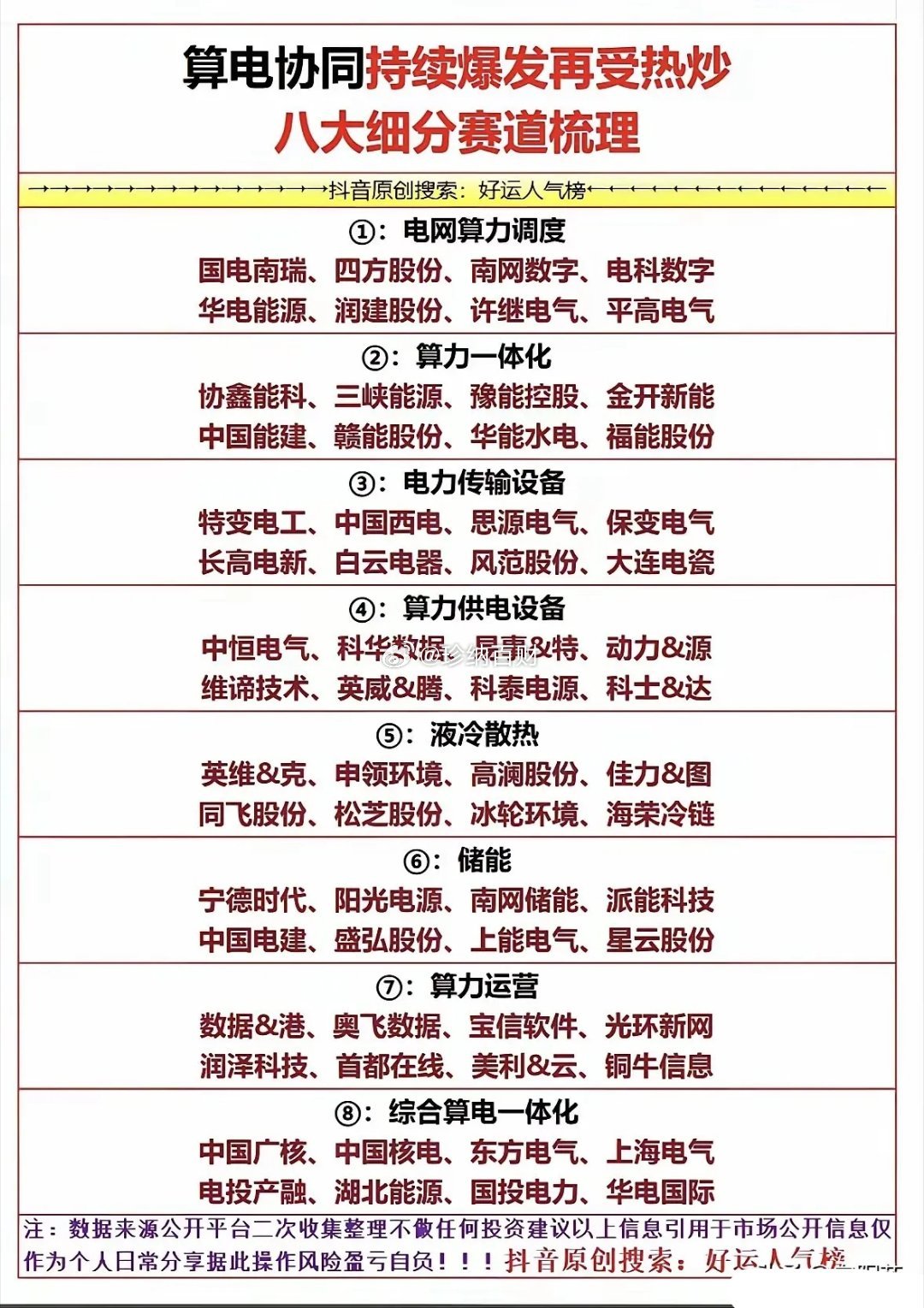
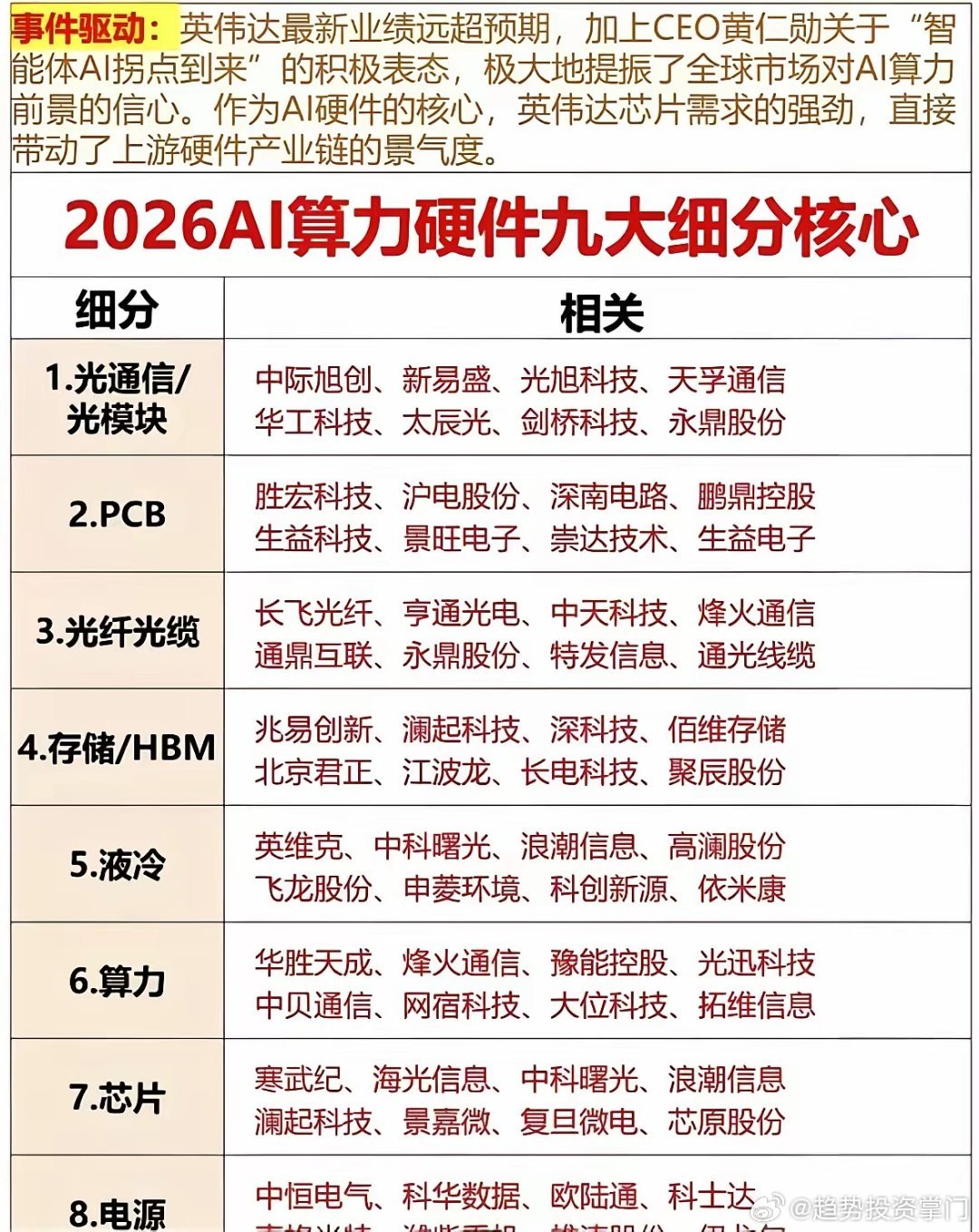
标签: it芯片



哈工大这回算是把天捅破了!谁都没想到,麒麟9020芯片只是个幌子,真正让美国和台
哈工大这回算是把天捅破了!谁都没想到,麒麟9020芯片只是个幌子,真正让美国和台积电气得手抖的,是牌桌底下那场早已开始的技术暗战,全球格局,恐怕要被彻底改写了。最近这两年,麒麟9020几乎承包了半导体圈的热度,作为华为首款支持5G-A的SOC芯片,它用7纳米工艺实现了性能的大幅提升,搭载它的手机一经发布就被抢购一空,不少人都以为,这就是中国半导体突破美国封锁的终极杀招。但很少有人注意到,麒麟9020的风光背后,藏着哈工大不声不响的布局。这款芯片固然厉害,可它本质上还是基于现有工艺的优化升级,真正能打破僵局、让美国和台积电坐不住的,从来都不是这一款成品芯片,而是哈工大在芯片核心设备上的突破性进展:极紫外光源技术。