今天看到Force大会上公布了一组数据,让我觉得现在这个阶段有必要重新聊聊国产大模型现在走到哪了。
真的完全超出预期。
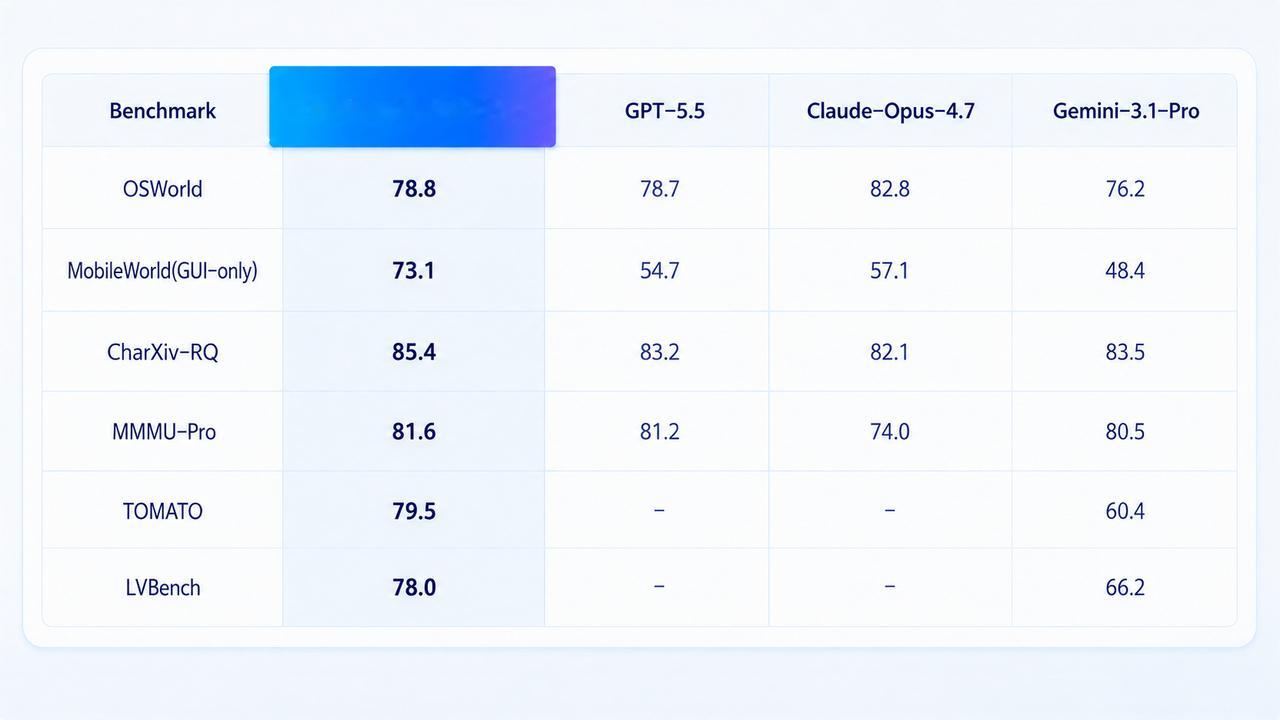
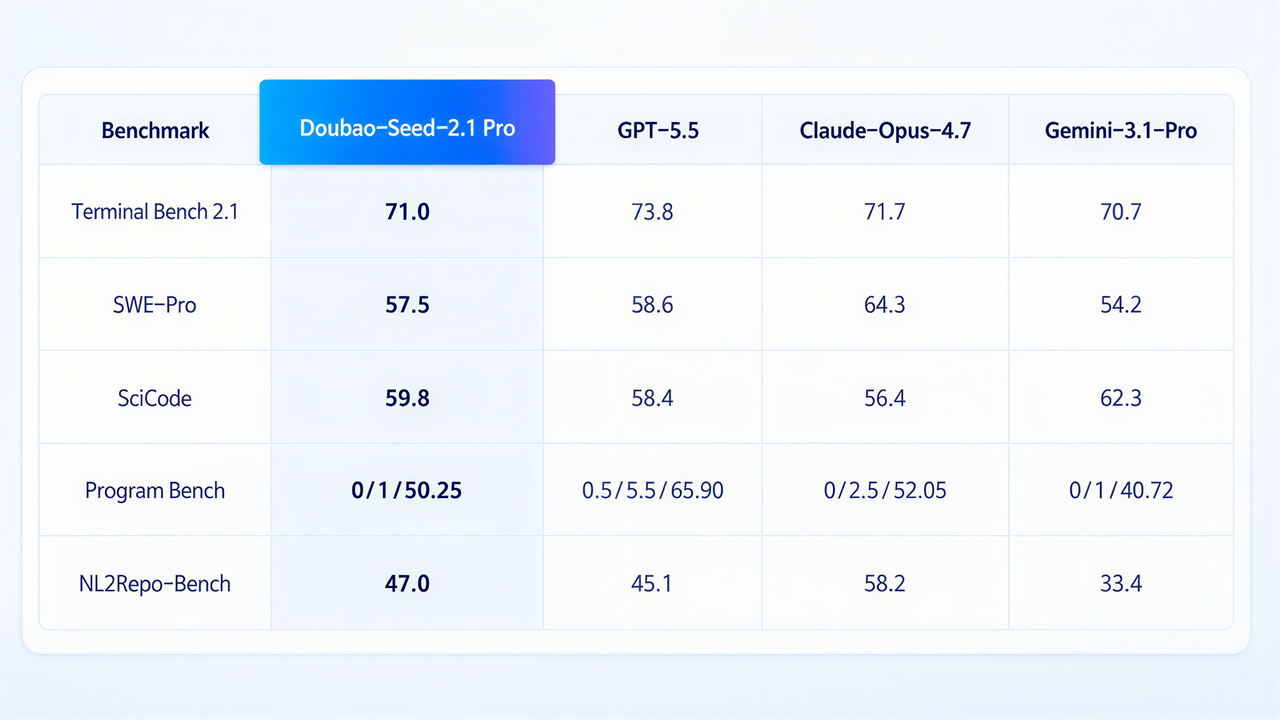
火山引擎发布了豆包大模型2.1 Pro,在Terminal Bench 2.1这个业内公认最贴近真实研发环境的编程评测上,和Claude Opus 4.7基本打平了。
Claude Opus 4.7,目前全球公认Coding能力天花板级别的模型。
不只是这一个单项,SciCode科学计算评测,豆包2.1 Pro拿了59.8,超过Opus 4.7,也超过GPT-5.5。NL2Repo-Bench仓库级代码生成,47.0分,领先GPT-5.5和Gemini 3.1 Pro。
