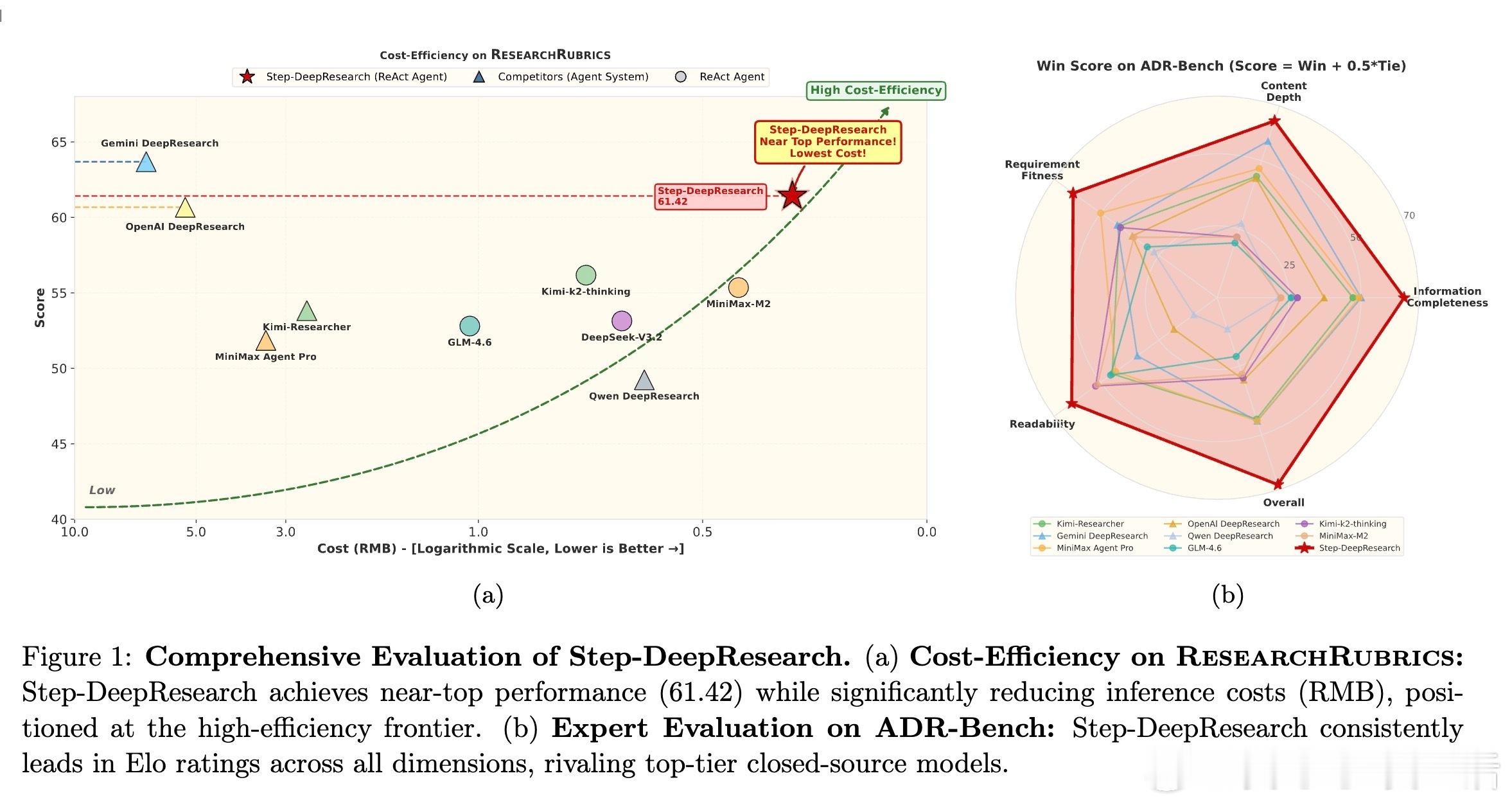
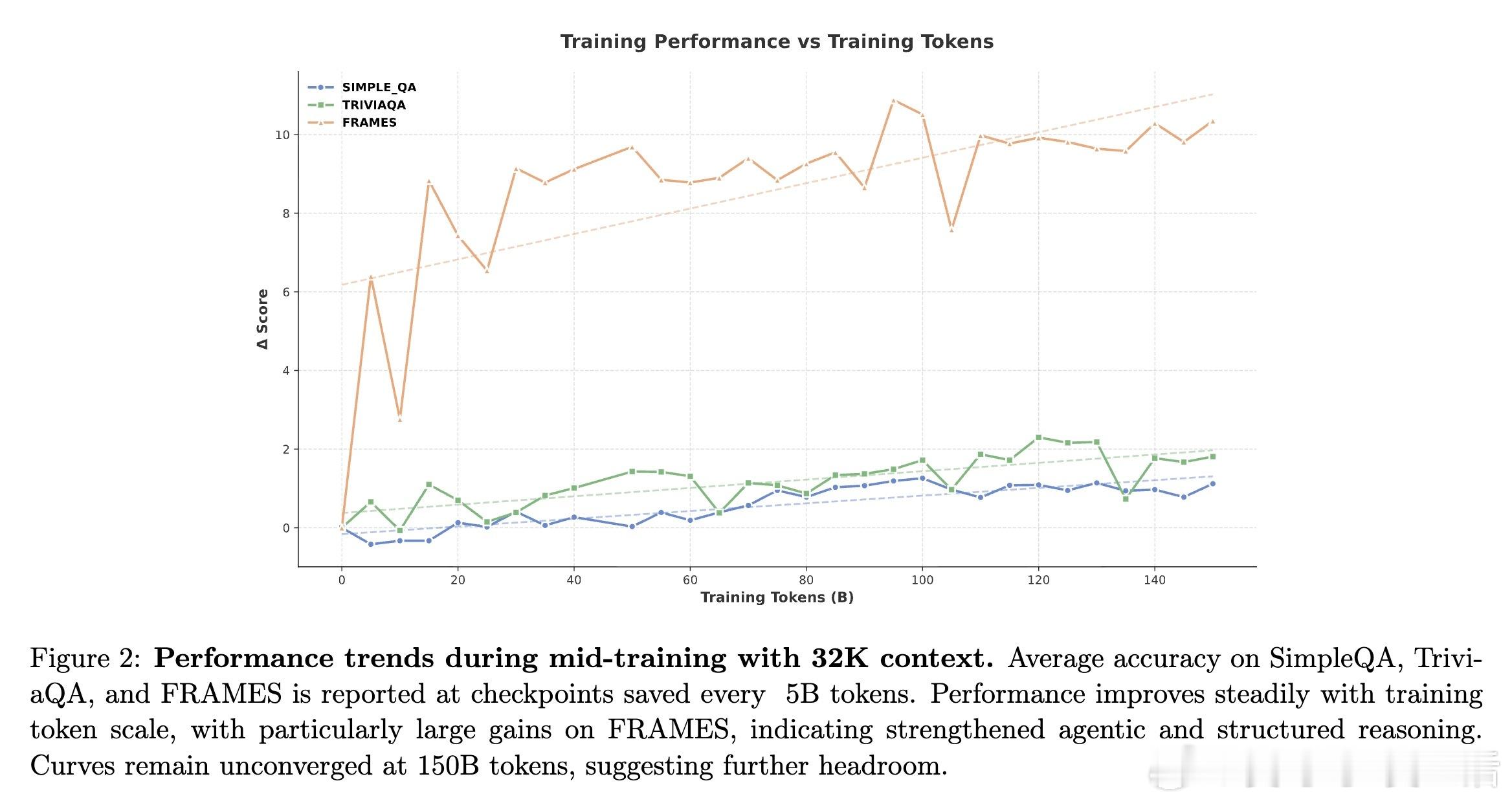
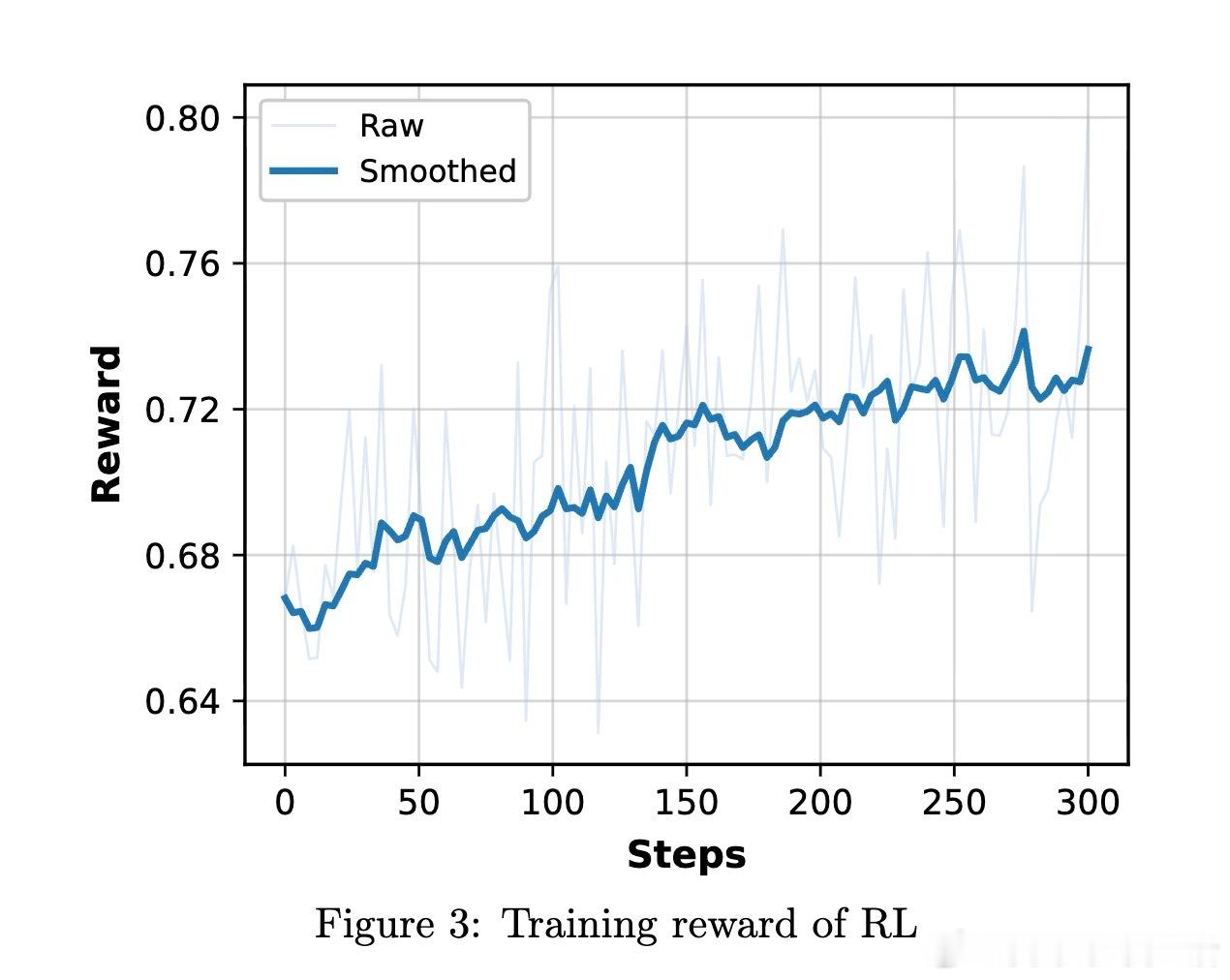
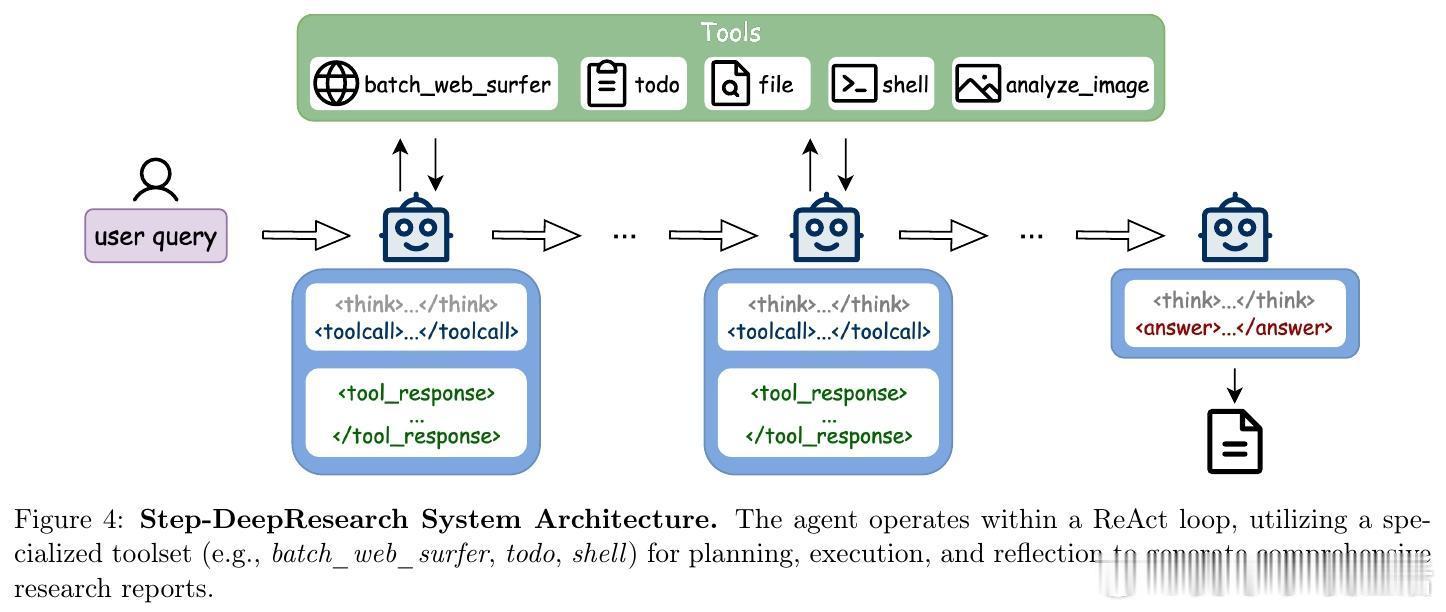
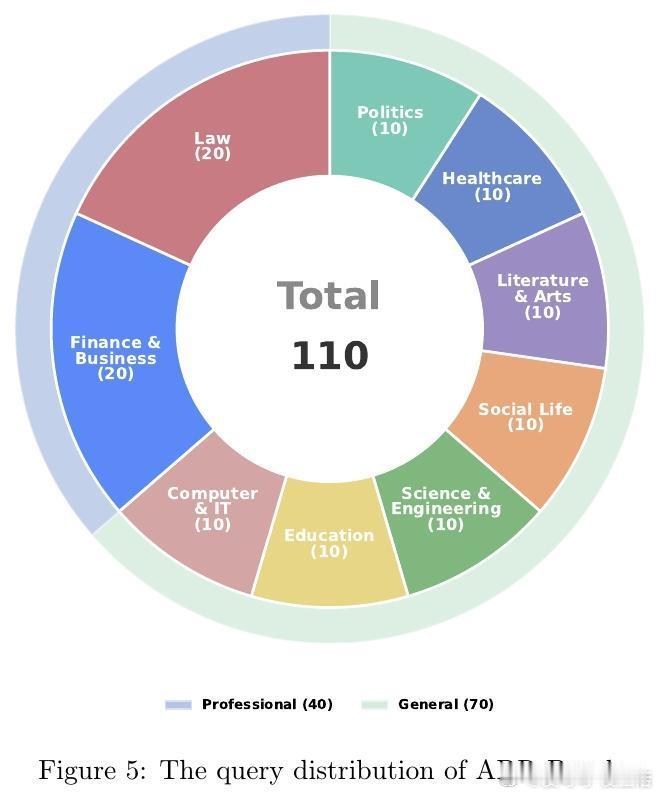
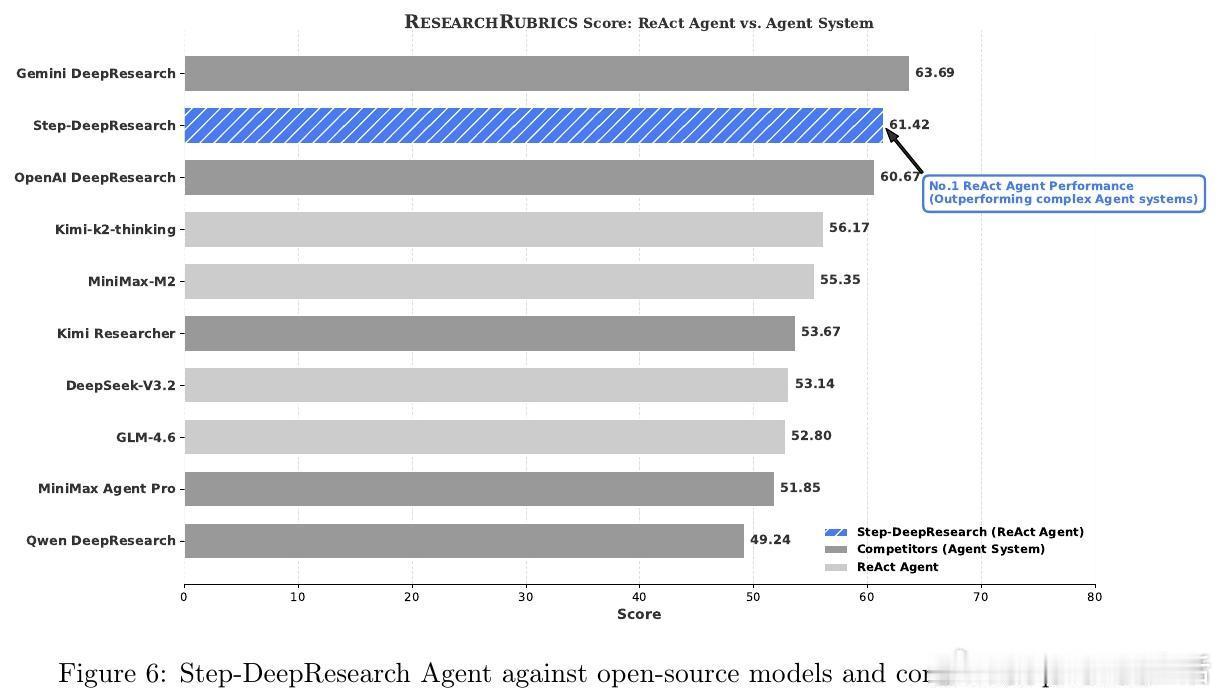