咱们说得通俗点,芯片制造就像在指甲盖大小的地方雕刻精细花纹,而极紫外光源,就是雕刻用的“手术刀”,没有它,高端光刻机就是一堆废铁,更别提生产7纳米以下的先进芯片了。长期以来,这项核心技术一直被美国和荷兰ASML垄断,他们用激光产生等离子体的路径,不仅设备庞大、造价高昂,还牢牢攥着专利壁垒,故意不给中国提供相关技术和设备,就是想把我们的芯片产业锁死在中低端。而哈工大偏偏不走寻常路,从2008年就开始默默摸索,避开了美国的专利陷阱,选择了放电等离子体的新路径,硬生生搞出了13.5纳米波长的极紫外光源——这正是高端光刻机最需要的核心部件。更关键的是,哈工大的这个技术,能量转换效率更高,设备体积更小,造价也低了不少,相当于用更经济的方式,打通了高端芯片制造的“命脉”。从2022年推出样机,到2023年完成原型机研发,再到2024年上半年通过关键测试,哈工大的团队用十六年的坚守,完成了从无到有的突破。美国一直靠着技术封锁,打压中国半导体产业,甚至把哈工大列入制裁名单,连国际顶级学术会议都不让哈工大的学者投稿,就是怕哈工大搞出颠覆性技术。