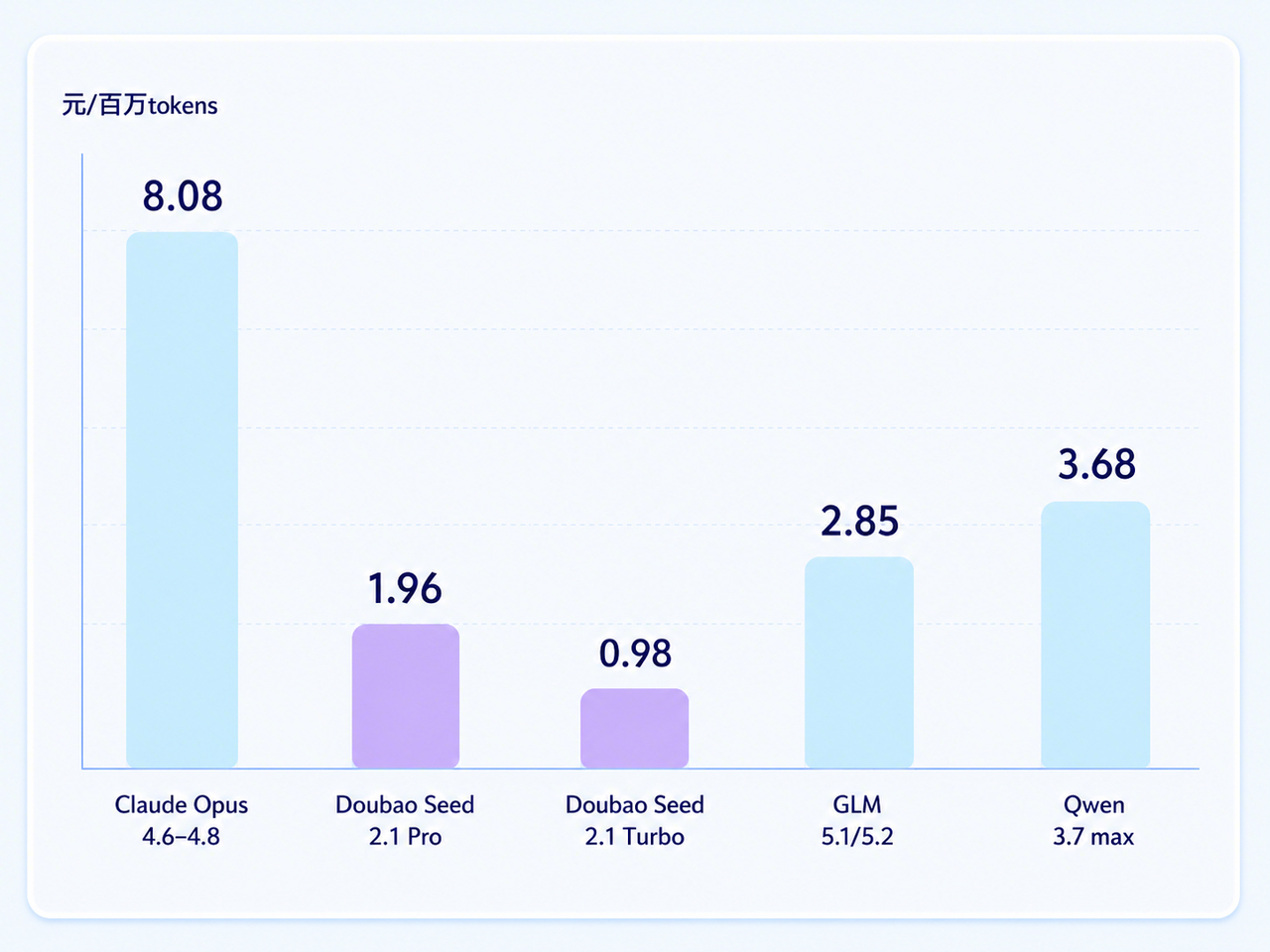
而价格,只有Claude Opus系列的大约两折。
一年前如果有人跟我说,一个国产模型能在多个核心Coding评测上跟Opus正面对线,同时价格便宜80%,我会觉得非常扯淡。
但数据现在就摆在这了。
比起跑分本身,我觉得更值得聊的是这件事背后的一个规律。
1
过去半年,我有一个很强的体感:大模型的能力提升,并非是匀速的。
它不是每个版本比上一个版本好5%、10%这么线性地往前走,而是会在某个版本上突然跳一个台阶。
这个跳跃节点,可以称之为大模型的「质变点」。
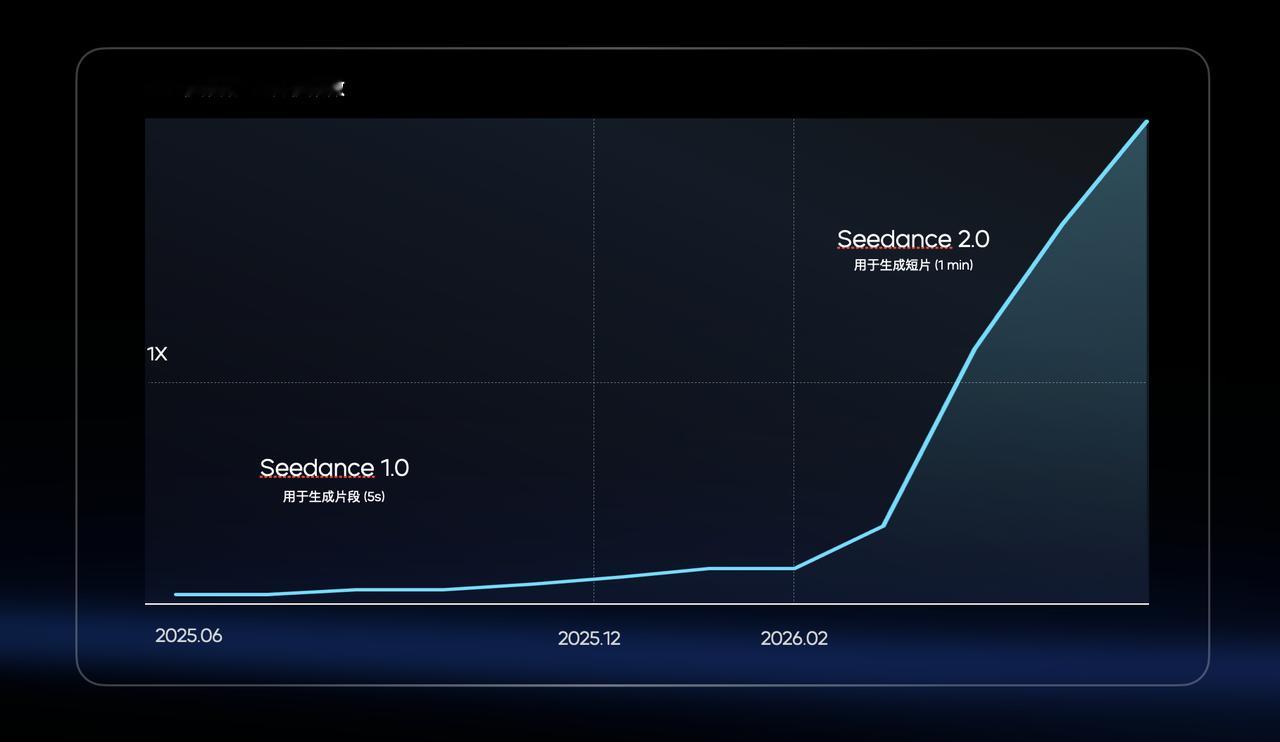