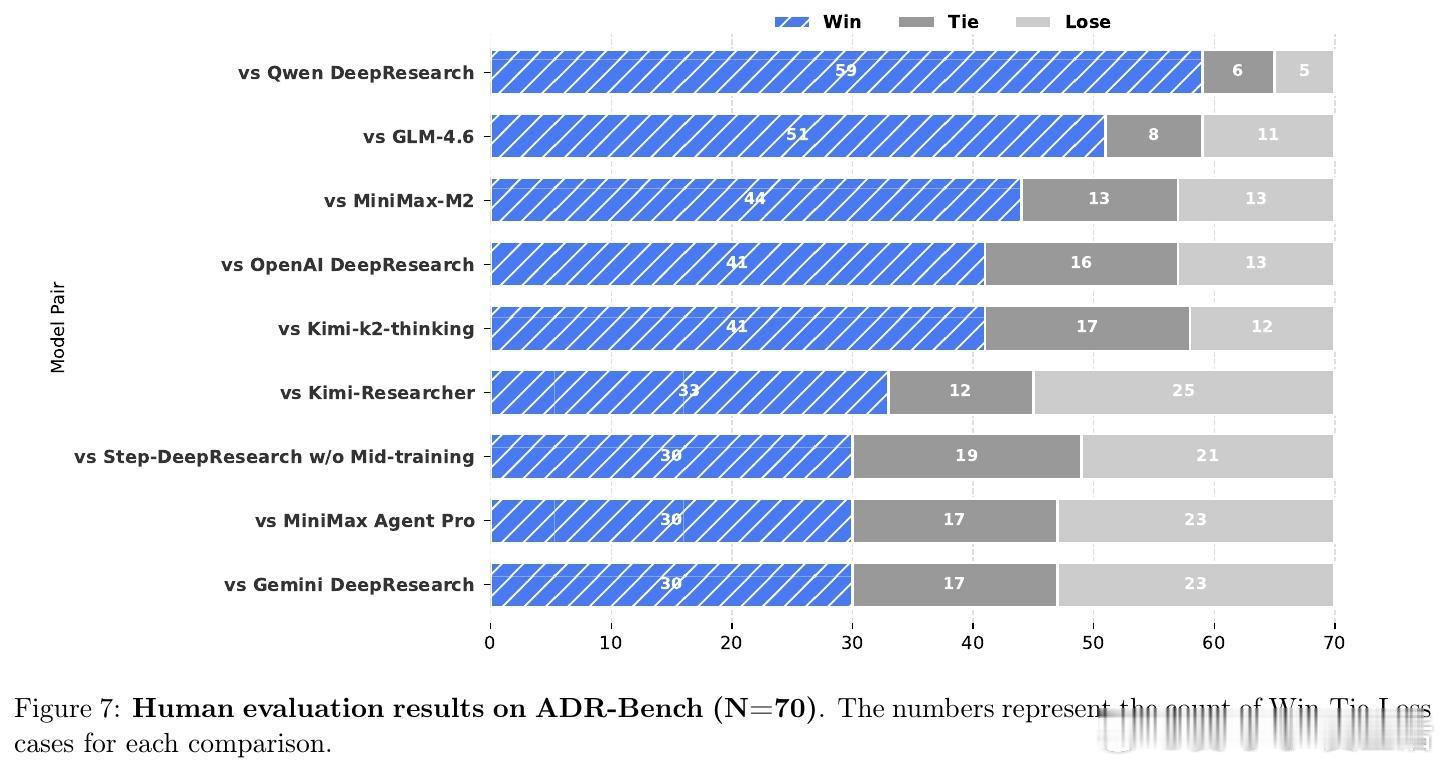
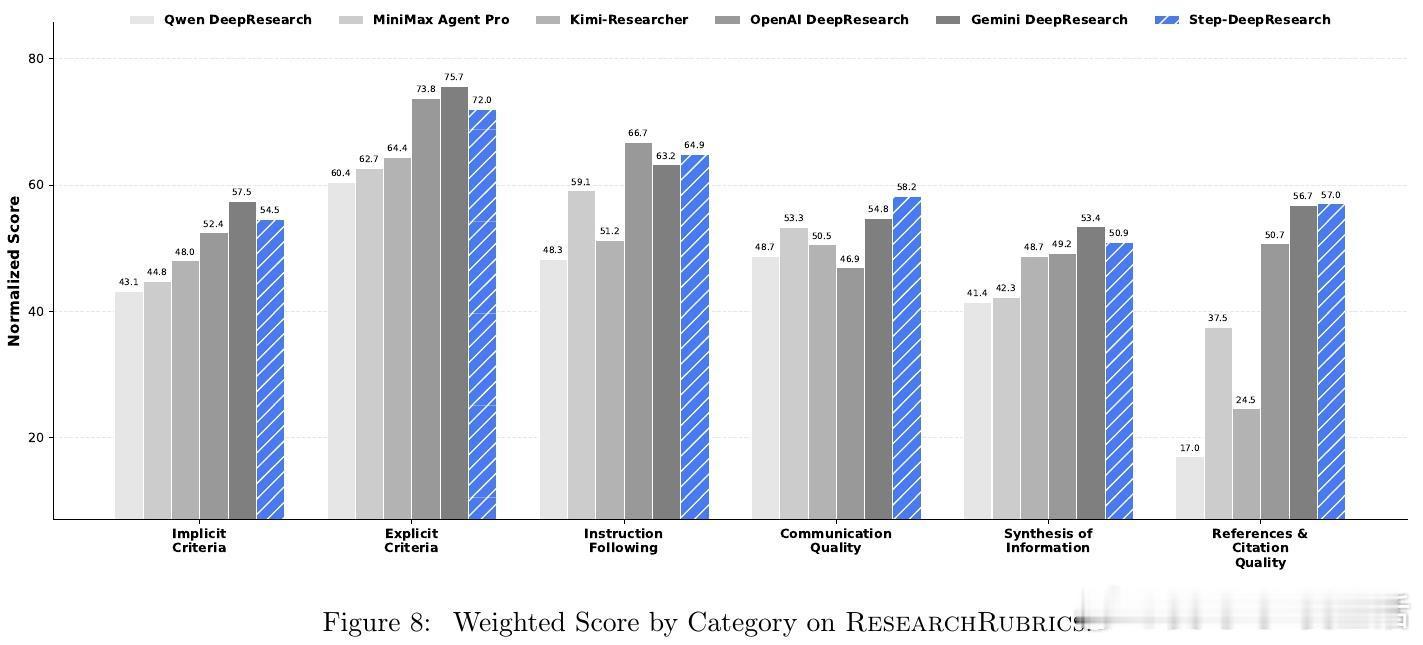
[CL]《Step-DeepResearch Technical Report》C Hu, H Du, H Wang, L Lin... [StepFun] (2025) 搜索不等于研究。真正的研究是一场关于意图识别、长程决策与逻辑构建的马拉松。阶跃星辰(StepFun)发布了 Step-DeepResearch 技术报告。