可他们没想到,哈工大不仅没被打垮,反而在暗处完成了逆袭,直接戳破了美国的光源卡脖子难题。而台积电的焦虑,其实比美国更甚。作为全球芯片代工的“领头羊”,台积电之所以能垄断高端芯片代工市场,核心就是靠ASML的EUV光刻机,靠美国的技术支持。这些年,台积电一边依赖美国的技术封锁,一边靠着苹果、高通等巨头的订单赚得盆满钵满,甚至已经实现了2纳米制程的量产。可一旦哈工大的极紫外光源技术成熟,中芯国际就能减少对ASML设备的依赖。当然,我们也得清醒地认识到,哈工大的突破只是第一步。一台完整的EUV光刻机,除了光源,还需要反射镜、掩膜台、晶圆台等众多核心部件,这些还需要国内其他单位协同发力。但不可否认的是,哈工大的这次突破,已经打破了美国的技术垄断,为中国半导体产业链的闭环打下了坚实基础。以前,美国总说我们和世界领先水平差10到15年,说芯片技术是靠时间和金钱砸出来的,可他们忘了,中国的科研工作者最不怕的就是坚守和攻坚。哈工大的团队用十六年的时间证明,只要我们找准方向、默默深耕,就没有破不了的技术壁垒。这场技术暗战,从来都不是单一企业、单一高校的战斗,而是整个中国半导体产业的协同作战。哈工大的突破,不仅让美国的封锁计划落空,更让全球半导体格局迎来了拐点。未来,随着国产光刻机的逐步落地,中国不仅能摆脱被“卡脖子”的困境,还能在全球芯片产业中拥有更多话语权,曾经由美国和台积电主导的游戏规则,终将被我们改写。现在再回头看,麒麟9020的风光,更像是一个信号——它告诉世界,中国半导体的突破,从来都不是偶然,而是我们多年积累的必然。而哈工大这场藏在牌桌底下的技术暗战,才刚刚揭开序幕,未来,还有更多惊喜在等着我们。














吹了半天的苹果M5芯片,结果到手一看,连个Ollama都跑不了,当时心里那股火真
吹了半天的苹果M5芯片,结果到手一看,连个Ollama都跑不了,当时心里那股火真是往上直冲。买它本来就是奔着本地AI能力去的,结果装上之后报错不断,去GitHub上一瞅,好家伙,全是抱怨M5和Metal框架不兼容的。这哪是生产力工具,简直是个昂贵的摆设。后来不死心,拿公司的Linux电脑试了试,虽然能跑,但那运行速度慢得让人怀疑人生,简直是在给小模型“裹小脚”。