比如去年AI视频最火的时候,很多人都在玩,但真正做商业内容的人其实很痛苦。5到10秒的视频内容还凑合能看,但再长一点,人物一致性就直接崩了。
但Seedance 2.0出来之后,15秒到30秒的商业短片突然变得可控了。
同一批客户,之前还是在试水,之后直接把AI塞进了生产线。
这中间没有什么渐进过渡,就是一个版本的差距。
Coding和Agent赛道也在经历同样的事情。
2
Coding方向的质变点是什么时候出现的?
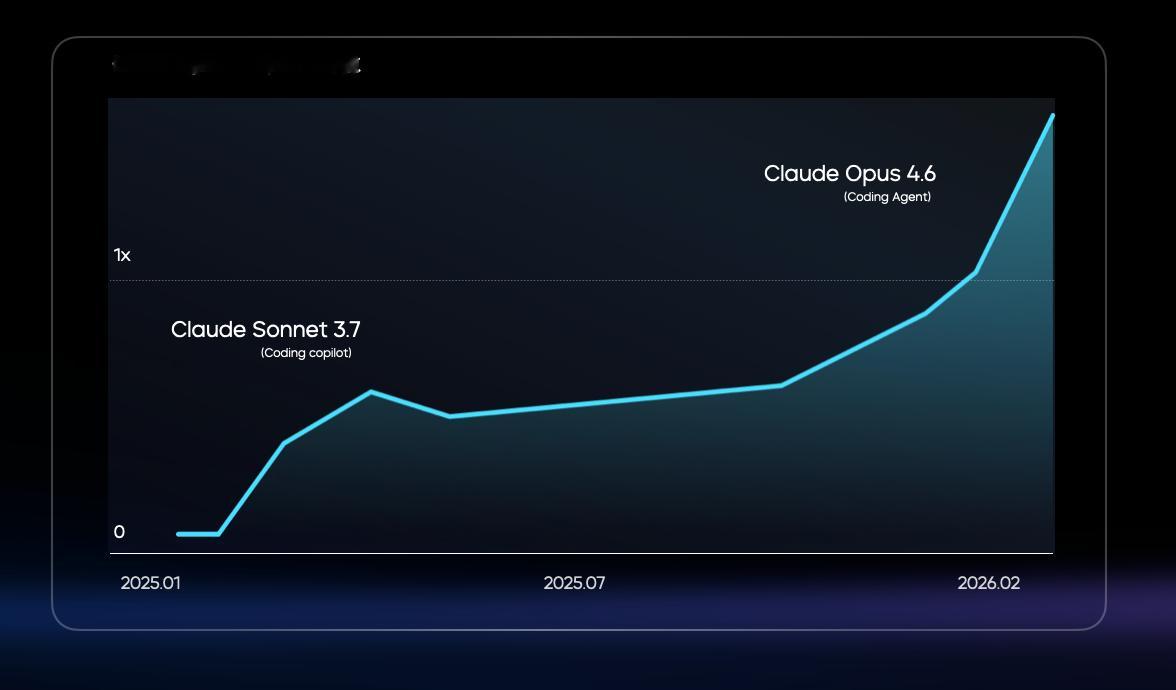
回头看数据,比较明确的一个标志是Cursor公布的那组Agent和Copilot需求对比。
早期Copilot模式占绝对主流,开发者让AI补补代码、写写函数,本质上还是人在主导。
但从某个节点开始,Agent模式的需求快速反超了Copilot。