这不仅是一个模型,更是一套让 AI 从简单的网页搬运工进化为深度研究员的完整方案。以下是这份报告的核心洞察与技术精要:搜索与研究的本质区别传统的搜索往往止步于获取已知事实,而研究需要将碎片化的证据整合为有说服力的论点。报告指出,目前的 AI 代理往往过于依赖多跳搜索,导致其更像高效的爬虫而非深思熟虑的学者。Step-DeepResearch 的目标是让模型内化专家的认知闭环:在执行中自我检查,在迷雾中动态修正。32B 模型的以小博大令人惊讶的是,Step-DeepResearch 仅基于 32B 参数规模,就在性能上比肩甚至超越了 OpenAI 和 Gemini 的顶级闭源服务。其在 ResearchRubrics 基准测试中获得 61.42 的高分,而推理成本仅为顶尖模型的十分之一。这证明了通过精细的训练策略,中等规模模型也能触及专家级能力的边界。原子能力的解构与重组研究能力不是一种单一的技能,而是四种原子能力的交织:- 规划与任务拆解:利用逆向工程,从高质量报告中反推研究路径。- 深度搜索与信息获取:基于知识图谱采样,训练模型在信息不全时主动进行拓扑行走。- 反思、验证与交叉验证:构建错误反思循环,让模型学会质疑互联网信息的真实性。- 报告生成:从领域风格的内化到严格的引用规范,确保输出既专业又严谨。创新的三阶段训练管线- 代理中训(Agentic Mid-training):从 32K 到 128K 长度的课程学习,将预测下一个 Token 转化为决定下一个原子动作。- 有监督微调(SFT):通过最短路径原则优化轨迹效率,注入结构化噪声以提升模型在工具失效时的鲁棒性。- 强化学习(RL):采用基于 Rubrics 的奖励设计,利用 PPO 算法在真实环境下进行试错学习。专为研究设计的系统架构模型采用简洁的 ReAct 单体代理设计,辅以强大的工具箱:- 权威增强检索:物理隔离低质信息,优先索引 600 多个核心权威站点。- 补丁式编辑(Patch-based Editing):针对长报告修改,将 Token 成本降低 70% 以上。- 状态化待办管理:解构研究进度,防止长程任务中的目标漂移。ADR-Bench:填补中文深度研究评测空白为了解决现有基准测试偏向学术或简单搜索的问题,团队构建了 ADR-Bench。它涵盖法律、金融、科技等九大领域,引入人类专家 Elo 评级。实验显示,Step-DeepResearch 在中文语境下的实用性表现极佳,尤其在金融与法律等专业领域展现了极高的知识覆盖度。深度研究是通往通用人工智能(AGI)的一颗北极星。当 AI 能够独立完成复杂的行业调研、政策分析和技术论证时,它就从对话助手真正变成了生产力伙伴。技术细节详见:arxiv.org/abs/2512.20491