看着屏幕上那点儿蹦出来的字儿,我当时就在想:所谓的“本地AI时代”真的靠谱吗?还是说我们只是被厂家画的一张大饼给忽悠了?这还没完,现在除了等官方更新,用户根本一点辙都没有。花了大价钱买的新玩意儿,核心功能竟然成了“半成品”,这种落差感谁懂啊。真不是我吐槽,现在的硬件迭代速度是快,可这软件适配能不能走点心?别让消费者成了你们测试代码的小白鼠。大家说,现在的小模型除了能聊聊天、写点打油诗,到底还有啥实在用处?这玩意儿折腾半天,真值得我们投入这么多精力吗。

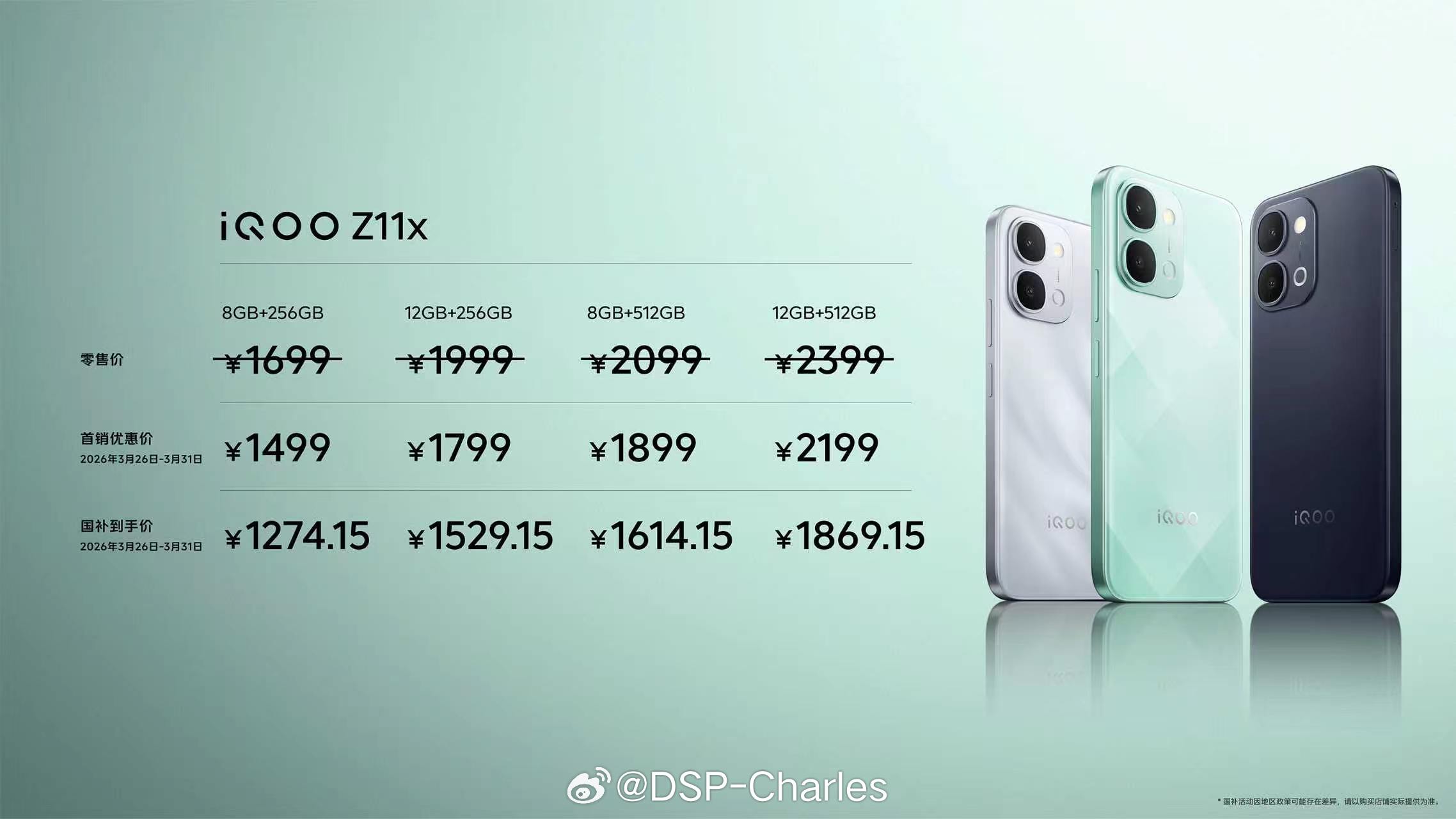















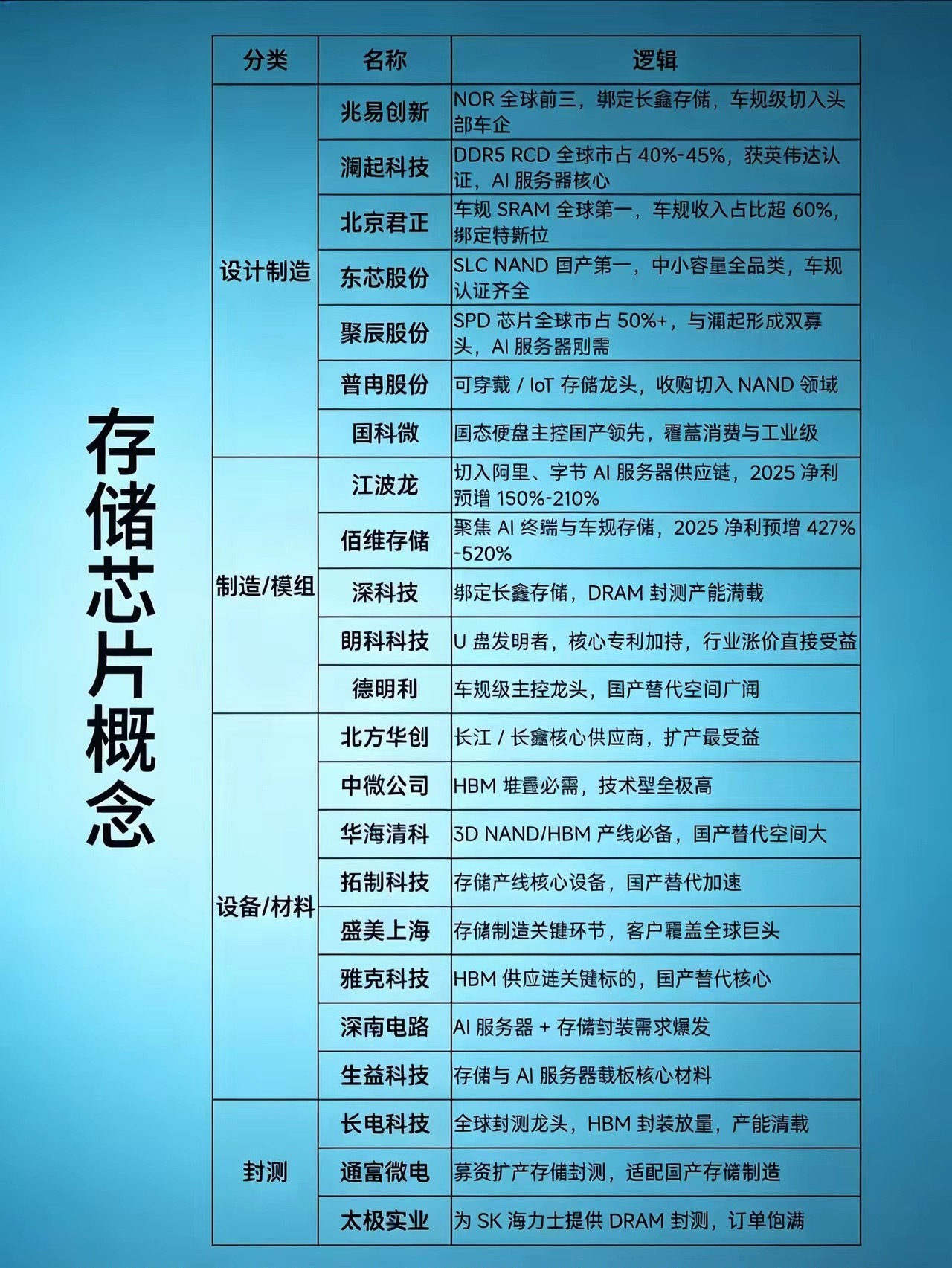
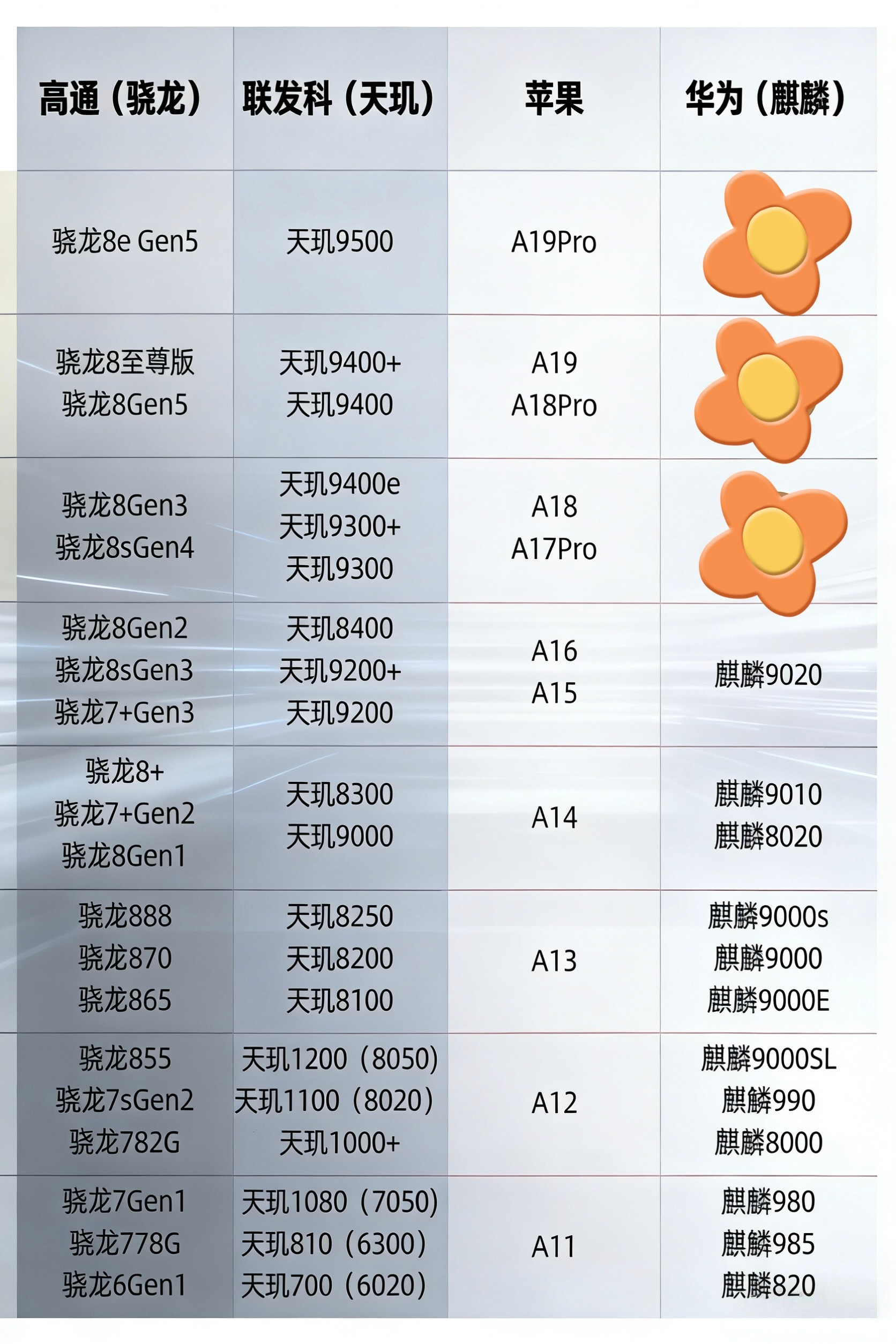




华为麒麟芯片到底有多强?这张图展示了9000系列的主流型号!从9010到9030
