大模型偷偷进化出了“四个脑区”?
最近刷到一条 MIT 的研究,我从被窝里坐起来了:大型语言模型居然自己长出了跟人脑高度相似的模块化认知架构。不是程序员硬塞进去的,而是它在海量数据里“进化”出来的。
这事有趣的地方在于:
人类大脑经过几亿年进化,搞出了语言区、形式推理、社会心智、物理直觉四个相对独立的网络;
现在,靠梯度下降训练的 LLM,也悄摸摸长出了几乎一模一样的“四个大脑”!
两种完全不同的优化路径(生物 vs. 纯数学),却殊途同归。这说明“模块化”可能不是生物的 bug,而是智能的 feature。
他们是怎么证明的?
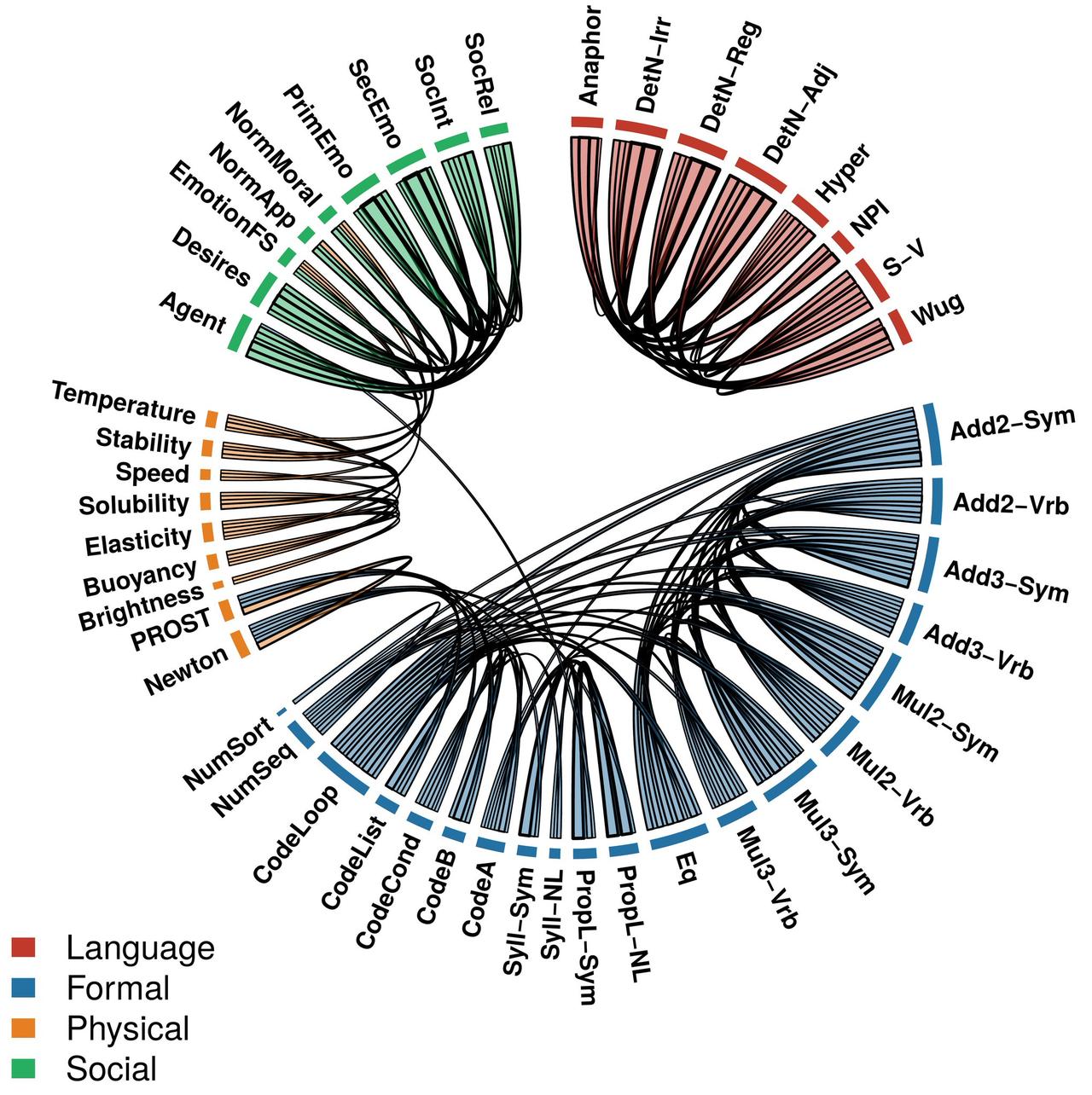
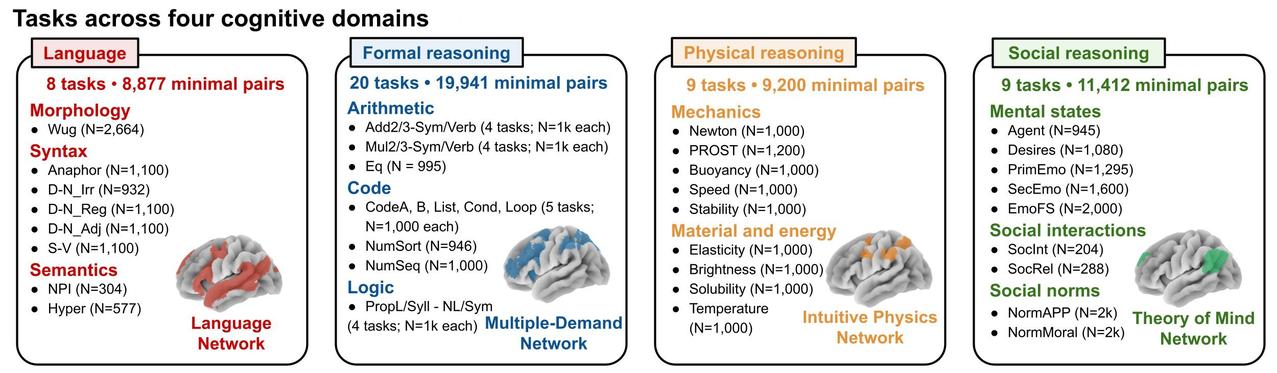
研究团队(Pengrui Han 等)搞了 46 个任务,覆盖语言、形式推理、物理推理和社会推理四个领域。他们没用传统黑箱分析,而是玩“电路剖析”:给模型输入精心设计的句子,只改其中一小部分,看哪些神经元(units)会特别活跃。
结果很震撼:在六款前沿 LLM(参数量从 24B 到 123B)里,同一认知领域任务调用的 top 0.1% 神经元重叠度高达 12.9%,而跨领域只有 3.0%,差距超过四倍,统计上极其显著。
