为什么基座大模型的智能被大大高估?
我们感觉大模型很聪明,啥都懂。最近大进步是,幻觉越来越少,会反复搜索,还会验证信息。
其实,即使是最简单的聊天,我们都不是和大模型直接沟通。只有API调用是,一般人接触的是“编排”程序。如聊天,就是非常复杂的程序,组织搜索才能幻觉很少。和大模型API聊很不对劲,记忆都没有,没搜索幻觉无数。一个常识是,现在我们聊,都会有一堆背景知识输入给基座大模型,才能不幻觉。
大模型开发者搞的非常复杂的“编排”,以及后训练,才是智能的核心。例如Claude Code的源代码泄露了,就可以看出为了调用Claude Opus基座大模型,编排复杂到了什么程度。光有Claude Opus 4.8,编程根本不行。
大模型应用感觉不错,这并不是说基座大模型厉害,实际缺陷严重,只是一个工具。
我用一个例子来说明,为什么基座大模型,智能并不高。
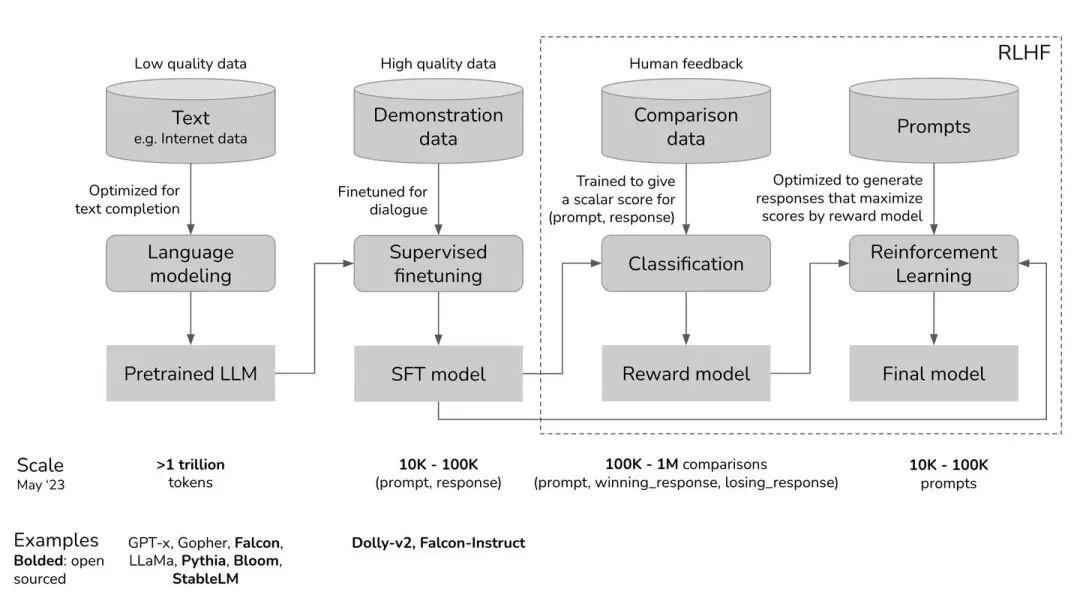
把基座大模型理解为,包含人类全部知识的100万本书当训练语料,预训练的结果。语料有10-20万亿token,而大模型系数是1000亿-1万亿规模,相当于压缩存储。
开发一个简单聊天程序,看了人的话,就到那100万本书中挑一段能接上的输出。这个“念书程序”,传统的向量文本匹配技术就行,没有任何智能。一些人觉得这程序能接上话,以为它什么都懂。但很快就露馅了。
基座大模型也是检索匹配,但基于概率算token之间的关系,不是机械念书。它这念一段,那念一段,不是原样复述有改写,可以把这个叫“高级念书程序”。它实际不懂在聊什么,只是找合适的词念经一样输出,佛教的念佛经,道教的念道经。开发者把概率选择固定,它对同样的输入输出还会一样。
高级念书是智能么?有争议。它对100万本书有理解,在数据结构里,是固定的系数组合。人类大脑表面上类似,神经网络互联连接,但要复杂强大得多。有记忆,能接受物理输入,能指挥手脚行动,很灵活。这些基座大模型都没有,结构很简单,就是对token知识有了一个死的“理解”。
预训练结束后,基座大模型的理解其实很差。2020年GPT3,外界基本不知道,只有圈内少数人觉得“有点什么”。它唯一的手段是“预测下一个token”,强行弄出了一个理解结构,不可能很对。有时感觉“这段话说得还不错,像智能”,但很多话就是形式主义,看多了知道是弱智。如果基座大模型就是这个能力,没有人会认为它是大突破,真会被认为是“高级念书”程序。聊一阵子就能看穿本质,根本不智能。
真正让人们感觉不错的,是“后训练”。人和大模型聊,不对就改进系数,改进多了人就满意了。人聊太慢,训练模仿人类对聊天满意度的打分器,机器聊自动打分。这就是RLHF,人类反馈的强化学习。基座大模型只知道这样输出人会满意,不知道原因。有时知识结构理解不对,也会改进。不断改进,人类就基本满意了,有ChatGPT的水平了。
再之后就有更多离奇的“后训练”,脱离了常规思维,是一些工程化套路明显的训练。如“tool”,训练大模型给出工具选择,一般人不会去学这些东西。很多专门技术能都去后训练,上百种,主要算力搞后训练了。有些训练很不自然,是为了干agent之类的活。例如看几百万个程序代码,还去实际跑看结果,这样学编程。人类没体力去这样学,编程不行能解释。
这种“非人类”的学习很多,最后大模型学会了不少本事。以前简单模型也能学会认字符、下棋等单一本事。基座大模型规模大,学了一堆本事,后训练一个个教。也有学不会的,如“数数”学不会,原理限制。
基座大模型是“高级念书”+“工具技能”的组合。单一技能都是以前的技术可以想象的,但都组合进来了。所有技能有统一特征:对token输入给出token输出。神经网络训练框架可以理解,只是以前搞这么大规模没算力。这条路线是技术发展的自然结果。
人类开发者除了后训练,还开发了厉害的编排程序。用多了大模型,再明白技术原理,许多应用案例都能看出人类开发者的智慧。基座大模型的智能被大大高估,还是人类智能厉害,大模型是实现人类开发者的意图,是个程序。