华为麒麟芯片到底有多强?这张图展示了9000系列的主流型号!从9010到9030Pro,核心数越来越多,架构越来越先进。虽然制程工艺受限,但凭借优秀的架构设计,性能依然能打。泰山大核负责高性能任务,小核省电处理日常,GPU图形处理能力也在不断升级。每一代芯片都是国产技术的突破,支持5G、AI算力强劲。在重重封锁下还能迭代出这么多款芯片,实属不易。支持国产芯,就是支持中国科技的未来,为华为点赞!




有人问我,英伟达到底凭什么这么值钱?我说,你去看CUDA就明白了。CUD
有人问我,英伟达到底凭什么这么值钱?我说,你去看CUDA就明白了。CUDA是2006年英伟达推出的一套编程平台,就是让程序员能用GPU运行各种计算,就这么个东西,现在成了整个AI行业的命门,几乎所有大模型都运行在上面。为什么别人绕不开它?有四道墙。第一道墙,是开发者,全球超过400万开发者基于CUDA写代码。这些人花了大量时间学习这套东西,写了大量代码,你让他们换到AMD的ROCm?他们宁可多花钱买英伟达,也不想重来一遍。这不是技术问题,这是人的问题。第二道墙,是软件库。英伟达这些年攒了一堆现成的工具:TensorRT负责推理加速,cuDNN专门优化神经网络,NCCL搞定多卡通信。这些库都是跟英伟达的硬件深度绑定优化的,换块AMD的卡,你得重新验证每一个库的表现,费时费力,结果还不一定效果好。第三道墙,是迁移成本,一家公司的AI模型如果基于CUDA开发,换平台不只是改几行代码就可以了,团队要重新培训,文档要重新写,踩过的坑要重新踩一遍。这笔账算下来,很多公司直接放弃,乖乖续费买英伟达的卡。第四道墙,是时间。英伟达搞CUDA将近二十年了,AMD的ROCm才刚起步,哪怕其他厂家每年进步30%,追上也要七八年。AI行业哪等得了那么久。当然,CUDA的护城河也不是铁板一块。谷歌早就在用自己的TPU运行内部任务,Meta、OpenAI也在用AMD的卡做部分工作负载。PyTorch现在加了编译器层,理论上可以让代码不那么依赖底层芯片。但这些裂缝,还远没有变成缺口。真正能撼动英伟达的,不是哪家芯片公司做出了更快的硬件,而是整个行业攒出了一套足够好用的"翻译层",让代码不用改就能在任何芯片上完美运行。在那之前,英伟达还是老大