不是缓慢追赶,是突然反转:开发者开始信任模型去独立完成更完整的工程任务了。
这种信任不是凭空来的,它需要模型证明自己能扛得住真实场景的压力,面对一个有历史包袱、有复杂依赖、有工程规范要求的完整项目。
火山引擎这次在Force大会上发布的豆包2.1 Pro,从开头我们提到的几个核心测评的表现来看,确实已经摸到了这条线。
但跑分只能说明下限,让我觉得比较有意思的,是它跑的一个实际案例。
3
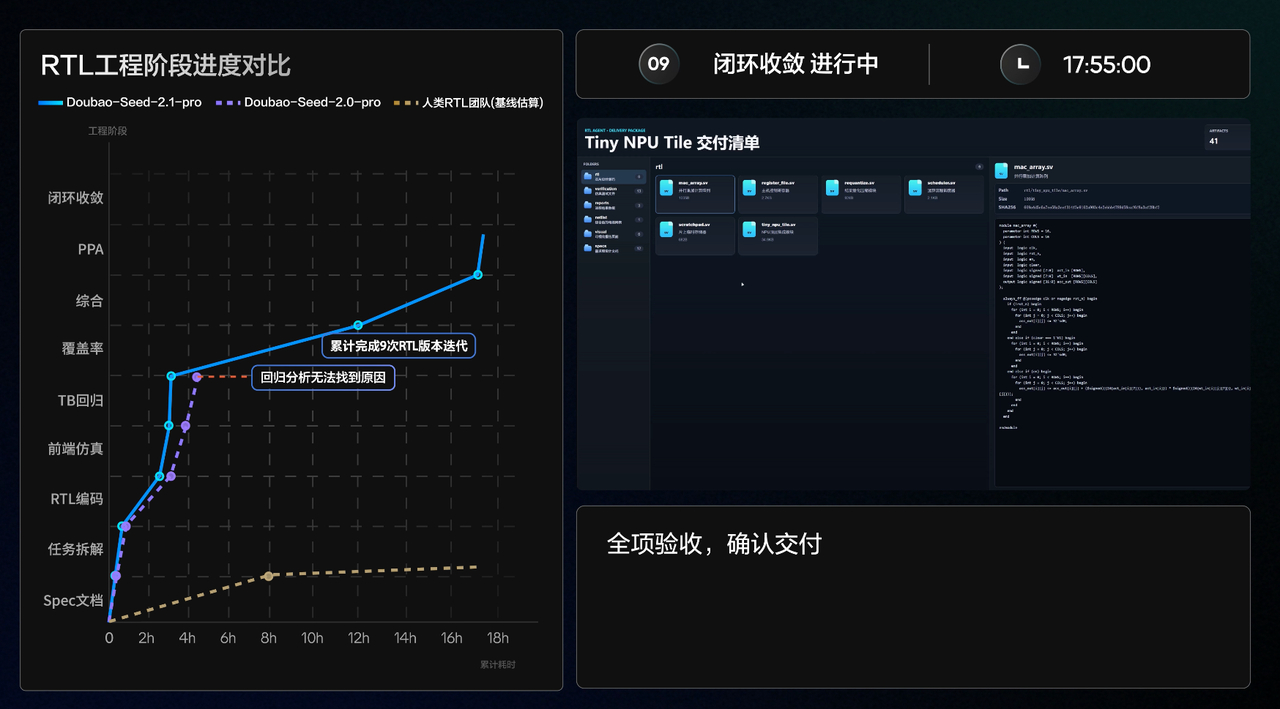
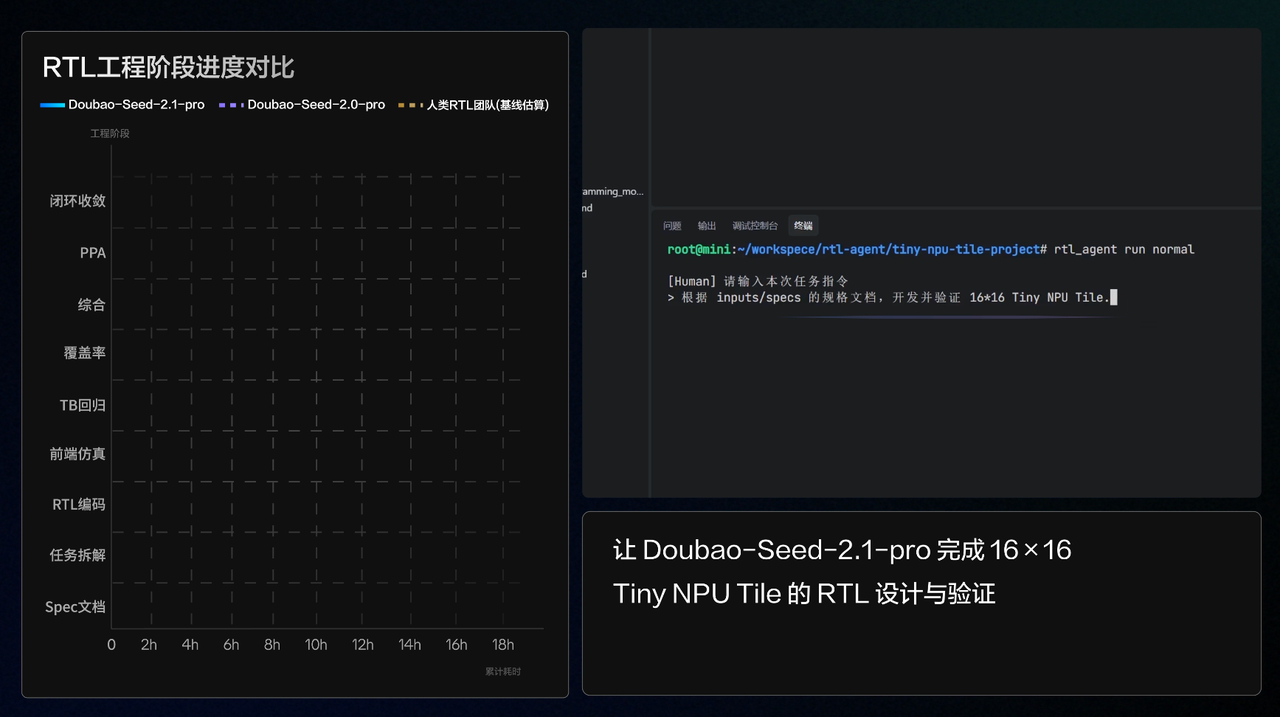
他们团队拿豆包2.1 Pro去做了一件事:芯片设计的RTL全流程。
