如果强迫它“闭嘴”,要求其在单次前向传播(Forward Pass)中直接在潜在空间内融会贯通知识并隐式生成最终答案,哪怕是顶尖的 Transformer 模型也常常陷入泛化失效的困境。
UC伯克利和普林斯顿的研究员(包括 Stuart Russell、Jason D. Lee 等大牛)发布了新作 《DiscoLoop》,彻底揪出了这个导致隐式推理失败的底层瓶颈!
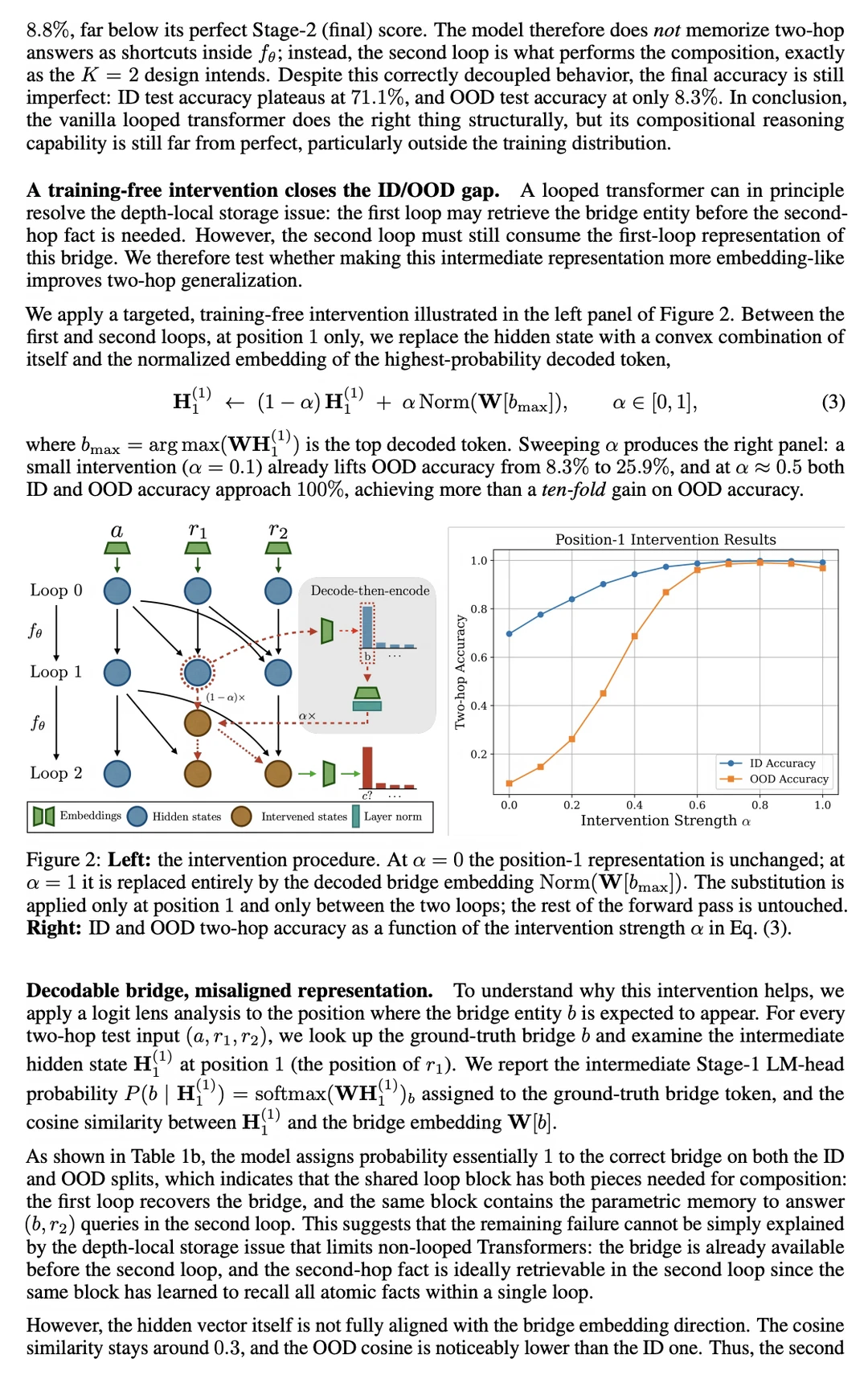
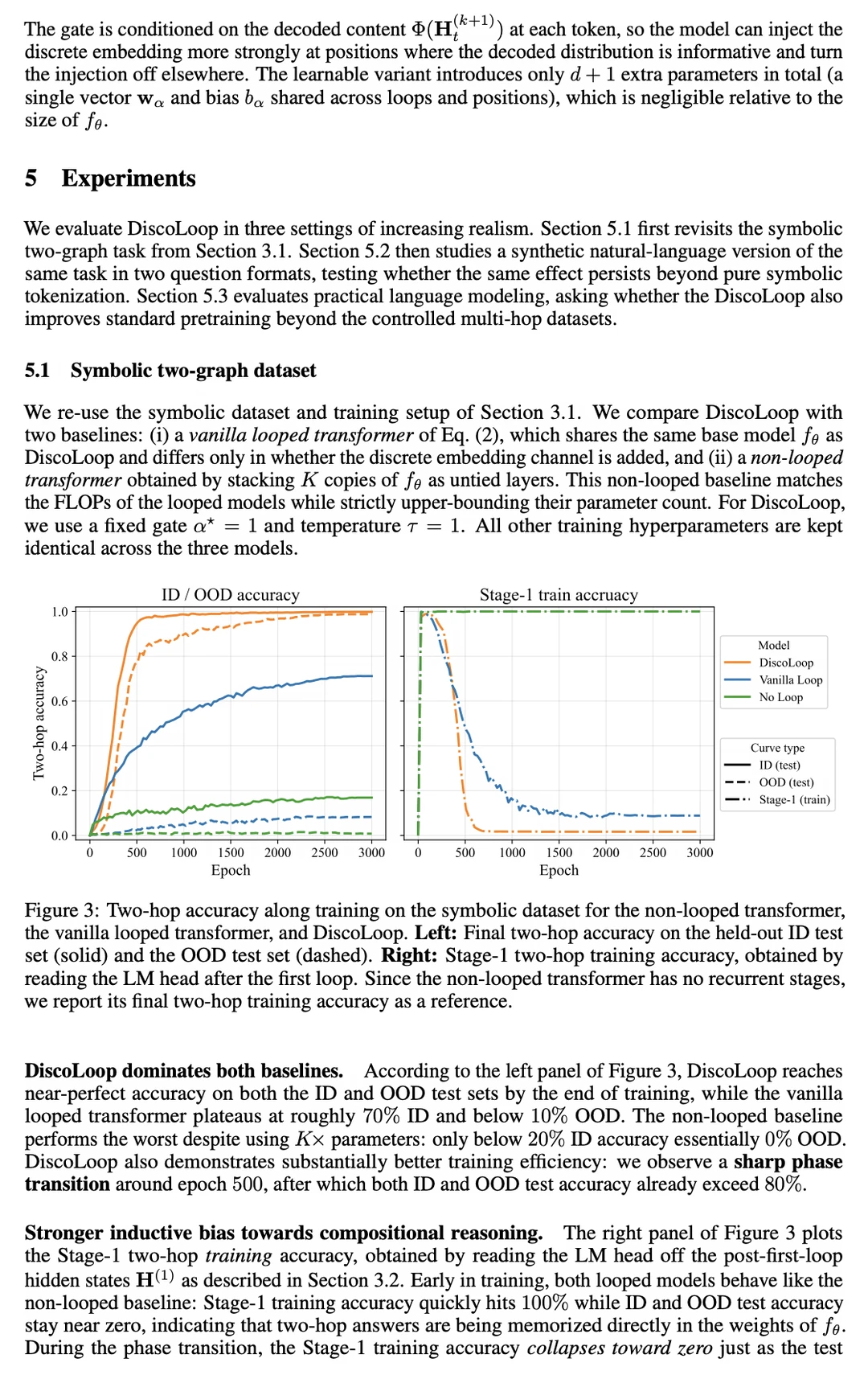
团队进行了深入的机制可解释性分析(Mechanistic Analysis),发现了一个惊人的事实:模型在进行第一轮循环迭代时,其实已经 100% 精准锁定了中间桥梁实体。
但问题是,首轮循环输出的连续隐藏状态携带了大量噪声且方向处于低饱和状态。
到了第二轮循环,模型被迫直接消费这个高噪的连续潜在表征,导致其与模型参数中固化的干净、离散的 Token 嵌入(Embedding)产生了严重的几何错位。
学者们给出的解法极其优雅——既然表征失真,那就双通道协同!