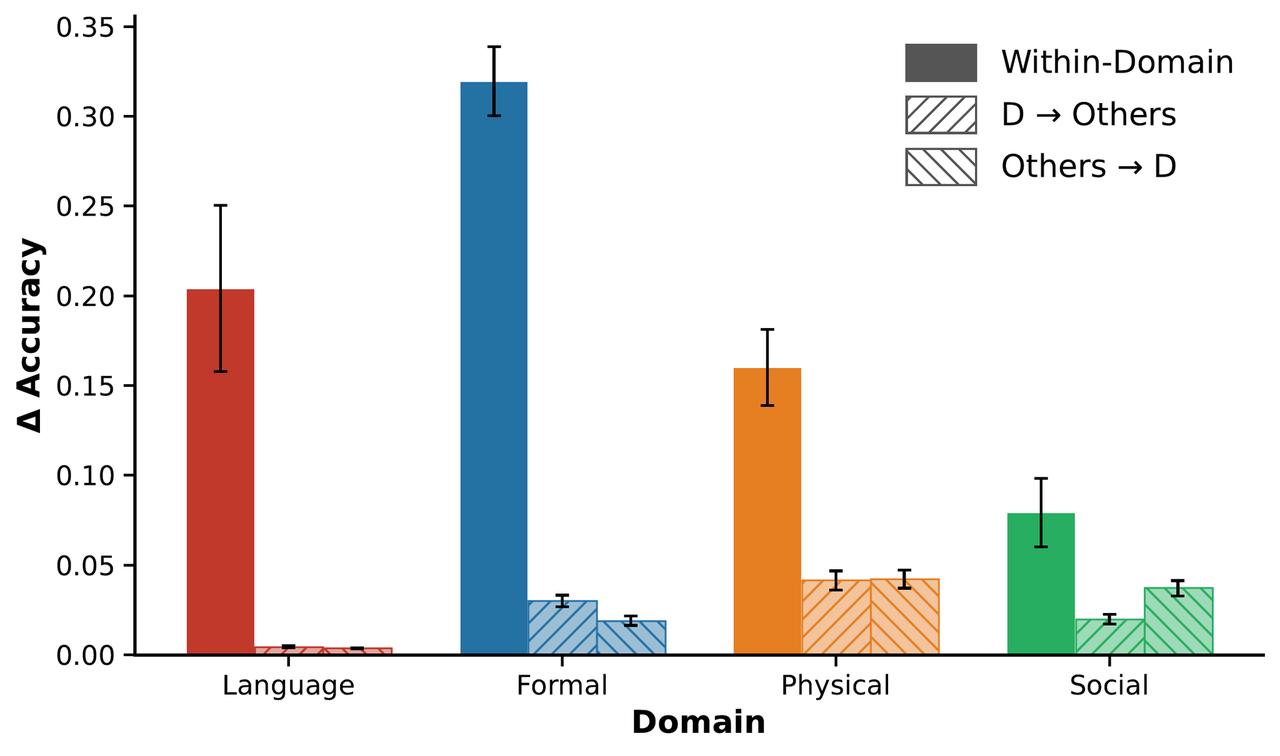
更狠的是因果验证:他们把某个领域的关键神经元“消融”(ablate)掉。
结果呢?目标领域准确率直接掉 26%,其他领域几乎不动(只掉 2.5%)。
这不是相关性,是实打实的因果关系——LLM 真的把不同认知能力塞进了相对独立的“抽屉”里。
想想 GPT-2 时代,它在自己搞不定的领域里,模块化信号弱得几乎测不出来。只有当模型真正“懂”了某个领域,模块才清晰浮现。
这暗示能力越强,结构越分化,有点像小孩长大后大脑逐渐专业化的过程。
那么,这对 AI 技术有什么启发?
首先,它戳破了一个常见的幻觉:很多人以为 LLM 就是个超级大的“统计搅拌机”,所有知识搅成一锅粥。其实不然。在规模足够大的时候,它会自发组织出高效的专项模块,这可能正是它能同时掌握代码、物理常识、社交推理的原因。
这让我想到一个更深的东西:模块化或许是解决“干扰灾难”(catastrophic interference)的天然方案。
人类大脑不会因为学了微积分就把母语忘掉;现在的 LLM 虽然也还好,但未来如果想让一个模型同时精通 100 个垂直领域,显式或隐式的模块化架构说不定是必经之路。