稍微解释一下,RTL是芯片设计里最核心的环节,你要把每个寄存器、每条信号线在每个时钟周期里的行为精确描述出来,出一个错整个芯片逻辑就可能报废。
正常情况下,三到五名资深工程师花好几周才能搞定,中间要反复验证、反复修正。
豆包2.1 Pro围绕一个16×16 PE的Tiny NPU Tile,连续跑了将近18个小时,经历9轮自主迭代,最终输出6个核心模块、1303行RTL代码,跑通了仿真、测试、综合检查等全套工程流程,最后通过了手写数字识别的功能验证。
这个案例背后展现出了此前很少见的能力组合:理解硬件工程的整体架构,做长程规划,出错时自主修复,一轮轮迭代直到最终交付,属于真实工程场景里的生产级 Coding 交付能力。
4
再说Agent,这也是很多人低估的一个方向。
Agent场景下,一个任务往往包含多轮推理、多次工具调用、多步骤执行。模型要先拆解需求,再调用不同工具分步完成,中间还得自己判断哪一步需要返工。
这意味着Agent场景下,模型的稳定性和工具调用能力变得极其关键。
豆包2.1 Pro在MCP-Atlas评测上全面超过Opus 4.7和GPT 5.5,这个评测覆盖36个真实MCP Server、220个工具、1000个任务。
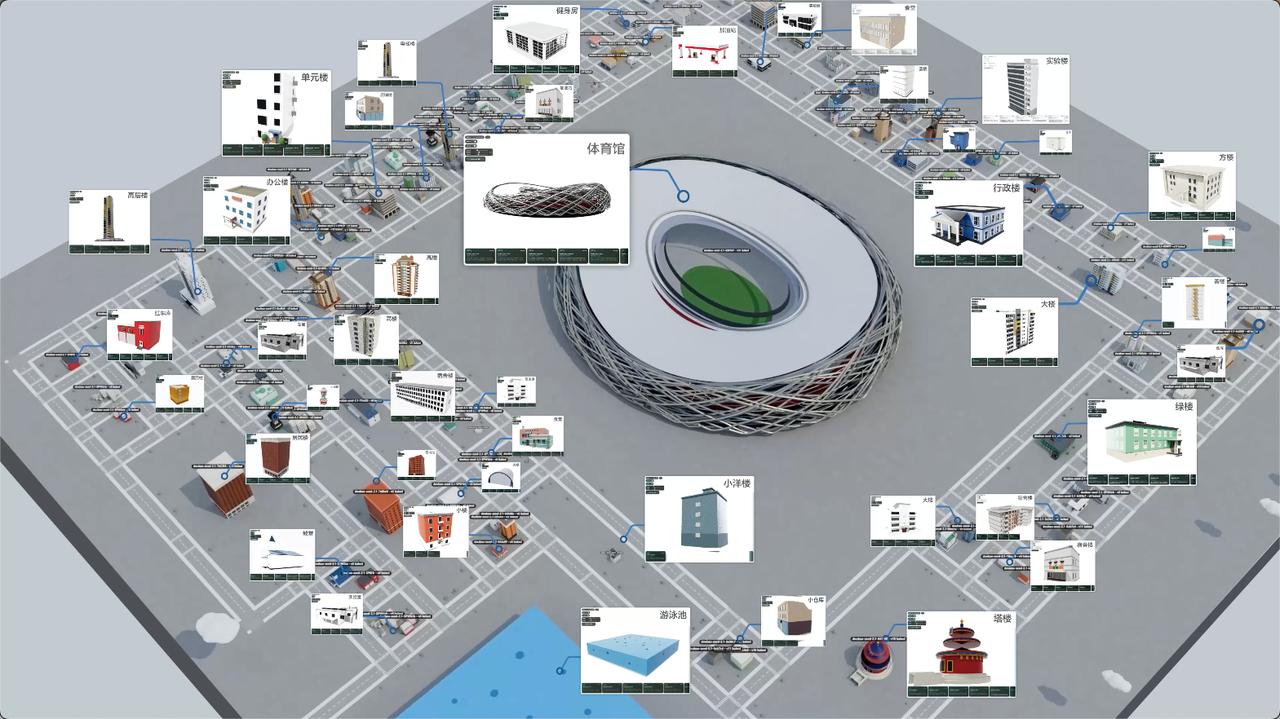
比如,有开发者用豆包2.1 Pro搭了一个多模态3D城市构建系统。
调度500多个Agent协同工作,串联建模、渲染、贴图等十几种工具,工具调用累计上千次,最终在同一张地图上建出100多栋造型各异的建筑,还完成了多轮自我迭代和全景合成。
500个Agent同时跑、上千次调用不崩溃,这放在一年前是很难想象的......
5
最后聊一下价格,因为这是影响企业是否真正采纳的最后一道门槛。
前面提到了,豆包2.1 Pro综合成本大约是Claude Opus系列的两折。
具体来说,百万Token输入6元、输出30元,缓存命中条件下输入只要1.2元。如果调用量更大,还有Turbo版本可选,能力保持较高水准,价格只有Pro的一半。
价格这件事常常被低估。模型跨过质变点是前提,但如果调用成本太高,大部分企业只会小范围试试;只有成本降到一定程度,原来算不过来账的场景突然就能算过来了,调用量自然会出现一个跳升。
大模型的进步不是一条斜线,而是一个台阶。能跳上去的模型,会在很短时间内改变大量场景的可行性。
豆包2.1 Pro是不是已经跨过了这条线?
从数据和案例来看,至少是非常接近了。对于正在做模型选型的团队来说,建议自己跑一下。