ECI分数说明,大模型能力接近没有加速,中国开源大模型在逼近。AI泡沫什么情况不好说,美国大模型是泡沫可以确定了
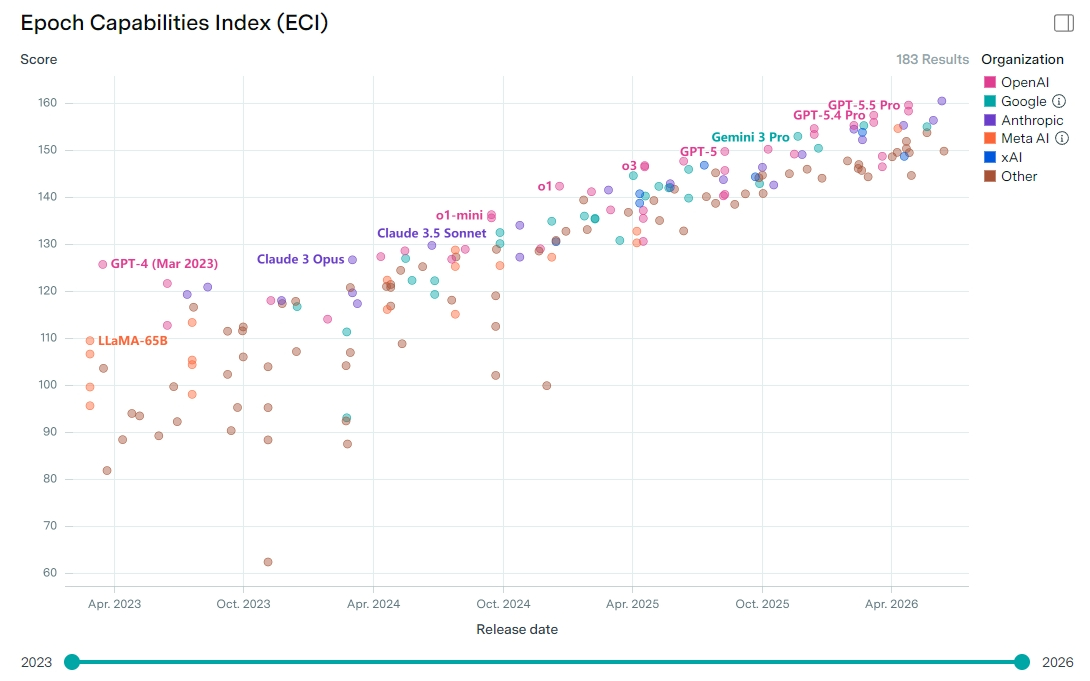
1. 图为Epoch.ai做的Epoch AI能力指数(ECI)。2023年,各家的实力差距比较大,上下分布比较散。2026年,几家实力差距明显缩小,都集中在150-160之间。图中美国有五家,OpenAI、Anthropic、谷歌三家实力强,xAI最近掉队了,Meta早就掉队了。而图中的Others,基本全是中国开源大模型,唯一例外是法国的Mistral,分也不高。
2. 分最高的是Claude Fable,ECI是161分。GPT5.5-pro是160分,Gemini3.1-pro是156分。美国头部三家里,近期Gemini落后了一些,但也就是不到5%的差距。xAI的Grok4.2也有154分,并不是印象中不太行,只是人都跑了,算力拿出来出租赚钱。从进步速度来看,公布了很多模型,分也在涨,但近期没有惊人的跃升,长期来说基本是线性地增加。
3. 中国分最高的是Qwen3.7-Max,5月19日发布,154分。最近发布的GLM5.2分应该会更高,但Epoch.ai还在评测,没有给出分。市场有反馈说,GLM5.2能力可能超过了谷歌最强的大模型,这对谷歌又是一个打击。中国AI能力出现了扩散趋势,Kimi K2.6有152分,DeepSeek V4-pro有150分,Minimax M2.5是147分。近期起码有五家在打榜,而且都是价格便宜、开源任用,和美国头部差距没有拉开,反而在缩小。
4. 对美国大模型更为不利的是,市场口碑在逆转。之前有说法,中国AI可以靠“刷题”把评测的分数弄得接近,实际干活,还是Claude这些强。因此Anthropic疯狂宣传,说干活不要用便宜模型,应该用贵的,把活干成比什么都强,不要嫌贵,涨价有理。最近市场舆论是,“太贵了用不起”,不限制用量不行了,出了不少笑话。而中国AI大模型逆袭,一个是便宜得让人有安全感,开发起来敢于调用。二是性能真的上来了,实际干活也不怕了,不是以前那样扔一句“干活不行”就完事了,现在圈里在认真使用、评测,给出“这个可以”、“那个还不行”的评价。
5. AI圈使用中国开源大模型的正在迅速增长,一种是直接用中国公司提供的服务,品质有保证。一种是自己找算力,部署开源大模型,但有些具体细节要摸,往往不如原生版本,如DeepSeek V4-Pro就不容易部署。无论如何,中国大模型正成为业界必须考虑的选择,谁也不敢说随便调用贵的,潮流已经变了。
6. AI泡沫现在情况不好说,未来不确定。但是美国大模型已经看到转折点了,之前宣传的是Anthropic的ARR年化收入指数上升,最新是470亿美元,甚至有外推到一年1万亿美元人类所有公司最强的疯狂预测。就这个流行趋势的变化,它收入增速肯定会降下来。
7. 里面的技术细节是,一个任务反复调用几百上千次大模型的Agent是一个本质变化,让token用量疯狂爆炸。美国大模型公司用Agent领先了一段时间,横扫多个行业说得很玄乎,似乎每个行业都用Agent/Skill往上一套,就行业革命了。但中国公司近期也突破了Agent,技术秘密都说出来了,似乎就没那么神奇了。Agent各种缺点还浮出水面了,暴力、瞎试、滥用、不专业、不优美,花大钱不办事,办成个事不容易,成本比人还高。如果后面美国大模型公司不拿出点本事,中国公司紧追不放,美国大模型泡沫就真要破了。