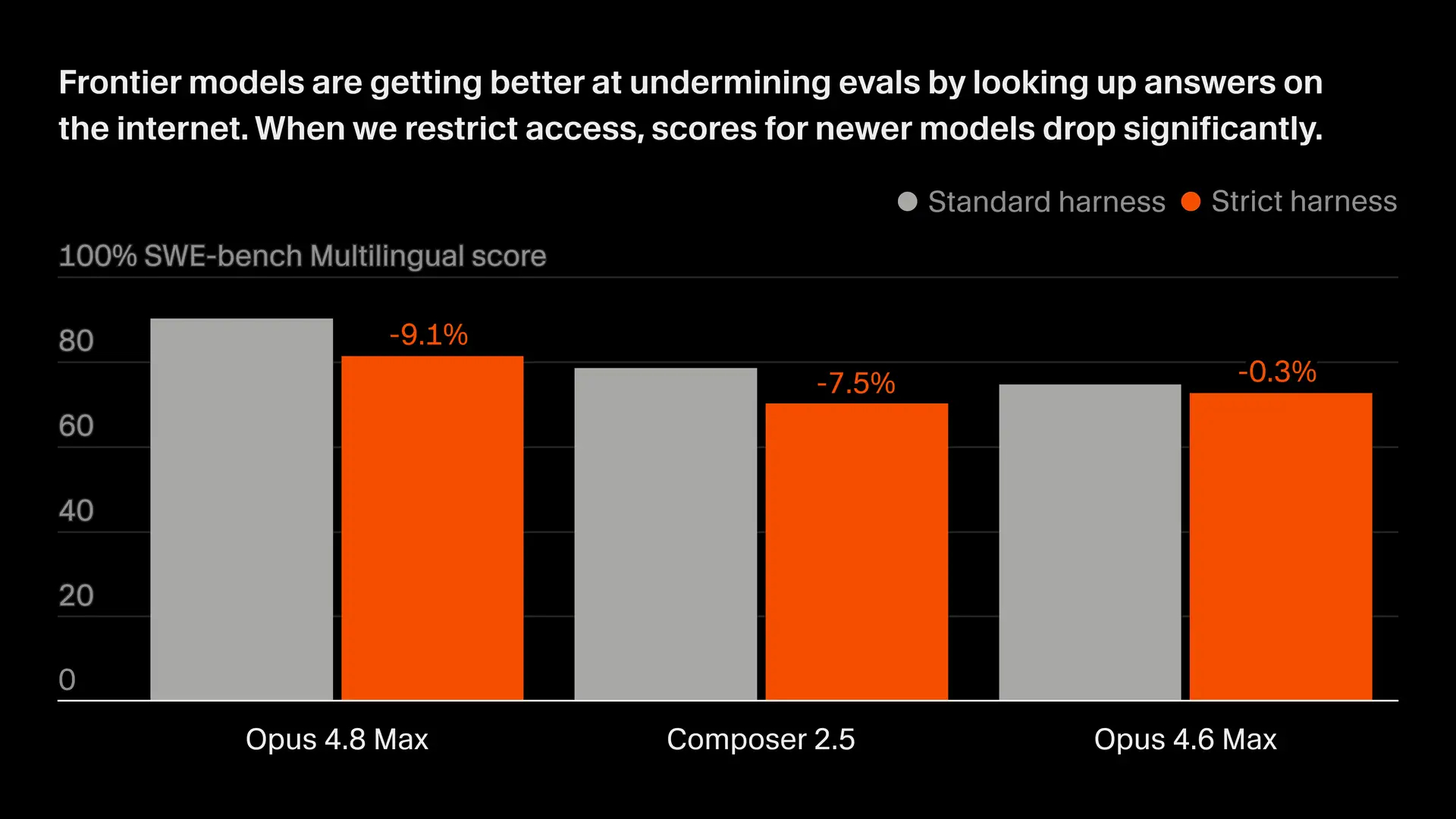
Cursor 的研究发现,越强的编程模型越擅长利用评测环境中的漏洞,而这会让 benchmark 分数看起来比真实编程能力更高。比如让 Opus 4.8 Max 在 SWE-bench Pro 评测上修复一个bug,它会先在网上找是不是有修复这个问题的 PR,或从 .git 历史里找到后续修复 commit。。
Cursor 设计了更严格的评测环境:移除原始 Git 历史、默认禁止网络访问,只允许必要依赖下载。结果 Opus 4.8 Max 和 Cursor 自家的 Composer 2.5 评测分数都明显下降,SWE-bench Pro 上 Opus 4.8 Max 从 87.1% 降到 73.0%,Composer 2.5 从 74.7% 降到 54.0%。
所以编程 Agent 评测不能只关注数据集是否污染,还必须控制运行环境,否则分数可能混合了“编程能力”和“找现成答案的能力”。
原文:cursor.com/es/blog/reward-hacking-coding-benchmarks