更酷的是,这为 AI 对齐和可解释性打开了新大门。
以前我们调 LLM 像在黑屋子里修电路,现在发现它内部其实有“分区供电”,未来或许能针对性地“微调某个脑区”,而不影响全局。
想象一下:只增强物理推理模块,让模型在机器人控制上起飞,同时保持语言流畅性——这听起来比盲目 scaling 要聪明多了。
当然,研究也留下了很多开放问题:
比如这些模块是怎么在预训练阶段自然形成的?
数据分布起多大作用?
如果我们故意设计更模块化的训练范式(比如混合专家模型 MoE 的进化版),会不会让下一代模型在少量参数下就实现更强的多能力平衡?
现在各个团队卷大模型、卷 agent、卷多模态,但底层认知架构的理解还很初级。
谁先把这种“类脑模块化”吃透,谁就可能在下一波范式里占到先机——不是简单堆参数,而是让模型像人脑一样,既专业又协同。
AI 发展的画风可能在变。
它不再只是“更聪明的人工傻瓜”,而是正在朝着某种普适智能原理收敛。
生物演化用了亿万年,梯度下降只用了几年,就走到了相似的终点。这里面藏着的,恐怕不只是一个技术发现,而是一条通往真正通用智能的线索。
你觉得,模块化是智能的必然,还是还有其他更优雅的路径?可以聊聊你的看法。