of-Thought Reasoning with Length Generalization》Y Huang, Z Wen, A Singh, Y Chi... [University of Pennsylvania & CMU] (2025) 在人工智能领域,推理能力至关重要,尤其是解决复杂问题时需要更长、更深的思维链(CoT)。但一个根本问题是:模型能否通过学习的推理模式,跨越训练长度限制,解决更长链条的任务?本文给出了理论答案。该工作聚焦于Transformer模型在合成的状态追踪任务(LEGO)上的梯度下降训练,首次提供了学会CoT推理并实现长度泛化的优化保证。主要贡献如下:1. CoT推理的可学性与长度泛化保证 研究证明,一层无位置编码(NoPE)的Transformer通过梯度下降,在简单传递群作用(simply transitive group actions)下,能直接从短链训练泛化到多倍长度任务,且准确率接近1。对称群作用(symmetry group actions)则只获得常数倍泛化。2. 注意力集中机制揭示泛化差异 泛化能力取决于群作用的代数结构。简单传递作用促使注意力高度集中于关键上下文,支持强泛化;而对称群存在大量“干扰项”,注意力分散,限制泛化幅度。研究深入解析了这一机制。3. 递归自训练扩展推理长度 针对对称群作用泛化受限的问题,论文设计了递归自训练方案:模型用自身生成的CoT轨迹作为新训练数据,逐步提升可解的链长,理论上可达到最大长度,实现自我引导的能力提升。4. 突破复杂度界限,实现非平行任务的学习 研究首次证明,常数深度Transformer通过CoT能有效学习NC1完全问题(复杂度超越TC0),填补了表达能力与可训练性之间的鸿沟。5. 详实实验证实理论预测 实验使用循环群C6和对称群S5的LEGO任务,验证了泛化行为和注意力模式。递归自训练显著提升了对称群任务的推理长度,注意力热力图显示关键上下文检索的明确模式,且注意力聚焦与任务结构紧密相关。这项工作不仅为Transformer的CoT推理能力提供了首个严格优化理论,也为理解长上下文推理中的“context rot”现象提供了新视角:注意力的稀释导致性能下降。结果提示,无位置编码有助于泛化,因为模型基于内容而非位置检索信息,避免了位置嵌入带来的长度绑定限制。未来,结合局部聚合机制(如Cannon层)和递归自训练策略,有望进一步提升实际语言模型的长链推理能力和泛化性能。全文详情及数学证明见:arxiv.org/abs/2511.07378推理是AI的灵魂,理解其学习与泛化机制,是迈向真正智能的关键一步。正如本文所揭示:“长度的极限,不是模型的极限。”