他们设计了全新的 DiscoLoop 架构:在循环深度迭代中,除了保留传统的连续隐藏状态通道外,并排引入了一个离散嵌入通道。
在两轮循环的间隙,模型通过输出头(LM Head)进行软解码与再编码(Soft Decode-then-Encode),动态地将标准、干净的 Token 嵌入残差流中进行融合,注入下一轮循环。
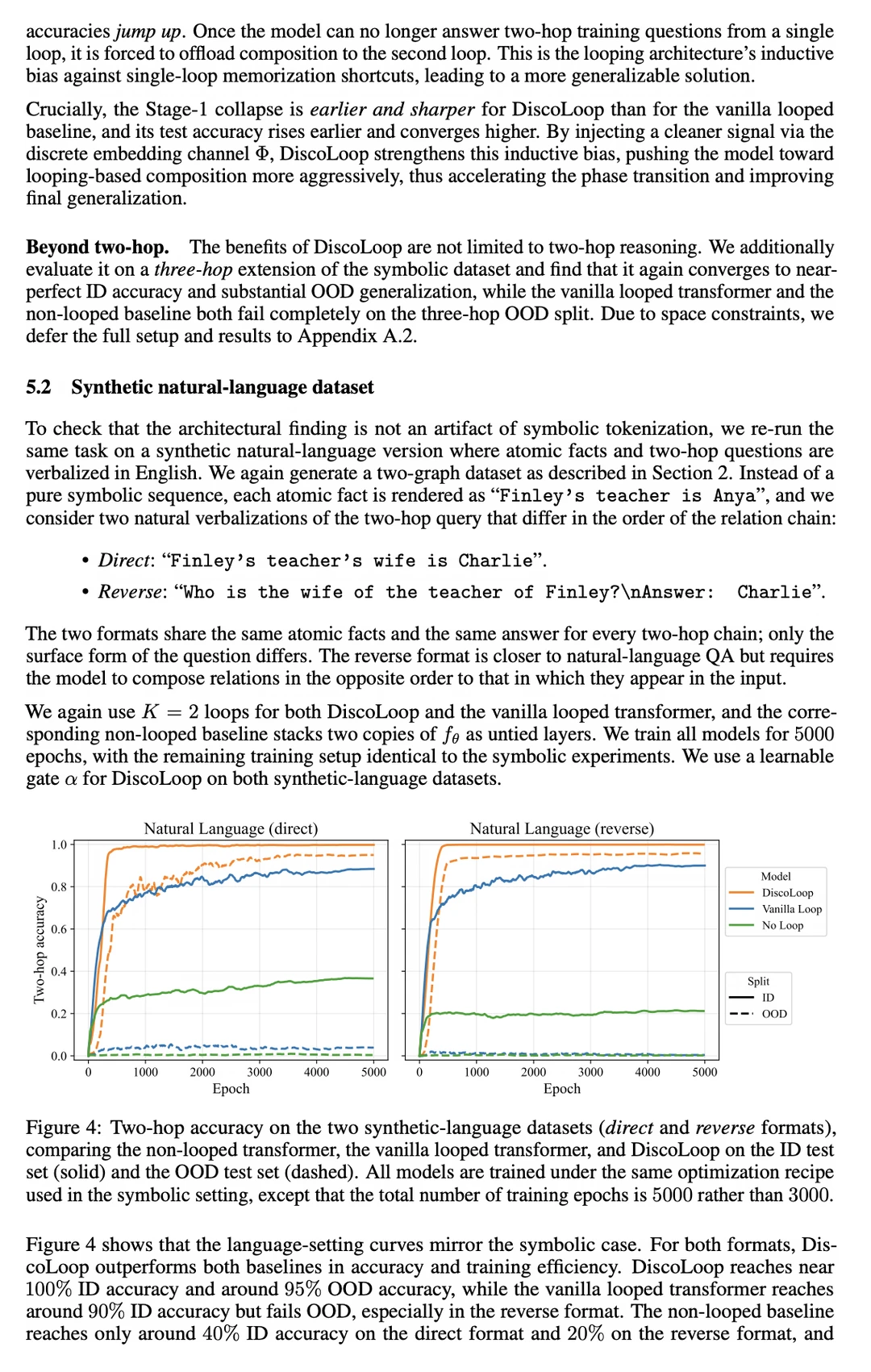
在极其严苛的分布外多步推理测试中,传统模型正确率不足 10%,而 DiscoLoop 凭借双通道设计斩获了近乎 100% 的准确率。
同时,在真实的 20B Token 通用语言模型预训练中,它不仅取得了更低的训练损失,还在 ARC、LAMBADA、SciQ 等标准基准测试中全面超越主流循环基线模型。
未来的大模型无需盲目堆砌上下文 Token 进行自我碎碎念,在潜在空间内就能优雅且高能效地进行深度计算。
搞大模型架构、潜在推理(Latent Reasoning)或者在实际业务中饱受 CoT 延迟与 Token 成本折磨的朋友,这篇论文强烈推荐加入必读清单!